
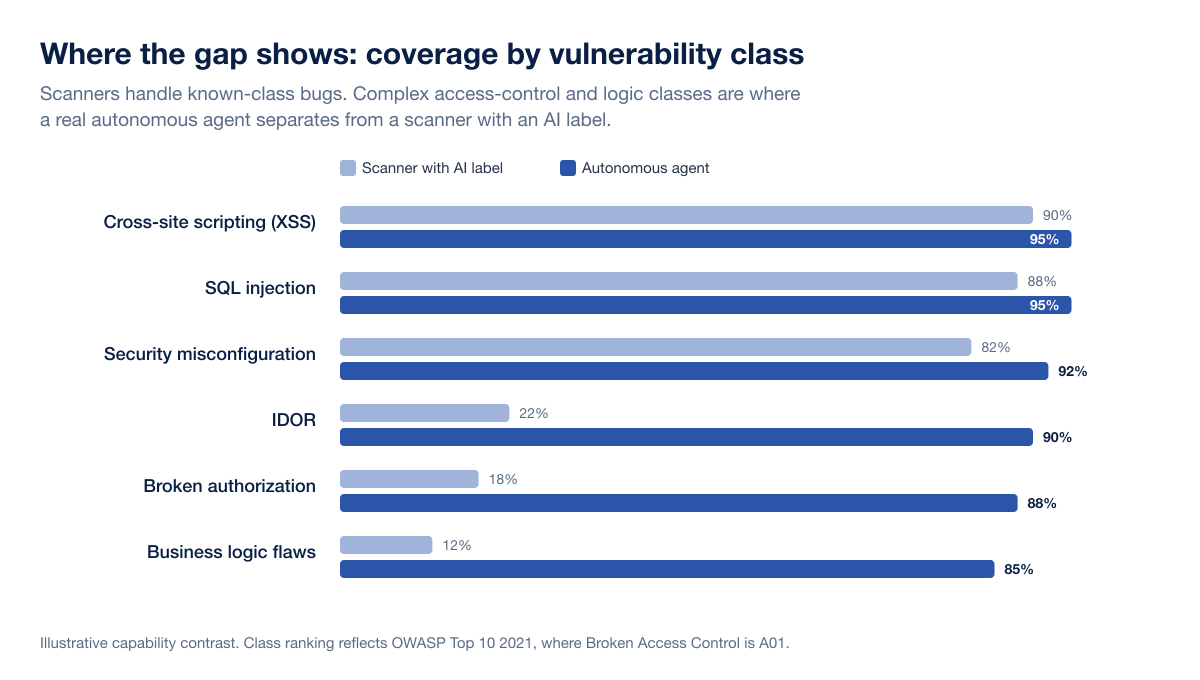
The fastest way to tell a real AI pentest from AI washing is to ask exactly which vulnerability classes the AI finds on its own. A genuine autonomous testing agent finds Insecure Direct Object References (IDOR), business logic flaws, and broken authorization, the access-control classes that sit at the very top of the risk pyramid. Broken Access Control is the number-one category in the OWASP Top 10 2021, where 94% of tested applications showed some form of it. A scanner wearing an AI badge finds known-class bugs like cross-site scripting, SQL injection, and misconfiguration, then wraps the report in a large language model and markets the summary as "AI-powered penetration testing."
This post gives you 12 concrete proof questions to ask an AI pentest vendor before you sign, each paired with the answer that signals real capability versus AI washing. The list is written as a copy-pasteable RFP insert, so you can drop it straight into a vendor questionnaire. If a vendor cannot answer these directly, that itself is the answer.
What questions should I ask an AI pentest vendor to spot AI washing?
Ask what the AI finds without a human, whether it tests black-box and white-box, how it was trained and evaluated, how it handles false positives, whether a human validates findings, how retesting works, how your data and scope are handled, and what coverage evidence you receive. The answers that signal real capability all point the same direction: the vendor can name the complex vulnerability classes the AI finds, describe the training data behind that capability, and hand you reproducible evidence per finding. Vague answers ("proprietary AI," "next-generation," "we can't disclose that") are the tell.
Regulators now treat exaggerated AI claims as fraud, not marketing puffery. The U.S. Securities and Exchange Commission brought its first "AI washing" enforcement actions on March 18, 2024, charging two investment advisers with false statements about their use of AI and imposing US$225,000 and US$175,000 civil penalties (SEC, 2024). Six months later the Federal Trade Commission announced Operation AI Comply, five enforcement actions against deceptive AI claims, stating plainly that "there is no AI exemption from the laws on the books" (FTC, 2024). The security-testing market has the same incentive to overstate, and far less regulatory attention. Vetting is on you.

Key takeaways
The vulnerability-class question is the master key. A real autonomous agent finds IDOR, business logic, and broken authorization on its own. A scanner with an AI label finds XSS, SQLi, and misconfiguration and calls the natural-language summary "AI."
Training data is the proof behind the capability. Ask what the model learned complex-bug hunting from. "General web knowledge" is a scanner. A corpus of real disclosed vulnerabilities plus distilled human-tester methodology is a hunter.
Human validation is a feature, not an admission. The right answer is that senior testers validate and extend the AI's findings, so your report has near-zero false positives and no AI hallucinations reach you.
Evidence beats adjectives. You should receive a reproducible request, a proof-of-concept, and a remediation path per finding. If the vendor cannot show per-finding evidence, the "AI" is doing marketing, not testing.
The 12 proof questions (RFP insert)
Copy the block below directly into your vendor questionnaire. Each question is followed by the answer that signals real autonomous capability and the answer that signals AI washing.

What the AI actually finds
1. Which vulnerability classes does your AI find without a human in the loop? Real capability: named complex classes, specifically IDOR, business logic flaws, and broken authorization or access-control bypasses, not just the OWASP Top 10 scanner staples. Broken Access Control is A01 in the OWASP Top 10 2021 precisely because these are the highest-impact, hardest-to-automate bugs. AI washing: "the full OWASP Top 10" with no mention of access control or logic, or a class list that stops at XSS, SQLi, and misconfiguration.
2. Show me a real finding your AI produced in a complex class. What did the exploit chain look like? Real capability: a concrete, sanitized example of an IDOR or authorization bypass, with the reasoning steps the agent took. AI washing: a generic CVE writeup, a screenshot of a scanner dashboard, or "we can share that after signing."
3. Does the AI do black-box dynamic testing, white-box source-code review, or both? Real capability: both. The agent tests the running application dynamically and reviews source code for issues that only appear in the code path. AI washing: black-box only, rebadged from a DAST product, or "white-box" that is really a static linter with an LLM summary.
4. Can it generate a fix, not just a finding? Real capability: the agent produces remediation guidance and, ideally, an AutoFix pull request against your codebase that a developer can review and merge. AI washing: a report with severity ratings and no path to a fix.
How the AI was built and evaluated
5. What was the AI trained on to find complex bugs? Real capability: a corpus of real disclosed vulnerabilities (for example, thousands of HackerOne Hacktivity reports) plus methodology distilled from experienced human pentesters. That is where complex-bug intuition comes from. AI washing: "a large language model" with no security-specific training, or "proprietary, can't say."
6. How do you evaluate the AI's performance, and against what benchmark? Real capability: a defined evaluation set, measured recall on known-planted vulnerabilities, and a process for tracking regressions as the agent updates. AI washing: no benchmark, or "our customers love it" as the only metric.
7. How does the AI handle false positives? Real capability: a validation stage that confirms exploitability before a finding reaches you, so your report is high-signal. AI washing: raw scanner output passed through, leaving your team to triage noise, or an LLM that "usually gets it right."
8. What stops the AI from hallucinating a vulnerability that does not exist? Real capability: every finding is backed by a reproducible request and proof-of-concept, and a human validates before delivery. AI washing: no reproduction step, no human check, just model confidence.
Who validates, and how testing is governed
9. Does a qualified human validate findings before I see them? Real capability: senior, certified pentesters validate and extend the AI's findings. The human-AI hybrid raises the ceiling; the AI is not left to grade its own homework. AI washing: "fully automated, no humans needed," which usually means no one caught the false positives either.
10. How do you enforce scope and rules of engagement? Real capability: explicit scope controls, allow-lists, rate limits, and safeguards that keep the agent inside authorized targets, with an audit trail. AI washing: a vague promise that the tool "stays in scope," with no enforcement mechanism described.
11. How is my data and source code handled, and where does it live? Real capability: clear answers on data residency, retention, isolation, and whether your code or traffic is used to train shared models (it should not be, without consent). AI washing: no data-handling documentation, or terms that reserve the right to train on your material.
12. What coverage evidence and retesting do I get? Real capability: a coverage map of what was tested, per-finding reproduction steps, and a retest to confirm fixes, ideally with the agent runnable continuously or as a pull-request gate. AI washing: a point-in-time PDF, no coverage evidence, and retesting billed as a brand-new engagement.
How to read the answers
One weak answer is not disqualifying. A pattern is. If a vendor cannot name the complex classes their AI finds (question 1), cannot show a real finding (question 2), and cannot describe training data (question 5), you are almost certainly looking at a scanner with a language model bolted onto the report. Those three questions carry the most weight because they are the hardest to fake. Marketing can produce a confident answer to "do you use AI"; only a real capability can produce a sanitized IDOR exploit chain and name the corpus it learned from.
The false-positive and human-validation questions (7, 8, 9) matter because they determine how much of your team's time the engagement consumes. A tool that ships raw output shifts the triage cost onto you and calls it "efficiency." A validated deliverable is the actual product you are paying for.
What real capability looks like: how Snipe answers these questions
Stingrai built its AI pentesting agent, Snipe, to answer every question above directly, because these are the questions our own clients ask.
Snipe is an autonomous web application pentesting agent purpose-built to hunt the complex classes generic AI tools miss: IDOR, business logic flaws, and broken authorization. It performs both black-box dynamic testing and white-box source-code review, generates AutoFix pull requests for the issues it finds, and can run as a pull-request gate that blocks vulnerable code from merging. It was custom-trained on more than 6,000 HackerOne Hacktivity disclosure reports plus skills distilled from years of Stingrai's human pentesters' methodology, so it encodes how senior testers actually find these bugs. Findings are validated and extended by Stingrai's senior pentesters, so what reaches you is reproducible and high-signal, not raw model output. Stingrai is a firm-level CREST-accredited penetration testing provider, and its pentest evidence supports your SOC 2, ISO 27001, and PCI DSS compliance program.
If you want a structured way to score vendors against these criteria, the AI pentesting evaluation guide and the emerging OWASP autonomous pentest standard are good companions to the RFP insert above.
Frequently asked questions
What questions should I ask an AI pentest vendor to tell real autonomous testing from AI washing before I sign?
Ask which vulnerability classes the AI finds without a human, whether it tests black-box and white-box, what it was trained on, how it handles false positives, whether a human validates findings, and what coverage evidence and retesting you receive. Real capability points to complex classes (IDOR, business logic, broken authorization), a security-specific training corpus, human validation, and per-finding reproduction steps. Vague, non-disclosing answers signal a scanner with an AI label.
What is AI washing in penetration testing?
AI washing is marketing a conventional security scanner as an autonomous AI pentester by adding a language model to the report and calling the result "AI-powered." Regulators treat exaggerated AI claims as actionable: the SEC brought its first AI-washing cases in March 2024 (SEC, 2024) and the FTC ran Operation AI Comply in September 2024 (FTC, 2024).
Is this AI pentest real or just a scanner with an AI label?
The clearest test is the vulnerability-class question. Scanners reliably find XSS, SQL injection, and misconfiguration. Real autonomous agents also find access-control and logic bugs. Because Broken Access Control is the number-one OWASP Top 10 2021 category and resists automation, a vendor that can demonstrate real IDOR and authorization findings is doing more than scanning.
Should an AI pentest include human validation?
Yes. The strongest model is a human-AI hybrid where senior pentesters validate and extend the AI's findings. That keeps false positives and hallucinations out of your report while letting the AI cover ground quickly. "Fully automated, no humans" usually means no one filtered the noise.
How do I vet an AI pentesting vendor's training data?
Ask what corpus taught the model to find complex bugs. The right answer names real disclosed vulnerabilities (for example, thousands of HackerOne Hacktivity reports) plus distilled human-pentester methodology. "A general LLM" or "proprietary, can't disclose" tells you the complex-bug capability is unproven.
Does an AI pentest do white-box source-code review or only black-box testing?
A capable agent does both: black-box dynamic testing against the running application and white-box review of the source. Black-box-only tools rebadged from a DAST product miss issues that only appear in the code path, and vice versa.
What evidence should an AI pentest deliver per finding?
A reproducible request, a proof-of-concept demonstrating exploitability, a severity rating tied to real impact, and a remediation path (ideally an AutoFix pull request). Coverage evidence and a retest to confirm fixes should be part of the engagement, not billed separately.
Where can I get a structured checklist to evaluate AI pentest vendors?
Use the 12 proof questions above as an RFP insert, and pair them with Stingrai's AI pentesting evaluation guide and the best AI penetration testing services overview for scoring context.
Put the RFP insert to work
The 12 questions above are designed to be pasted into a real procurement document. If you want to see a vendor answer all of them in one conversation, talk to Stingrai about Snipe and how its autonomous testing, human validation, and AutoFix workflow map to each proof question. Pricing and packages are on the Stingrai pricing page.
References
OWASP. OWASP Top 10 2021: A01 Broken Access Control. 2021. https://owasp.org/Top10/2021/A01_2021-Broken_Access_Control/. Ranks Broken Access Control as the number-one web application risk; 94% of tested applications showed some form of it, with IDOR and authorization flaws among the mapped CWEs.
U.S. Securities and Exchange Commission. SEC Charges Two Investment Advisers with Making False and Misleading Statements About Their Use of Artificial Intelligence. March 18, 2024. https://www.sec.gov/newsroom/press-releases/2024-36. First SEC "AI washing" enforcement actions, with US$225,000 and US$175,000 civil penalties.
U.S. Federal Trade Commission. FTC Announces Crackdown on Deceptive AI Claims and Schemes (Operation AI Comply). September 25, 2024. https://www.ftc.gov/news-events/news/press-releases/2024/09/ftc-announces-crackdown-deceptive-ai-claims-schemes. Five enforcement actions against deceptive AI marketing, affirming there is no AI exemption from existing law.


