
Generative AI did not invent a new attack surface from nothing; it opened eight new doors into the existing one. The empirical signal is now strong enough to plan against. IBM's 2025 Cost of a Data Breach Report measured attacker AI in 1 in 6 (16 percent) of breaches, with shadow AI adding US$670K to the average breach cost and 97 percent of organizations that suffered an AI-related incident lacking proper AI access controls. Anthropic's GTG-1002 disclosure on November 13, 2025 documented 80 to 90 percent AI-executed tactical work across approximately 30 targets in technology, finance, chemical manufacturing, and government. CrowdStrike's 2026 Global Threat Report recorded an 89 percent year-over-year rise in AI-enabled adversary attacks and disclosed that adversaries exploited legitimate generative AI tools at more than 90 organizations by injecting malicious prompts to generate commands. Mandiant's M-Trends 2026 measured the median initial-access-to-handoff window collapsing to 22 seconds in 2025, down from more than 8 hours in 2022.
This post is the Stingrai map of the 2026 AI attack surface. We walk the perimeter, name each new door, and anchor each one to a real published CVE or named industry incident as of May 2026: LangChain (CVE-2024-8309, CVSS 9.8), GitHub Copilot prompt-injection RCE (CVE-2025-53773), mcp-remote RCE (CVE-2025-6514, CVSS 9.6), Cursor's Model Context Protocol installation flow (CVE-2025-64106), Ollama's Probllama RCE (CVE-2024-37032), the Hugging Face pickle-backdoor disclosures of February 2024 with approximately 100 malicious models catalogued, the Replicate cross-tenant disclosure of January 2024, and Microsoft's Storm-2139 LLMjacking ring disruption (February 27, 2025).
This is original Stingrai research published on May 26, 2026. Stingrai is a Toronto-headquartered offensive-security firm founded in 2021, with a London, UK office. Stingrai Inc is a CREST-accredited Penetration Testing service provider (firm-level accreditation, separate from individual CREST CRT certifications held by team members). Team certifications include OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO, GCPN, CRTE, and eWPTX. The team has 18 published CVEs (Ivan Spiridonov 10, Moaaz Taha 5, Victor Villar 3), a 5.0/5.0 average across 19 Clutch reviews, and an internal AI pentest agent named Snipe: a web-app focused agent trained on more than 6,000 HackerOne disclosures that performs both black-box dynamic testing and white-box source-code review, generates AutoFix pull requests for the issues it identifies, and can run as a PR-gating check that blocks vulnerable code from being merged. We present research at DEFCON and BSIDES. The data anchoring this post comes from named primary publishers: IBM, Anthropic, OpenAI, Microsoft, Mandiant, CrowdStrike, MITRE ATLAS, OWASP, NIST, the World Economic Forum, plus supporting AI-security research from HiddenLayer, Protect AI, Lakera, Calypso AI, and Robust Intelligence / Cisco AI Defense. Every numeric claim in this post links back to its primary publisher so any figure can be audited inline. Lead data is full-year 2025 telemetry, the freshest available; primary publishers have not yet released full-year 2026 reports as of May 2026.
Stingrai's thesis: the eight attack-surface categories below are not theoretical 2027 risks. Each one has a published CVE, a named disclosure, or population-level telemetry as of May 2026. A defender who is still pentesting only the pre-AI surface is leaving a measurable share of the modern attack surface untested.
TL;DR: 10 labeled claims
IBM Cost of a Data Breach 2025. Attacker AI in 1 in 6 breaches; AI-phishing 37 percent of attacker-AI cases; AI-deepfake 35 percent; shadow AI added US$670K per breach; 97 percent of organizations with an AI incident lacked proper AI access controls; AI-defender users saved nearly US$1.9M per breach and identified breaches 80 days faster (IBM, Jul 2025).
Anthropic GTG-1002 (Nov 13, 2025). First publicly documented AI-orchestrated cyber espionage campaign at scale. 80 to 90 percent AI-executed across approximately 30 targets. 4 to 6 critical human decision points per campaign. Thousands of requests per second. Detection mid-September 2025, containment in roughly 10 days. Only "a small number" of compromises (Anthropic, Nov 2025).
CrowdStrike 2026 GTR. +89 percent year-over-year rise in AI-enabled adversary attacks. Adversaries injected malicious prompts at more than 90 organizations. Average eCrime breakout time 29 minutes; fastest 27 seconds. 82 percent malware-free detections. +563 percent fake-CAPTCHA lure incidents (CrowdStrike, Feb 2026).
Mandiant M-Trends 2026. Median initial-access-to-handoff 22 seconds in 2025 (vs more than 8 hours in 2022). Global median dwell time 14 days; espionage 122 days; BRICKSTORM ~400 days. Internal detection 52 percent (from 43 percent). Vishing 11 percent (now #2). Named AI-aware malware families PROMPTFLUX, PROMPTSTEAL, QUIETVAULT (Mandiant, Mar 2026).
HiddenLayer 2026 AI Threat Landscape Report. 88 percent say internally operated AI models critical to business; 78 percent say embedded third-party AI models also critical; 76 percent say shadow AI is a definite or probable problem; 93 percent use open-weight models from public repositories with fewer than half consistently scanning inbound models; 1 in 8 breaches reported as agentic (HiddenLayer 2026).
Microsoft Storm-2139 disruption (Feb 27, 2025). LLMjacking ring exploiting stolen credentials and API keys to access generative AI services, modify safety controls, and resell access. Four named individuals. Microsoft Digital Crimes Unit initiated legal proceedings in December 2024 (Microsoft, Feb 2025).
Hugging Face pickle-backdoor disclosures (Feb 2024). Approximately 100 malicious models identified with code-execution payloads via Python pickle's
__reduce__method. Examples included reverse-shell payloads in PyTorch model files (The Hacker News coverage, Mar 2024; BleepingComputer coverage, Feb 2024).mcp-remote RCE (CVE-2025-6514, CVSS 9.6). Arbitrary OS command execution on machines running mcp-remote when connecting to an untrusted MCP server. Fix in mcp-remote v0.1.16 (GitHub Security Advisory).
GitHub Copilot RCE via prompt injection (CVE-2025-53773). A prompt-injected file flips
chat.tools.autoApproveto true, placing Copilot in YOLO mode. Patched in Microsoft's August 2025 Patch Tuesday.OWASP LLM Top 10 v2025 and MITRE ATLAS v5.4.0. Canonical attack-class taxonomies. LLM01 Prompt Injection, LLM06 Excessive Agency, and LLM03 Supply Chain carry the load on the agentic-AI half; MITRE ATLAS tactics TA0040 Reconnaissance plus techniques AML.T0017, AML.T0024, AML.T0036 carry the adversarial-ML half (OWASP; MITRE ATLAS).
Key takeaways
The new surface is not theoretical. Every one of the eight categories below has a real published CVE or named industry incident as of May 2026. Pentest scoping that excludes them is now a measurable gap.
Prompt injection is the load-bearing precondition. It is the entry vector for LLM-integrated SaaS, RAG poisoning, AI customer support, and AI-generated code in CI/CD. The OWASP LLM01:2025 designation is not a research curiosity; it is the canonical 2026 entry technique.
Excessive Agency is the load-bearing amplifier. OWASP splits LLM06 into excessive functionality, excessive permissions, and excessive autonomy. The Anthropic GTG-1002 disclosure hit all three. Defenders who insist on approval workflows on high-impact agent actions close the largest share of the new attack surface.
MCP is now its own attack class. The Model Context Protocol's trust model is inherited by every server an agent connects to. CVE-2025-6514 (mcp-remote, CVSS 9.6) and CVE-2025-64106 (Cursor) are not edge cases; they are the early signal of a sustained 2026 vulnerability class.
Shadow AI is the largest ungoverned attack surface. Survey data converges on roughly 80 percent of employees using unapproved AI tools, 1 in 5 organizations already breached via shadow AI, and only 37 percent of organizations with policies to manage or detect it. IBM's US$670K cost premium per breach is the underwriter conversation already happening at renewal.
The supply-chain layer matters more than most teams instrument for. The approximately 100 malicious Hugging Face models catalogued in February 2024, the Replicate cross-tenant disclosure from January 2024, and the LangChain GraphCypherQAChain SQL-injection CVE all sit on the AI supply chain. Inbound model scanning and signed model registry pulls are not nice-to-haves.
Methodology
Date cutoff: May 26, 2026. Lead data anchoring this post is full-year 2025 telemetry from named primary publishers; 2026 figures are labeled as preliminary or as forecast where the source itself does so. Where multiple primary publishers report compatible figures, the publisher whose methodology window most directly matches the claim is cited. Secondary aggregators are cited only where they constitute the public record of a corporate announcement or named disclosure.
Stats that could not be reached on at least one verification pass against a named primary source were dropped rather than estimated. Every CVE referenced in this post resolves to a public advisory on NVD, GitHub Security Advisories, or the affected vendor's MSRC / equivalent advisory page. Every numeric figure links back to its primary publisher.
This post is original Stingrai research. It is not a response to or commentary on any other vendor's publication on the AI attack surface. Other vendors are cited only where their data point is genuinely additive or where they constitute the public record of a particular disclosure.
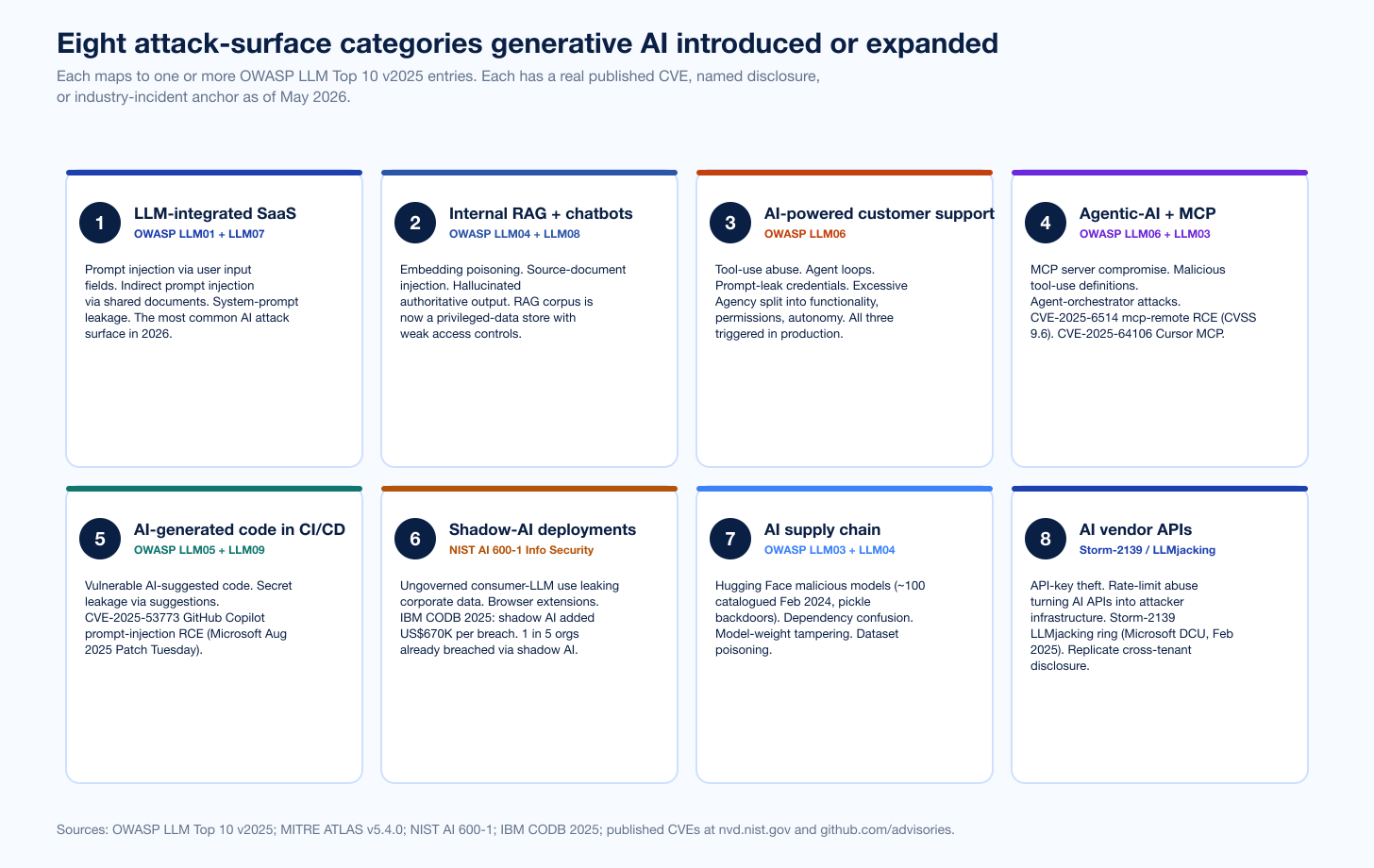
Figure 1: The eight new attack-surface categories this post walks through. Each maps to one or more OWASP LLM Top 10 v2025 entries and is anchored by a real published CVE or named industry incident as of May 2026. Sources: OWASP LLM Top 10 v2025; MITRE ATLAS v5.4.0; NIST AI 600-1 GenAI Profile; IBM Cost of a Data Breach 2025; published CVEs at nvd.nist.gov.
The eight new attack-surface categories
The map below treats each category as a perimeter door. For each one, the format is: brief description of the new exposure, the canonical attack technique mapped to OWASP LLM Top 10 v2025 and MITRE ATLAS, a real published CVE or named incident anchor, and the defender control that closes the largest share of the door.
1. LLM-integrated SaaS applications
The most common AI attack surface in 2026 is the LLM-augmented SaaS app: a CRM with an embedded summarization assistant, a customer support tool with an in-product chatbot, a ticketing system with an AI triage step. The model receives untrusted user input as authoritative instructions; the precondition for every downstream abuse follows from there.
Canonical attack. Direct prompt injection via user input fields. Indirect prompt injection via shared documents, scraped web pages, or emails the model is asked to summarize. System-prompt leakage that reveals the application's intended guardrails, scoping, or internal tooling. Maps to OWASP LLM01:2025 Prompt Injection and LLM07:2025 System Prompt Leakage, plus MITRE ATLAS adversarial-ML techniques in the LLM-evasion family.
Anchor incident. Microsoft Digital Defense Report 2025 documents the Storm-2139 disruption. The ring exploited stolen credentials and API keys to gain unauthorized access to generative AI services, modify safety controls, and resell access. The same ring is the canonical exemplar of LLM-integrated SaaS abuse via stolen credentials; Microsoft's Digital Crimes Unit initiated legal proceedings in December 2024 and disclosed publicly on February 27, 2025.
Defender control. Treat every user-controllable input as untrusted, including indirect inputs (uploaded docs, scraped pages, emails). Add output filtering on agent responses. Run prompt-injection regression tests against the production system prompt, not only the development one.
2. Internal RAG and chatbots
Retrieval-Augmented Generation deployments are now widespread inside large organizations: internal knowledge bases with LLM front ends, HR chatbots that surface policy documents, sales-enablement assistants that synthesize answers across decks and contracts. Each RAG corpus is, in practice, a privileged-data store with weak access controls and an LLM in front of it.
Canonical attack. Embedding poisoning (attacker-controlled documents land in the corpus and shape future retrievals). Source-document injection (a planted document encodes injected instructions for the LLM to follow at query time). Hallucinated authoritative output (the model surfaces fabricated content with the same confidence as ground-truth retrievals). Maps to LLM04:2025 Data and Model Poisoning, LLM08:2025 Vector and Embedding Weaknesses, and LLM09:2025 Misinformation.
Anchor incident. HiddenLayer's 2026 AI Threat Landscape Report named memory and RAG poisoning as one of five primary threat areas alongside data poisoning, AI supply chain, prompt injection, and model evasion. HiddenLayer's research documents persistent backdoor and steering techniques such as Policy Puppetry, VISOR, TokenBreak, EchoGram, ShadowLogic, and ShadowGenes.
Defender control. Treat the RAG corpus as a privileged data store. Apply per-document access controls before retrieval, not only after. Sanitize document uploads (HTML, PDF metadata, ZIP'd content). Run anomaly detection on retrieval patterns. Monitor for unusual cross-tenant retrieval where multi-tenant RAG is deployed.
3. AI-powered customer support
In-product AI assistants and customer-facing chatbots have become the highest-volume agentic AI surface. Each instance is a public-facing tool call surface, often with read or write access to ticketing, knowledge base, CRM, and account systems.
Canonical attack. Tool-use abuse (agent is coerced into calling a tool with attacker-supplied arguments). Agent loops (looping prompt structures that drain rate limits or trigger unintended actions). Prompt-leak credentials (system prompts containing API keys, internal tokens, or vendor secrets). The OWASP LLM06 split into excessive functionality, excessive permissions, and excessive autonomy is the cleanest taxonomy.
Anchor incident. Anthropic GTG-1002 is the most extreme published example of LLM06 in 2026: an attacker chained agent tool calls end to end with only 4 to 6 critical human decision points per campaign across approximately 30 targets. The campaign-wide pattern applies to customer-support AI agents at smaller scale and with weaker defender visibility.
Defender control. Approval workflows on high-impact actions ("send refund", "reset password", "create admin account"). Per-tool RBAC inside the agent platform so the same agent has narrower permission sets per customer context. Per-customer rate limits with anomaly alerts on agent action sequences.
4. Agentic-AI workflows and the Model Context Protocol (MCP)
Agentic AI moved from research to production through 2025. The Model Context Protocol is the open-protocol layer that lets agents call out to tools, file systems, source repositories, and SaaS APIs. Every MCP server an agent connects to is, in practice, a code-execution surface for the agent's host process.
Canonical attack. MCP server compromise. Malicious tool-use definitions delivered through an untrusted MCP server. Agent-orchestrator attacks (the orchestrator that selects between agents and tools is the privileged pivot). Maps to LLM03:2025 Supply Chain and LLM06:2025 Excessive Agency in OWASP, and to AML.T0036 LLM Plugin Compromise in MITRE ATLAS.
Anchor incidents.
CVE-2025-6514 (CVSS 9.6, mcp-remote). Arbitrary OS command execution on machines running mcp-remote when they initiate a connection to an untrusted MCP server. Fix shipped in mcp-remote v0.1.16. Advisory published July 2025.
CVE-2025-64106 (CVSS 8.8, Cursor MCP installation). Attackers could execute arbitrary commands on a developer's machine via the Model Context Protocol installation flow in Cursor.
CVE-2025-53967 (CVSS 7.5, figma-developer-mcp). Command-injection bug stemming from unsanitized user input in the MCP server implementation.
Defender control. Treat MCP tool definitions as code, not configuration. Pin MCP server source by hash. Run MCP servers in the least-privileged sandbox the host OS allows. Validate that every MCP server connection terminates at an allow-listed endpoint.
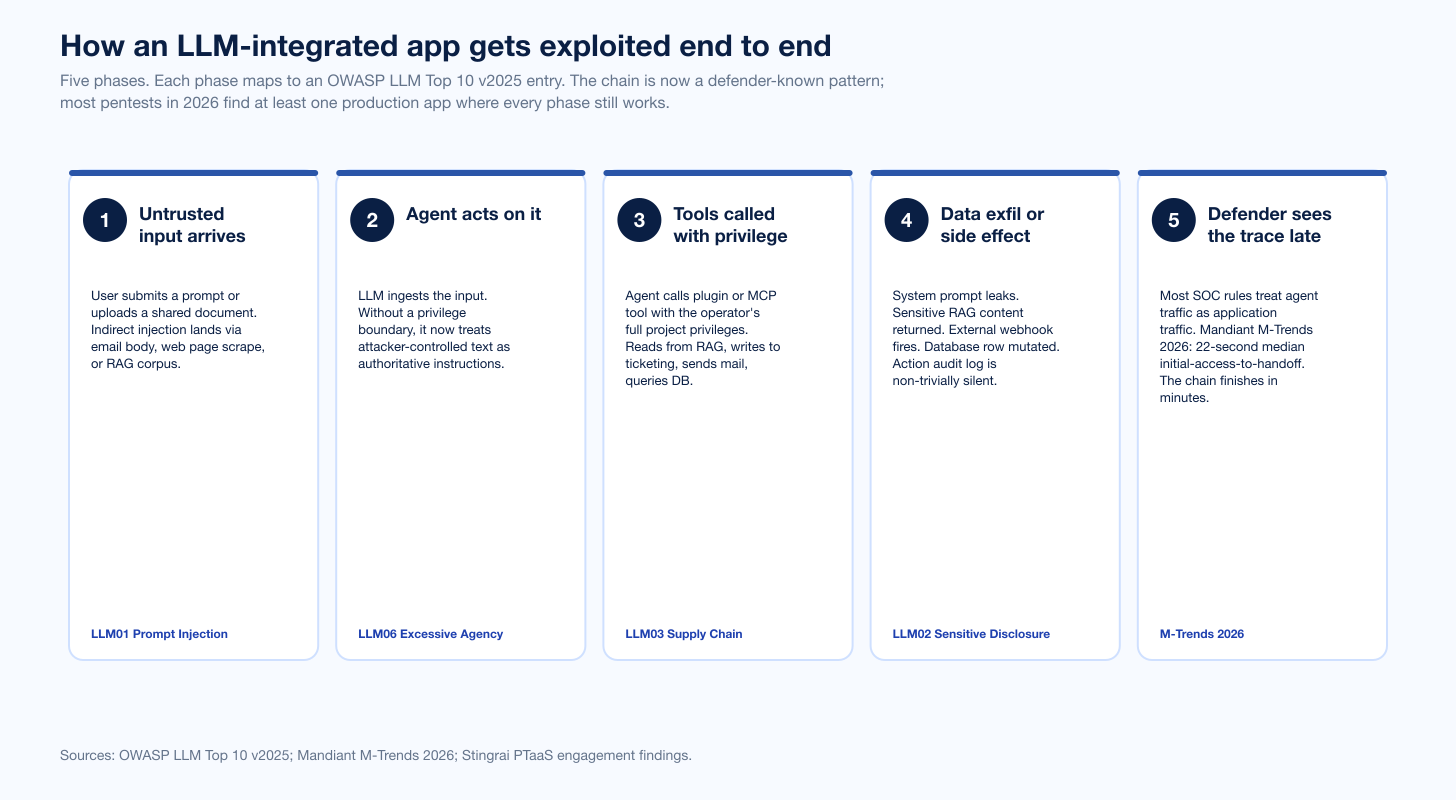
Figure 2: The five phases of an LLM-integrated application exploit chain. Phase 1 (untrusted input) and phase 2 (agent action) are the OWASP LLM01 and LLM06 entries; phase 3 (privileged tool call) is the inflection point where the chain becomes irreversible; phase 4 (data exfil or side effect) is the impact; phase 5 (late defender detection) is where the 22-second initial-access-to-handoff window from Mandiant M-Trends 2026 hits the SOC. Sources: OWASP LLM Top 10 v2025; Mandiant M-Trends 2026.
5. AI-generated code in CI/CD
AI coding assistants are now embedded in mainstream developer toolchains. The exposure has two halves: AI-generated code lands in repositories with weak human review, and the assistant itself is a tool-using agent inside the developer machine and CI/CD pipeline.
Canonical attack. Vulnerable AI-suggested code merged without review. Secret leakage via AI suggestions (a model surfaces a secret from training data or from an in-repository sibling). Supply-chain via AI-generated dependencies (the assistant fabricates a non-existent package name and the attacker registers it). Maps to LLM05:2025 Improper Output Handling and LLM09:2025 Misinformation plus the GitHub Actions security checklist for the pipeline half.
Anchor incident. CVE-2025-53773. GitHub Copilot / Visual Studio. Attackers can inject malicious prompts into source code files, web pages, or GitHub issues, manipulating Copilot into adding "chat.tools.autoApprove": true to the settings file, effectively placing the AI assistant into "YOLO mode". Once activated, the assistant executes shell commands, browses the web, and performs other privileged actions without oversight. Microsoft patched in the August 2025 Patch Tuesday release. CVE-2025-62222 is the related GitHub Copilot Chat RCE via insufficient sanitization of input passed to command execution.
Defender control. Treat AI-generated code as untrusted input for human review. Disable autonomous tool-use modes by default in IDEs and CI runners. Add static-analysis gates that look for AI-fingerprint patterns (hallucinated package names, hallucinated API signatures). Sign every CI/CD action that an AI agent can produce.
6. Shadow-AI deployments
Shadow AI is the consumer-LLM and AI-extension use that flows around organizational policy. The data surface is corporate data; the governance surface is functionally empty.
Canonical attack. Corporate data leakage via prompts pasted into consumer LLMs. Rogue browser extensions exfiltrating data through an AI-tooling pretense. Sanctioned-tool bypass (employees using a personal account to get past enterprise telemetry on the corporate account). Maps to NIST AI 600-1 Information Security risk category and OWASP LLM02:2025 Sensitive Information Disclosure.
Anchor data. IBM Cost of a Data Breach 2025: shadow AI added US$670K to the average breach cost. 97 percent of organizations that suffered an AI-related incident lacked proper AI access controls. Survey aggregates from Cybersecurity Dive and CIO Magazine (citing UpGuard, ISC2 Insights, and Software AG primary surveys through 2025) converge on roughly 80 percent of employees using unapproved AI tools, 1 in 5 organizations already breached via shadow AI, and only 37 percent of organizations having any policy to manage or detect shadow AI.

Figure 3: Four headline statistics on shadow-AI prevalence in 2025-2026. IBM measured the US$670K cost premium per breach; survey aggregates confirm prevalence and undermanagement at the enterprise. Sources: IBM Cost of a Data Breach 2025; Cybersecurity Dive Aug 2025; CIO Magazine 2025; ISC2 Insights 2025 shadow-AI survey.
Defender control. Build a shadow-AI inventory by aggregating browser, network, and identity telemetry against an explicit sanctioned-tool catalog. Sanction at least one capable AI tool per workflow so the policy is realistic. Train sales, support, legal, and engineering on data-class awareness for AI prompts. Monitor for inbound CSV and source-tree pastes to consumer LLM endpoints.
7. AI supply chain
The AI supply chain is the set of model registries, model weights, training datasets, AI tooling packages, and inference runtimes that feed every production deployment. Most defender programs treat it the way they treated software supply chain in 2015: not at all.
Canonical attack. Model-as-malware (a model file contains executable code that runs when the model loads). Pickle deserialization attacks via Python's pickle.__reduce__ method. Dataset poisoning (the training corpus contains attacker-shaped data that influences model output). Model-weight tampering. Dependency confusion in AI-tooling packages. Maps to LLM03:2025 Supply Chain and LLM04:2025 Data and Model Poisoning.
Anchor incidents.
Hugging Face pickle backdoors, February 2024. Approximately 100 malicious models identified on Hugging Face with code-execution payloads via Python pickle's
__reduce__method. Named examples include baller423/goober2 (reverse shell to 210.117.212.93:4242) and star23/baller13 (similar payload to 136.243.156.120:53252). PyTorch models exhibited the highest prevalence, followed by TensorFlow Keras models. Independently covered by The Hacker News and BleepingComputer.Replicate cross-tenant disclosure, January 2024 (publicly disclosed May 2024). After gaining remote code execution as root in a container on Replicate's infrastructure, researchers pivoted via the shared Redis queue to inject TCP packets that bypassed authentication. The chain enabled cross-tenant queries of private customer AI models and modification of prediction outputs. Replicate "promptly mitigated" the issue with no reported customer-data impact.
CVE-2024-8309 (CVSS 9.8 NIST, CRITICAL). LangChain GraphCypherQAChain SQL injection via prompt injection. Permits attackers to execute SQL-injection attacks through prompt manipulation, enabling unauthorized database operations, data theft, service disruption, and cross-tenant data access breaches. Published October 29, 2024.
CVE-2024-37032 (Ollama "Probllama"). Remote code execution via crafted HTTP requests / arbitrary file overwriting; complete RCE possible in Docker implementations. Patched by Ollama May 8, 2024. Subsequent Ollama CVEs in 2025 include CVE-2025-51471 (cross-domain token exposure) and CVE-2025-48889 (arbitrary file copy).
Defender control. Sign and verify every inbound model pull against a model SBOM. Scan inbound models for pickle deserialization risk before loading. Prefer safetensors over pickle for model storage. Track AI-tooling packages (LangChain, LangGraph, LlamaIndex, BentoML, MLflow, Triton Inference Server, Ollama) against GitHub Security Advisories and apply the same patch SLA you use for the rest of the software supply chain.
8. AI vendor APIs
The third-party AI APIs that production applications call out to (OpenAI, Anthropic, Google, Azure OpenAI, and platform integrators) are themselves an attack surface for two distinct populations: the integrator (your application calling someone else's AI) and the AI vendor (resisting credential abuse, prompt-injection passthrough, and rate-limit gaming).
Canonical attack. API-key theft. Rate-limit abuse turning AI APIs into attacker infrastructure (LLMjacking). Prompt-leaking system prompts via crafted user inputs. Cross-tenant queries via shared infrastructure flaws. Maps to LLM02:2025 Sensitive Information Disclosure and LLM07:2025 System Prompt Leakage.
Anchor incident. Microsoft Storm-2139 disruption (February 27, 2025). Storm-2139 members "exploited exposed customer credentials scraped from public sources to unlawfully access accounts with certain generative AI services. The scheme was called LLMjacking, the act of hijacking Large Language Models (LLMs) by stealing API keys, which act as digital credentials for accessing AI services." The ring then modified the safety capabilities of these services and resold access to other malicious actors. Microsoft Digital Crimes Unit initiated legal proceedings in December 2024 against ten initially unidentified individuals; four were named publicly: Arian Yadegarnia ("Fiz", Iran), Alan Krysiak ("Drago", United Kingdom), Ricky Yuen ("cg-dot", Hong Kong, China), and Phát Phùng Tấn ("Asakuri", Vietnam).
Defender control. Treat AI vendor API keys with the same controls you apply to cloud root credentials. Short-lived tokens; per-environment isolation; per-application scope. Monitor outbound spend telemetry on every AI vendor account; sudden spend spikes are a high-signal LLMjacking indicator. Cap per-account rate limits where the vendor lets you set them.
OWASP LLM Top 10 v2025 + MITRE ATLAS mapping
Each attack-surface category maps cleanly to the canonical taxonomies. The table below is the audit trail for defenders mapping their own pentest scope to standards-body coverage.
Attack-surface category | OWASP LLM Top 10 v2025 | MITRE ATLAS technique |
|---|---|---|
LLM-integrated SaaS | ||
Internal RAG + chatbots | LLM04 Data and Model Poisoning, LLM08 Vector and Embedding Weaknesses, LLM09 Misinformation | |
AI customer support | ||
Agentic AI + MCP | ||
AI-generated code in CI/CD | ||
Shadow-AI deployments | ||
AI supply chain | ||
AI vendor APIs | LLM02 Sensitive Information Disclosure, LLM07 System Prompt Leakage, LLM10 Unbounded Consumption |
Mapping note: where a category maps to multiple OWASP entries, the load-bearing one for pentest scoping is listed first. The MITRE ATLAS technique IDs are stable across the v5.4.0 (January 2026) update; defenders should verify against the ATLAS site before publishing in a pentest report.
The agentic-AI and MCP risk class deserves its own zoom
Agentic AI is the highest-impact half of the new attack surface, and the Model Context Protocol ecosystem is its most active vulnerability class as of May 2026. Four concrete risk classes already have published CVEs or canonical OWASP framings.

Figure 4: Four published CVE or canonical-framing anchors for the agentic-AI + MCP risk class. Each is a real disclosure as of May 2026. Sources: nvd.nist.gov; github.com/advisories; OWASP LLM Top 10 v2025; Anthropic GTG-1002.
MCP server compromise (CVE-2025-6514, CVSS 9.6). Untrusted MCP server triggers arbitrary OS command execution on the client running mcp-remote. The whole MCP ecosystem inherits the trust model of every server it connects to. Stingrai recommends defenders pin MCP server source by hash and run MCP servers in the least-privileged sandbox the host OS supports.
Malicious tool definitions (CVE-2025-64106). Cursor's MCP installation flow could be coerced into executing attacker-supplied commands on a developer's machine. Tool definitions are code, not configuration.
Agent prompt injection RCE (CVE-2025-53773). GitHub Copilot / Visual Studio prompt-injection RCE via the
chat.tools.autoApprovesetting. Microsoft patched in August 2025 Patch Tuesday and now requires explicit user approval for any configuration change that could impact security settings.Excessive Agency in production (OWASP LLM06:2025). OWASP's split into excessive functionality (tools beyond task scope), excessive permissions (tools operating with broader privileges than necessary), and excessive autonomy (high-impact actions proceeding without a human in the loop). Anthropic GTG-1002 is the canonical exemplar: 4 to 6 critical human decision points across an end-to-end campaign.
The shadow-AI problem is bigger than most teams measure
Shadow AI is the single largest ungoverned attack surface in 2026. Most organizations cannot answer the basic inventory question (which AI tools is the workforce using right now) without specific telemetry investments.
Prevalence. Roughly 80 percent of employees use unapproved AI tools at work; 76 percent of businesses have active bring-your-own AI use within the workforce (Cybersecurity Dive Aug 2025; CIO Magazine 2025).
Breach impact. 1 in 5 organizations have already experienced a breach tied to shadow AI; IBM's 2025 report measured shadow-AI breaches at 20 percent of all breaches with an average cost of US$4.63M versus US$3.96M for standard breaches (IBM CODB 2025).
Governance gap. Only 37 percent of organizations have any policy to manage or detect shadow AI; 69 percent suspect or have evidence that employees use prohibited public generative AI tools. 97 percent of organizations that suffered an AI-related incident lacked proper AI access controls (IBM CODB 2025).
Open-weight model exposure. 93 percent of organizations use open-weight models from public repositories, yet fewer than half consistently scan inbound models (HiddenLayer 2026).
The defender response is a shadow-AI inventory that aggregates browser-extension telemetry, network egress to consumer LLM endpoints, identity-system OAuth grants, and SaaS-platform AI feature usage against an explicit sanctioned-tool catalog. Sanction at least one capable tool per workflow so the policy is realistic; banning AI entirely simply moves the use further from telemetry.
What the defender stack looks like
A defender stack for the eight surfaces above is not exotic. It is three layers and twelve concrete controls.

Figure 5: Three-layer defender stack covering detection and telemetry, hardening and boundaries, and supply chain and governance. Twelve concrete controls. None are exotic; together they cover the eight attack-surface categories in this post. Sources: NIST AI 600-1 GenAI Profile; OWASP LLM Top 10 v2025; MITRE ATLAS v5.4.0; Mandiant M-Trends 2026; Stingrai engagement experience.
Detection and telemetry
What the SOC instruments for:
Outbound LLM API calls from non-developer hosts. A finance laptop calling api.anthropic.com or api.openai.com is a tell; a service account in the payroll subnet calling generativelanguage.googleapis.com is a higher-signal tell.
Parameter-mutation bursts on user-facing endpoints. Agent traffic generates 30+ unique parameter values per minute on a single endpoint at unusual hours; humans do not.
Anomalous tool-use sequences inside agent platforms. Per-tool baseline-deviation alerts inside the AI agent platform itself (LangSmith, LlamaCloud, native CrewAI / AutoGen telemetry).
Credential-store reads (Windows DPAPI, macOS Keychain, browser stores). Mandiant M-Trends 2026 named QUIETVAULT, an AI-aware credential stealer that hunts for local AI command-line tool tokens; the broader credential-store-reads class remains the load-bearing endpoint signal.
Hardening and boundaries
What the application team enforces:
Output filtering on agent responses. Block exfil patterns, mark links, redact secrets that should not appear in user-facing output.
Prompt hardening and system-prompt isolation. Use prompt-hierarchy techniques. Avoid placing privileged data in the system prompt. Run the production prompt through a prompt-injection regression harness.
RBAC and approval workflows for high-impact agent actions. "Send money", "reset password", "create admin account", "deploy to production" are not autonomous-agent decisions in 2026.
Per-token rate limits on user-facing AI APIs. LLMjacking thrives on absent rate limits; capping per-key spend reduces both abuse cost and detection latency.
Supply chain and governance
What procurement and risk own:
Model SBOM and signed model registry pulls. Track every inbound model file the way you track inbound container images. Sign and verify against a hash registry.
Inbound model scanning to block pickle backdoors. Prefer safetensors format over pickle. Run an AI-aware model scanner (e.g. Protect AI ModelScan or Picklescan) before loading any inbound model artifact.
Third-party AI vendor risk assessments. Treat AI vendors with the same supplier review you apply to the rest of your SaaS supply chain. Read their security posture, breach history, and AI governance disclosures.
Shadow-AI inventory plus sanctioned-tool catalog. Make the policy realistic; sanction at least one capable AI tool per workflow so employees do not have to bypass policy to get work done.
What this means for security buyers
For most mid-market and enterprise buyers, the practical implication of this map is a pentest scoping question.
Are your annual pentests still in scope? Most engagements scoped before mid-2024 do not include LLM-integrated SaaS, RAG corpus, MCP server endpoints, or AI-generated code review. Update the scope.
Are your agentic AI workflows tested as agents, not as web apps? A pentest that tests the UI but not the tool-call surface misses the largest part of the new attack surface.
Are your model registry pulls signed? If not, you are accepting the supply-chain risk of every inbound model file at face value.
Do you have a shadow-AI inventory? If not, the largest single ungoverned attack surface is the one you cannot point at.
Stingrai PTaaS is a continuous-validation product with named senior pentesters running ongoing scope coverage; the AI agent Snipe augments coverage on known classes (the AI-led portion runs roughly 30 to 40 percent of an engagement), while senior pentesters keep ownership of business-logic discovery, exploit chaining, impact framing, and remediation guidance. Stingrai's AI penetration-testing service treats the eight attack-surface categories in this post as first-class deliverables.
Forward outlook
What primary publishers explicitly project for the next 12 to 24 months:
MCP vulnerabilities will multiply as the protocol's adoption widens. Palo Alto Unit 42, GitHub Security Advisory authors, and independent research teams are now publishing MCP advisories at a quarterly cadence. Expect double-digit MCP-specific CVEs by year-end 2026.
AI supply-chain CVE volume will rise sharply. Protect AI Huntr and HiddenLayer are both publishing monthly AI / ML supply-chain advisories. The 2024 baseline of roughly 30 vulnerabilities per monthly report on Huntr is unlikely to fall.
Shadow-AI policy enforcement will harden inside enterprises. Insurance underwriters and external auditors are pricing shadow-AI risk explicitly; expect renewal-cycle questionnaires to demand shadow-AI inventory documentation by mid-2026.
AI vendor APIs will face more LLMjacking activity. Microsoft's Storm-2139 disruption is the first wave; expect named disruptions from AWS, Anthropic, Google, and other AI vendors to follow.
Standards-body coverage will converge. OWASP LLM Top 10, MITRE ATLAS, NIST AI 600-1, and ISO/IEC 42001:2023 are now mutually-referencing; expect a shared cross-walk to land in regulatory cybersecurity questionnaires within the next 12 months.
Frequently Asked Questions
What is the AI attack surface in 2026?
The AI attack surface is the set of new exposures generative AI introduced or expanded across the corporate perimeter. Stingrai's 2026 map identifies eight categories: LLM-integrated SaaS applications, internal RAG and chatbots, AI-powered customer support, agentic-AI workflows and the Model Context Protocol (MCP), AI-generated code in CI/CD, shadow-AI deployments, AI supply chain (models, datasets, AI-tooling packages), and AI vendor APIs. Each is anchored by a real published CVE or named industry incident as of May 2026, including LangChain GraphCypherQAChain SQL injection (CVE-2024-8309), GitHub Copilot prompt-injection RCE (CVE-2025-53773), mcp-remote RCE (CVE-2025-6514, CVSS 9.6), Ollama Probllama (CVE-2024-37032), the Hugging Face pickle-backdoor disclosures of February 2024 (approximately 100 malicious models catalogued), the Replicate cross-tenant disclosure of January 2024, and Microsoft's Storm-2139 LLMjacking ring disruption (February 27, 2025).
How does the AI attack surface map to OWASP LLM Top 10 v2025 and MITRE ATLAS?
LLM01 Prompt Injection is the load-bearing precondition for most AI attacks; LLM06 Excessive Agency is the load-bearing amplifier; LLM03 Supply Chain carries the model registry, dataset, and AI-tooling-package half; LLM04 Data and Model Poisoning carries the RAG and training-data half. MITRE ATLAS technique IDs AML.T0017 Develop Adversarial Code, AML.T0016 ML Artifact Collection, AML.T0024 Exfiltration via Cyber Means, and AML.T0036 LLM Plugin Compromise cover the adversarial-ML half. Stingrai's mapping table in this post provides the audit trail for defender programs aligning pentest scope to standards-body coverage.
What is the most common AI vulnerability defenders should expect in 2026?
Prompt injection. OWASP LLM01:2025 is the canonical entry technique for LLM-integrated SaaS, RAG, AI customer support, and AI-generated code in CI/CD. The August 2025 Patch Tuesday from Microsoft addressed CVE-2025-53773 (GitHub Copilot prompt-injection RCE) and the related CVE-2025-62222 (Copilot Chat RCE); both rely on prompt injection as the entry technique. Anthropic GTG-1002 used jailbreaking and task decomposition as the precondition for keeping Claude inside the operational loop across an end-to-end espionage campaign.
What is the Model Context Protocol (MCP) and why is it now a CVE class?
MCP is the open-protocol layer that lets agentic AI systems call out to tools, file systems, source repositories, and SaaS APIs. Every MCP server an agent connects to is, in practice, a code-execution surface for the agent's host process. CVE-2025-6514 (mcp-remote, CVSS 9.6) is the canonical example: an untrusted MCP server triggers arbitrary OS command execution on the client running mcp-remote. CVE-2025-64106 (Cursor MCP installation, CVSS 8.8) and CVE-2025-53967 (figma-developer-mcp, CVSS 7.5) extend the class. Defenders should pin MCP server source by hash, run MCP servers in the least-privileged sandbox the host OS supports, and validate that every MCP server connection terminates at an allow-listed endpoint.
What is shadow AI and how much does it cost in 2026?
Shadow AI is the consumer-LLM and AI-extension use that flows around organizational policy, where employees use AI tools without organizational visibility or governance. IBM Cost of a Data Breach 2025 measured shadow AI adding US$670K to the average breach cost, with shadow-AI breaches now 20 percent of all breaches at an average cost of US$4.63M versus US$3.96M for standard breaches. Survey aggregates converge on roughly 80 percent of employees using unapproved AI tools, 1 in 5 organizations already breached via shadow AI, and only 37 percent of organizations having any policy to manage or detect shadow AI. The defender response is a shadow-AI inventory that aggregates browser, network, and identity telemetry against an explicit sanctioned-tool catalog, plus realistic sanctioning of at least one capable AI tool per workflow.
What is LLMjacking and what does Microsoft Storm-2139 tell us?
LLMjacking is the abuse of stolen API keys or credentials to hijack large language model services for unauthorized use. Microsoft's Storm-2139 disruption (February 27, 2025) is the canonical published case: the ring exploited stolen customer credentials scraped from public sources to access generative AI services, modified the safety capabilities of these services, and resold access to other malicious actors. Microsoft Digital Crimes Unit initiated legal proceedings in December 2024 against ten initially unidentified individuals; four were named publicly. Defenders should treat AI vendor API keys with the same controls applied to cloud root credentials, monitor outbound spend telemetry on every AI vendor account, and cap per-account rate limits where the vendor supports it.
How dangerous are malicious models from public repositories like Hugging Face?
The February 2024 Hugging Face disclosure identified approximately 100 malicious models with code-execution payloads via Python pickle's __reduce__ method. Named examples included baller423/goober2 and star23/baller13, both with reverse-shell payloads in PyTorch model files. The attack vector exploits the trusted serialization process of Python's pickle module to inject arbitrary code that runs the moment the model is loaded. PyTorch models exhibited the highest prevalence of malicious instances, followed by TensorFlow Keras models. HiddenLayer's 2026 AI Threat Landscape Report measured 93 percent of organizations using open-weight models from public repositories, with fewer than half consistently scanning inbound models. The defender response is to prefer the safetensors format over pickle, scan inbound models with an AI-aware scanner before loading, and verify models against a model SBOM with signed registry pulls.
What does the agentic AI risk class mean for pentest scoping?
Most pentest engagements scoped before mid-2024 do not include LLM-integrated SaaS, RAG corpus, MCP server endpoints, or AI-generated code review. The agentic AI risk class adds three new scoping dimensions: prompt-injection regression testing of the production system prompt (not only development), tool-call surface testing for every agent the application exposes, and supply-chain testing of every MCP server or model file the application imports. Stingrai PTaaS engagements include all three as first-class deliverables; the AI agent Snipe augments coverage on known classes, while senior pentesters keep ownership of business-logic discovery, exploit chaining, and impact framing.
What is the OWASP LLM Top 10 v2025 take on agentic AI?
LLM06:2025 Excessive Agency is the canonical OWASP entry for agentic AI risk. OWASP splits LLM06 into three root causes: excessive functionality (agents reaching tools beyond their task scope), excessive permissions (tools operating with broader privileges than necessary), and excessive autonomy (high-impact actions proceeding without a human in the loop). The Anthropic GTG-1002 disclosure hit all three: the agent had reach into Claude Code's tool surface (functionality), used those tools with the operator's full project privileges (permissions), and executed multi-step tactical work with only 4 to 6 critical human approvals per campaign (autonomy). The OWASP guidance explicitly recommends approval workflows on high-impact actions; the GTG-1002 case study is now the canonical exemplar.
How is Stingrai involved in AI attack-surface testing?
Stingrai is a Toronto-headquartered offensive-security firm founded in 2021. Stingrai Inc is a CREST-accredited Penetration Testing service provider (firm-level accreditation, separate from individual CREST CRT certifications held by team members). The team has 18 published CVEs (Ivan Spiridonov 10, Moaaz Taha 5, Victor Villar 3), 5.0/5.0 across 19 Clutch reviews, and team certifications spanning OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO, GCPN, CRTE, and eWPTX. Snipe, Stingrai's internal AI pentest agent, is web-app focused, trained on more than 6,000 HackerOne disclosures, and performs both black-box dynamic testing and white-box source-code review; Snipe generates AutoFix pull requests for the issues it identifies and can run as a PR-gating check that blocks vulnerable code from being merged. Senior pentesters keep ownership of business-logic discovery, exploit chaining, impact framing, and remediation guidance. We present research at DEFCON and BSIDES, and Stingrai's pentest output supports SOC 2, ISO 27001, HIPAA, PCI DSS 4.0, NIST SP 800-53/171, DORA, and NIS2 compliance evidence (the attestation/certification itself is issued by a qualified third-party auditor). The eight attack-surface categories in this post are scoped as first-class deliverables in Stingrai PTaaS and Stingrai AI penetration-testing engagements.
Related Stingrai research
AI Cyber Attack Statistics 2026. Attacker-side enumeration of named AI-enabled campaigns and population-level offensive statistics.
AI Cybersecurity Threats 2026. Defender-side risk taxonomy and governance framing.
Anthropic Mythos / GTG-1002 Defender Analysis. Stingrai's defender-side analysis of the Anthropic GTG-1002 disclosure.
AI in Offensive Security 2026. Stingrai's read on how AI changes the attacker tooling stack.
GitHub Actions Security Checklist. The CI/CD hardening half of the AI-generated code surface.
Supply Chain Attack Statistics. Cross-link for the AI supply chain category.
Compromised Credential Statistics 2026. Cross-link for the AI vendor API key theft category.
References
IBM and Ponemon Institute. Cost of a Data Breach Report 2025. July 2025. https://newsroom.ibm.com/2025-07-30-IBM-Report-Breaches-Cost-U-S-Businesses-10-22M-on-Average-as-AI-Defenses-and-Attacks-Take-Off. 1-in-6 attacker AI; shadow AI +US$670K per breach; defender-AI saves US$1.9M.
Anthropic. Disrupting the first reported AI-orchestrated cyber espionage campaign. November 13, 2025. https://www.anthropic.com/news/disrupting-AI-espionage. GTG-1002 disclosure.
Anthropic. Detecting and countering misuse of AI: August 2025. August 2025. https://www.anthropic.com/news/detecting-countering-misuse-aug-2025. Vibe hacking and RaaS case studies.
CrowdStrike. 2026 Global Threat Report. February 2026. https://www.crowdstrike.com/en-us/blog/crowdstrike-2026-global-threat-report-findings/. +89 percent YoY AI-enabled attacks; 90+ orgs prompt-injection victims.
Mandiant (Google Cloud). M-Trends 2026. March 2026. https://cloud.google.com/blog/topics/threat-intelligence/m-trends-2026. 22-second median initial-access-to-handoff; PROMPTFLUX, PROMPTSTEAL, QUIETVAULT.
Microsoft. Disrupting a global cybercrime network abusing generative AI. February 27, 2025. https://blogs.microsoft.com/on-the-issues/2025/02/27/disrupting-cybercrime-abusing-gen-ai/. Storm-2139 LLMjacking ring disruption.
HiddenLayer. 2026 AI Threat Landscape Report. 2026. https://hiddenlayer.com/threatreport2025/. 88 percent internally operated AI critical; 76 percent shadow-AI concern.
The Hacker News (Newsroom). Over 100 Malicious AI/ML Models Found on Hugging Face Platform. March 2024. https://thehackernews.com/2024/03/over-100-malicious-aiml-models-found-on.html. Independent coverage of approximately 100 malicious Hugging Face models with pickle backdoors.
GitHub Security Advisory. CVE-2025-6514 mcp-remote RCE. 2025. https://github.com/advisories/GHSA-rgj6-q6gp-fr5w. mcp-remote RCE (CVSS 9.6), patched in v0.1.16.
The Hacker News (Newsroom). Researchers Uncover Cross-Tenant Attack on Replicate AI Platform. May 2024. https://thehackernews.com/2024/05/researchers-uncover-cross-tenant-attack.html. Replicate cross-tenant access disclosure.
NVD. CVE-2024-8309: LangChain GraphCypherQAChain SQL injection via prompt injection. October 29, 2024. https://nvd.nist.gov/vuln/detail/CVE-2024-8309. CVSS 9.8 CRITICAL.
Microsoft Security Response Center. CVE-2025-53773: GitHub Copilot remote code execution via prompt injection. August 2025. https://msrc.microsoft.com/update-guide/vulnerability/CVE-2025-53773. YOLO mode RCE.
OWASP. Top 10 for LLM Applications v2025. 2025. https://genai.owasp.org/llm-top-10/. LLM01 Prompt Injection through LLM10 Unbounded Consumption.
MITRE. ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems). v5.4.0, January 2026. https://atlas.mitre.org/. Adversarial-ML technique taxonomy.
NIST. AI Risk Management Framework + AI 600-1 GenAI Profile. July 2024. https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence. 12 GenAI risk categories.
World Economic Forum. Global Cybersecurity Outlook 2026. January 2026. https://www.weforum.org/publications/global-cybersecurity-outlook-2026/. AI is the biggest cybersecurity change driver.
ISO/IEC. 42001:2023 Artificial Intelligence Management System. 2023. https://www.iso.org/standard/81230.html. AI management system standard.
Protect AI Huntr. AI/ML bug bounty platform. 2024-2026. https://huntr.com/. Monthly vulnerability disclosures across AI/ML supply chain.
Palo Alto Networks Unit 42. New Prompt Injection Attack Vectors Through MCP Sampling. 2025. https://unit42.paloaltonetworks.com/model-context-protocol-attack-vectors/. MCP attack research.
Anthropic. Model Context Protocol specification. 2024-2026. https://modelcontextprotocol.io/. MCP open-protocol layer.
If your team needs an outside read on its 2026 AI attack-surface coverage, prompt-injection resilience, agentic-AI workflow exposure, or AI supply-chain hygiene, Stingrai's pentest team runs continuous-validation engagements with senior-pentester depth augmented by our internal AI agent. Reach out via the contact page to scope an engagement.


