
AI penetration testing is now a crowded market, and most of the noise comes from vendors that describe a scanner with a language-model wrapper as "autonomous offensive security." The job of a 2026 buyer is to tell the tools that prove exploitation apart from the tools that generate plausible-looking findings. The cleanest filter is a number from the most-cited example in the category: when XBow's autonomous agent reached the top of HackerOne's US leaderboard it submitted nearly 1,060 vulnerabilities, but only 130 were resolved, with 303 triaged and 208 marked duplicate, per XBow's own write-up. Submission volume is easy; validated, fixed risk is the thing you are actually buying.
The practitioners who do this work for a living are blunt about it. In the Cobalt Pentester Profile Report 2026, a survey of 198 vetted offensive-security professionals, just 1% considered AI-only scanning the most effective model for uncovering high-impact, exploitable vulnerabilities, while 58% picked human-led PTaaS. That does not mean AI has no place. It means the right question is not "is it AI?" but "what does the AI actually prove, how deep does it reach, and where does a human sign off?" This guide gives you seven evaluation criteria, the three autonomy tiers, and the questions that cut through AI washing.
TL;DR: Evaluating AI Pentesting in 2026
Score validated risk, not volume. XBow's leaderboard run submitted ~1,060 findings but only 130 were resolved, per XBow. Ask for resolved, exploitable findings, not submission counts.
Depth is the real differentiator. Most AI tools stop at known-class, fingerprintable bugs. The hard, high-impact classes are IDOR, business logic, and broken authorization. Ask which the tool actually reaches.
Practitioners distrust AI-only. Only 1% of pentesters rank AI-only scanning most effective for high-impact bugs, versus 58% for human-led PTaaS, per the Cobalt Pentester Profile Report 2026.
Seven criteria: validation and accuracy, vulnerability depth, autonomy and adaptation, safety and governance, operational integration, scalability and economics, and transparency and reporting.
Three autonomy tiers: AI-assisted, hybrid (AI-augmented), and AI-led autonomous. Match the tier to your stage and risk tolerance.
The strong profile: an AI-led tool that genuinely reaches complex classes, validated by humans. Stingrai's Snipe is that profile, hunting IDOR, business logic, and authorization, with AutoFix pull requests and PR-gating, validated by senior testers.
Key Takeaways
"AI washing" is the main risk in this purchase. A signature scanner with a chatbot is not autonomous offensive security. The diagnostic is whether the tool proves exploitation and reproduces the finding, not whether it theorizes a vulnerability from a pattern match.
Volume metrics are designed to impress, not to inform. A leaderboard rank or a four-figure submission count says nothing about whether the findings were real, novel, and fixed. Resolution rate and false-positive rate are the honest numbers.
Depth, not autonomy, is where most tools fail. Autonomous agents skew toward fingerprintable bugs (XSS, SQLi, SSRF). IDOR, business logic, and authorization flaws require understanding intent, and that is exactly where a serious AI pentest tool must prove itself.
Governance is a procurement requirement, not a nice-to-have. Kill switches, scope and time-window controls, secret handling, and a clear data-retention and model-training policy decide whether security and legal will approve the tool at all.
The best results are AI-led plus human-validated. AI handles breadth and speed; humans confirm exploitability and chain multi-step attacks. Only 12% of researchers in HackerOne's 2025 survey believe AI could replace humans entirely.
Why Evaluate AI Pentesting Carefully
The pressure to adopt AI pentesting is real and rational. Software ships continuously, attack surfaces mutate daily, and human-only testing cannot cover everything fast enough. The Verizon 2025 DBIR, which analyzed over 22,000 incidents and 12,000 confirmed breaches, found vulnerability exploitation as an initial access vector rose 34% year over year, and stolen credentials feature in 88% of basic web application attacks. Buyers genuinely need more coverage, faster.
The problem is that the market's incentives reward the appearance of capability. A tool that submits a thousand reports looks more impressive than one that proves ten exploitable, business-critical bugs, even though the second is worth far more. The Cobalt data is a useful corrective: practitioners who evaluate these tools constantly put AI-only scanning at the bottom for the bugs that matter. Your evaluation has to be built to surface that gap, not to be dazzled past it.
The Three Autonomy Tiers
AI pentesting tools sit on a spectrum of how much the machine does versus the human. Naming the tier first prevents you from comparing tools that are not in the same category.
AI-assisted. The human runs the test; AI accelerates specific tasks such as recon, payload generation, or report drafting. Best when you have skilled testers and want them faster. The AI is a force multiplier, not an operator.
Hybrid (AI-augmented). AI handles discrete phases (discovery, attack-path analysis, initial exploitation) and humans validate between phases and own the complex chaining. This is the most common serious model in 2026, because it pairs machine breadth with human judgment.
AI-led autonomous. The AI maps the surface, forms hypotheses, attempts exploit chains, and drafts findings; humans oversee scope and review results. The bar here is high: an autonomous tool is only as good as the classes it actually reaches and the validation behind its claims.
The tiers are not a quality ranking; a great hybrid tool beats a weak autonomous one. The point is to match the tier to your stage, your in-house skill, and your risk tolerance, then evaluate within the tier.
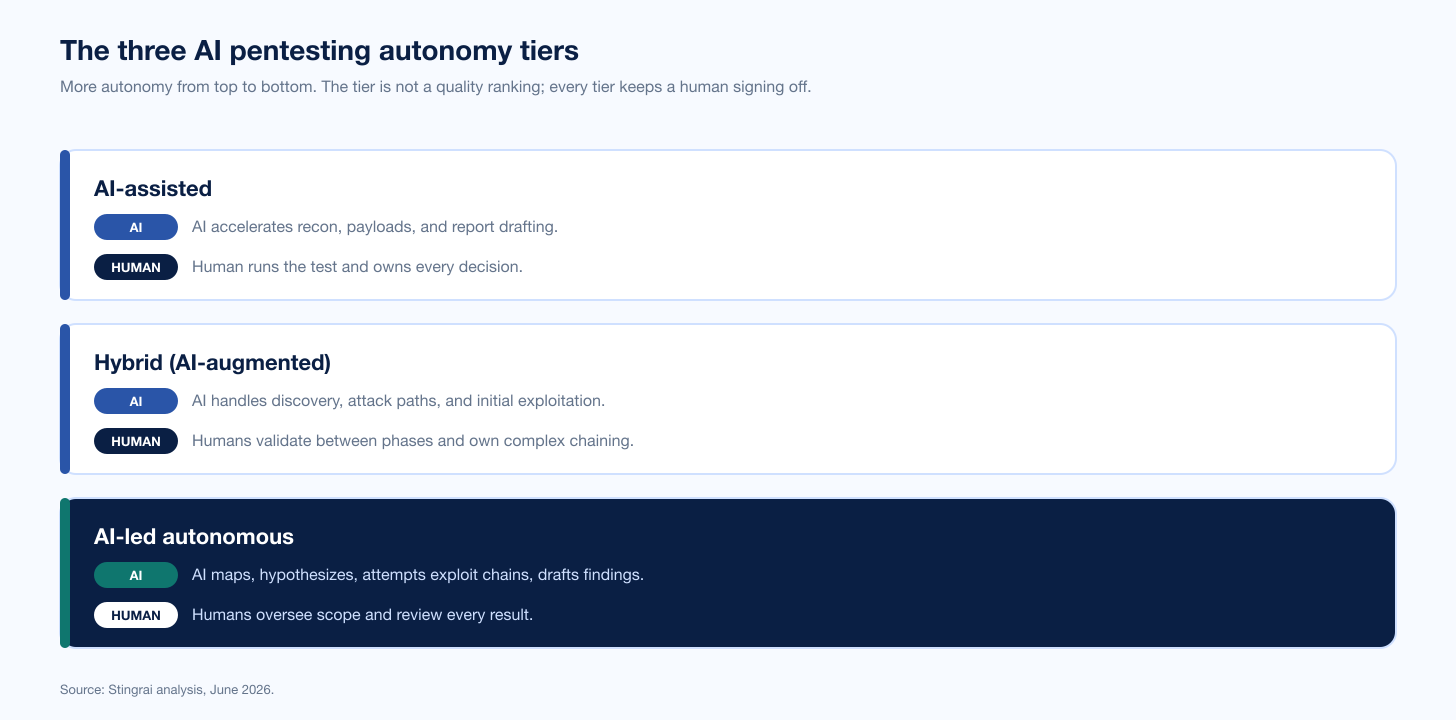
Figure 1: The three AI pentesting autonomy tiers and where human expertise enters each. Source: Stingrai analysis, June 2026.
Seven Criteria for Evaluating an AI Pentesting Vendor
Use these seven criteria as a scorecard. They are ordered so the highest-signal filters come first.
Validation and accuracy. Does the tool prove a finding is exploitable and reproduce it, or does it theorize from a pattern? Ask for the false-positive rate, whether findings are reproducible, whether it discovers novel issues rather than re-reporting known CVEs, and whether it accepts source code to improve precision. This is the criterion that most reliably exposes AI washing.
Vulnerability depth. Which classes does it actually find? Most tools handle the fingerprintable ones. Push hard on IDOR, business logic flaws, and broken authorization and access control, the high-impact classes generic AI misses. A vendor that cannot show real examples in these classes is a breadth tool, regardless of marketing.
Autonomy and adaptation. Can it chain multi-step exploits, adapt to an application's responses, and pursue hypothesis-driven attack paths, or does it run a fixed checklist? Adaptation is what separates an agent from a scanner.
Safety and governance. Look for customizable guardrails, a kill switch, scope and testing-hour controls, secure secret handling, and an explicit policy on data retention and whether your data trains the vendor's models. This is what your security and legal teams will gate the purchase on.
Operational integration. Does it offer API access, CI/CD integration, ticketing connectors (Jira, GitHub), developer-initiated testing, and incremental testing on change? Findings that reach the developer's queue get fixed; findings that sit in a portal get filed.
Scalability and economics. Can it test many applications concurrently, run continuously or on a schedule, and give you predictable cost? Understand how much human interaction is required to get value, because that is the hidden price.
Transparency and reporting. Are findings actionable and reproducible, with audit-ready documentation for SOC 2, ISO 27001, and PCI DSS evidence? A finding you cannot reproduce or explain to an auditor is not usable.
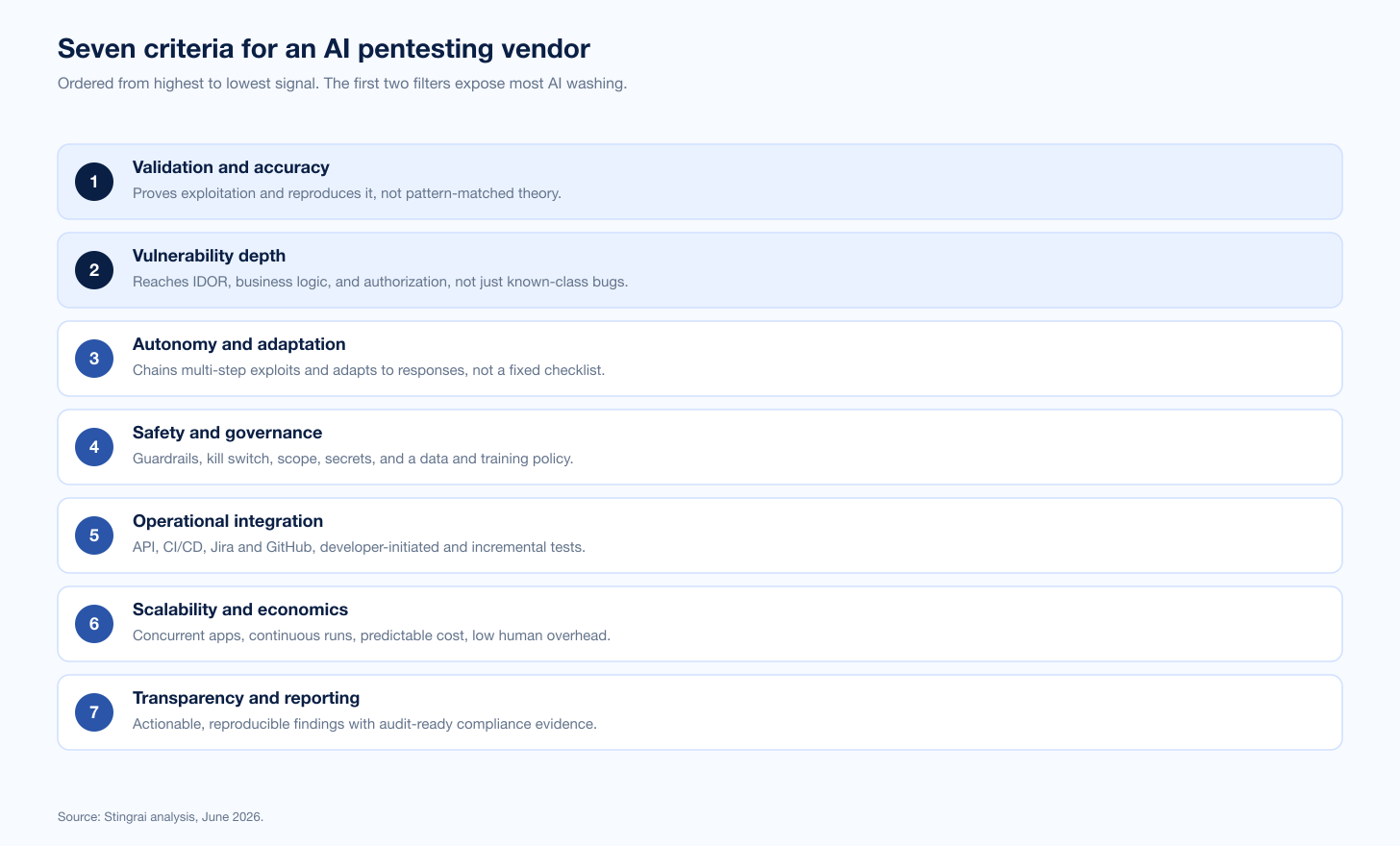
Figure 2: The seven-criterion scorecard for evaluating an AI pentesting vendor, ordered from highest to lowest signal. Source: Stingrai analysis, June 2026.
Where Human Expertise Enters
Every credible AI pentesting program has a place where a human signs off, and the honest vendors tell you exactly where. AI is genuinely strong at breadth, speed, recon, and reading source to flag insecure patterns. It is weak, on its own, at understanding what an application is supposed to do, which is the prerequisite for finding business logic flaws and authorization bypasses, and at the creative, multi-step chaining that turns three medium findings into one critical exploit.
This is why even the most aggressive autonomous example in the market keeps a human in the loop: XBow has its security team review every finding before submission. And it is why only 12% of researchers in HackerOne's 2025 survey believe AI could replace humans entirely. The right framing is not AI versus humans; it is AI for scale plus humans for judgment. The tools to be skeptical of are the ones that hide the human step or claim there isn't one.
What a Strong AI Pentesting Profile Looks Like
The profile that scores well on all seven criteria is an AI-led tool that genuinely reaches the complex classes, paired with human validation. Stingrai's Snipe agent is built to that profile, which is why it is a useful reference point when you run your own evaluation.
On depth, Snipe is purpose-built to hunt the classes generic AI misses: IDOR, business logic flaws, and broken authorization and access control. It is custom-trained on 6,000+ HackerOne disclosure reports plus skills distilled from years of Stingrai's human pentesters' methodology, so it encodes how senior testers actually find these bugs rather than matching signatures. On validation, every Snipe finding is reviewed and extended by senior testers (the human team carries OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, and CRTO, has published 18 CVEs, and rates 5.0/5.0 across 19 Clutch reviews). On integration, Snipe performs black-box dynamic testing and white-box code review, generates AutoFix pull requests, and runs as a PR-gating check on every pull request to block vulnerable code at merge time. Stingrai is a firm-level CREST-accredited penetration testing service provider, founded in 2021 and headquartered in Toronto with a London office, and its output supports your SOC 2, ISO 27001, HIPAA, PCI DSS 4.0, NIST SP 800-53 and 800-171, DORA, and NIS2 compliance evidence. Packages are published transparently at stingrai.io/pricing.
For a side-by-side on how AI and traditional testing compare, read traditional pentesting vs AI pentesting. For the always-on delivery model, see continuous PTaaS explained and the full Stingrai service line.
Frequently Asked Questions
How do I evaluate an AI pentesting vendor in 2026?
Score the vendor on seven criteria: validation and accuracy, vulnerability depth, autonomy and adaptation, safety and governance, operational integration, scalability and economics, and transparency and reporting. Lead with validation (does it prove exploitation or just flag a pattern?) and depth (does it reach IDOR, business logic, and authorization, or stop at known-class bugs?). Ask for resolved, exploitable findings rather than submission counts, because volume is the metric most likely to mislead you.
What is AI washing in penetration testing?
AI washing is marketing a conventional scanner or checklist tool as autonomous, AI-driven offensive security. The tell is that the tool theorizes vulnerabilities from pattern matches rather than proving them exploitable and reproducing them. The fastest way to detect it is to ask for the false-positive rate, reproducible proof of a complex finding (IDOR or business logic, not just XSS), and a clear description of what the AI does versus what a human does.
Can AI pentesting find business logic and IDOR vulnerabilities?
Most generic AI tools cannot, because those classes require understanding what an application is supposed to do rather than matching a signature, which is why autonomous agents skew toward fingerprintable bugs like XSS and SQL injection. A purpose-built tool can. Stingrai's Snipe agent is trained specifically to hunt IDOR, business logic, and broken authorization, and its findings are validated by senior testers, so depth in these classes should be a hard requirement in any evaluation.
Is submission volume a good measure of an AI pentesting tool?
No. Submission volume and leaderboard rank are vanity metrics. When XBow's autonomous agent topped HackerOne's US leaderboard it submitted nearly 1,060 reports, yet only 130 were resolved and 208 were duplicates. The honest measures are resolution rate, false-positive rate, and the severity and class of validated findings. Ask for those numbers, not the headline count.
Should AI replace human penetration testers?
Not for the high-impact work. AI is strong at breadth, speed, recon, and code review, but business logic, authorization bypasses, and creative multi-step exploit chains still require human judgment. Only 12% of researchers in HackerOne's 2025 survey believe AI could replace humans entirely, and even the most autonomous tools keep humans reviewing findings before they ship. The strongest model is AI-led discovery validated and extended by senior testers.
What governance controls should an AI pentesting tool have?
Require customizable guardrails, a kill switch, scope and testing-hour controls, secure handling of secrets and credentials, and an explicit policy on data retention and whether your data is used to train the vendor's models. These are the controls your security and legal teams will use to approve or block the purchase, so confirm them in writing before you run a proof of concept.
References
XBow. The road to Top 1: How XBow did it. 2025. https://xbow.com/blog/top-1-how-xbow-did-it. Documents XBow's autonomous agent reaching the top of HackerOne's US leaderboard with nearly 1,060 submissions, of which 130 were resolved, 303 triaged, and 208 duplicates, with disclosed findings clustered in fingerprintable classes and human review of every finding before submission.
Cobalt. Pentester Profile Report 2026. 2026. https://itbrief.asia/story/survey-shows-pentesters-favour-ptaas-over-bug-bounties. Anonymous survey of 198 Cobalt Core offensive-security professionals; 58% rank human-led PTaaS as the most effective model for uncovering complex vulnerabilities, while just 1% pick AI-only scanning.
Cobalt. State of Pentesting 2025 Report. 2025. https://www.cobalt.io/blog/key-takeaways-state-of-pentesting-report-2025. Aggregates ten years of pentest data and a survey of 450 practitioners; reports a 37-day median time to resolve serious findings, 31% of serious findings never fixed, and that 72% of practitioners rank AI attacks as their top worry.
Verizon. 2025 Data Breach Investigations Report (DBIR). 2025. https://www.verizon.com/business/resources/reports/dbir/. Analyzed over 22,000 incidents and 12,000 confirmed breaches; reports a 34% year-over-year rise in vulnerability exploitation as an initial access vector and stolen credentials in 88% of basic web application attacks.
Stingrai. PTaaS and Offensive Security Services. 2026. https://www.stingrai.io/ptaas. Firm-level CREST-accredited penetration testing service provider whose Snipe AI agent hunts IDOR, business logic, and authorization flaws, generates AutoFix pull requests, and runs as a PR-gating check, with findings validated and extended by senior testers.
Evaluating AI pentesting for your stack? Explore Stingrai PTaaS, the full service line, and transparent pricing.


