
Traditional penetration testing and AI penetration testing are usually framed as a contest between depth and speed, and that framing is mostly right but incomplete. Human-led testing brings business context and the judgment to chain a multi-step exploit, but a typical engagement takes weeks and describes the application only as it existed on the day of testing. Generic AI testing inverts that: it is fast, broad, and continuous, but on its own it clusters around the bugs a machine can fingerprint and misses the ones that require understanding what an application is supposed to do. The gap is not a marketing talking point; it is measured. In the Cobalt Pentester Profile Report 2026, a survey of 198 vetted offensive-security professionals, only 1% ranked AI-only scanning the most effective model for uncovering high-impact, exploitable vulnerabilities, against 58% for human-led PTaaS.
The most-cited autonomous example makes the same point with its own numbers. When XBow's agent reached the top of HackerOne's US leaderboard it submitted nearly 1,060 vulnerabilities, but only 130 were resolved, and its disclosed findings clustered in fingerprintable classes such as RCE, SQL injection, XXE, path traversal, SSRF, and cross-site scripting, per XBow's write-up. The 2026 update worth internalizing is this: "AI cannot do business logic" is true of generic AI, not of all AI. Purpose-built AI now reaches those complex classes, which changes the comparison and the conclusion. This guide compares the two approaches in full and shows where the real frontier is.
TL;DR: Traditional vs AI Pentesting in 2026
Traditional pentesting is deep and context-aware but slow (weeks) and point-in-time. Best for complex applications, exploit chaining, and compliance depth.
Generic AI pentesting is fast, broad, and continuous but skews to known-class, fingerprintable bugs. On its own it misses IDOR, business logic, and broken authorization.
The gap is measured. Only 1% of pentesters rank AI-only scanning most effective for high-impact bugs, versus 58% for human-led PTaaS, per the Cobalt Pentester Profile Report 2026.
Volume is not value. XBow's leaderboard run submitted ~1,060 findings but only 130 were resolved, per XBow.
"AI cannot do business logic" describes generic AI. Purpose-built AI now reaches IDOR, business logic, and authorization classes.
The winning model is purpose-built AI plus human validation. Stingrai's Snipe hunts the complex classes generic AI misses, generates AutoFix pull requests, runs as a PR-gating check, and is validated by senior testers.
Key Takeaways
Depth and speed are the axis, but coverage is the real story. The traditional-vs-AI debate usually argues over time and cost. The decisive question is which vulnerability classes each model actually reaches, because that is where breaches happen.
Generic AI's blind spot is structural, not temporary. Fingerprintable bugs have signatures; business logic and authorization flaws require understanding intent. That is why autonomous agents skew toward XSS and injection, and why the gap will not close by adding more scanning volume.
Submission volume is a vanity metric. A four-figure submission count or a leaderboard rank says nothing about whether findings are real, novel, and fixed. Resolution rate and validated severity are the honest measures.
Purpose-built AI changes the conclusion. A tool trained specifically to hunt IDOR, business logic, and authorization, on real disclosure data and senior-tester methodology, reaches classes generic scanners cannot, which is exactly the frontier this comparison should focus on.
Humans still close the loop. Even the most autonomous tools keep humans reviewing findings, and only 12% of researchers in HackerOne's 2025 survey believe AI could replace humans entirely. The strongest programs are AI-led discovery validated and extended by senior testers.
What Is Traditional Penetration Testing?
Traditional penetration testing is a human-led, point-in-time assessment. Skilled testers scope a target, manually probe it, attempt to exploit what they find, and deliver a report. Its defining strength is judgment: a human understands what an application is for, can reason about how a feature should behave versus how it does behave, and can chain three medium-severity weaknesses into one critical exploit the way a real attacker would. That is why traditional testing is unmatched for business logic flaws, complex authorization bypasses, and multi-step attack chains.
Its weaknesses are speed and recency. A thorough engagement often runs for weeks, and the result is a snapshot: it describes the application as it existed on the testing dates, which may be many releases stale by the time the report is read. In a world where software ships continuously, a once- or twice-a-year test leaves a standing window open between assessments. The Verizon 2025 DBIR, which analyzed over 22,000 incidents and 12,000 confirmed breaches, found vulnerability exploitation as an initial access vector rose 34% year over year, which is precisely the window a point-in-time cadence cannot govern.
What Is AI Penetration Testing?
AI penetration testing uses machine reasoning to automate offensive testing: enumerating attack surface, generating and mutating payloads, attempting exploits, and drafting findings, often continuously rather than on a calendar. Its strengths are the mirror image of traditional testing's weaknesses. It is fast, it runs the same checks consistently every time, it scales to many applications at once, and it can re-test on every change so a newly introduced weakness is caught in days, not at the next annual assessment.
Generic AI's weakness is depth. On its own, a model is strong on the bugs it can fingerprint and weak on the bugs that require understanding intent. Autonomous agents reliably surface reflected XSS, SQL injection, SSRF, and known-CVE exposure, the classes with recognizable signatures, but business logic, IDOR, and broken authorization sit outside that pattern-matching comfort zone. This is the honest basis for the common claim that AI cannot do business logic. The crucial qualifier, explored below, is that the claim describes generic AI, and purpose-built AI is a different proposition.
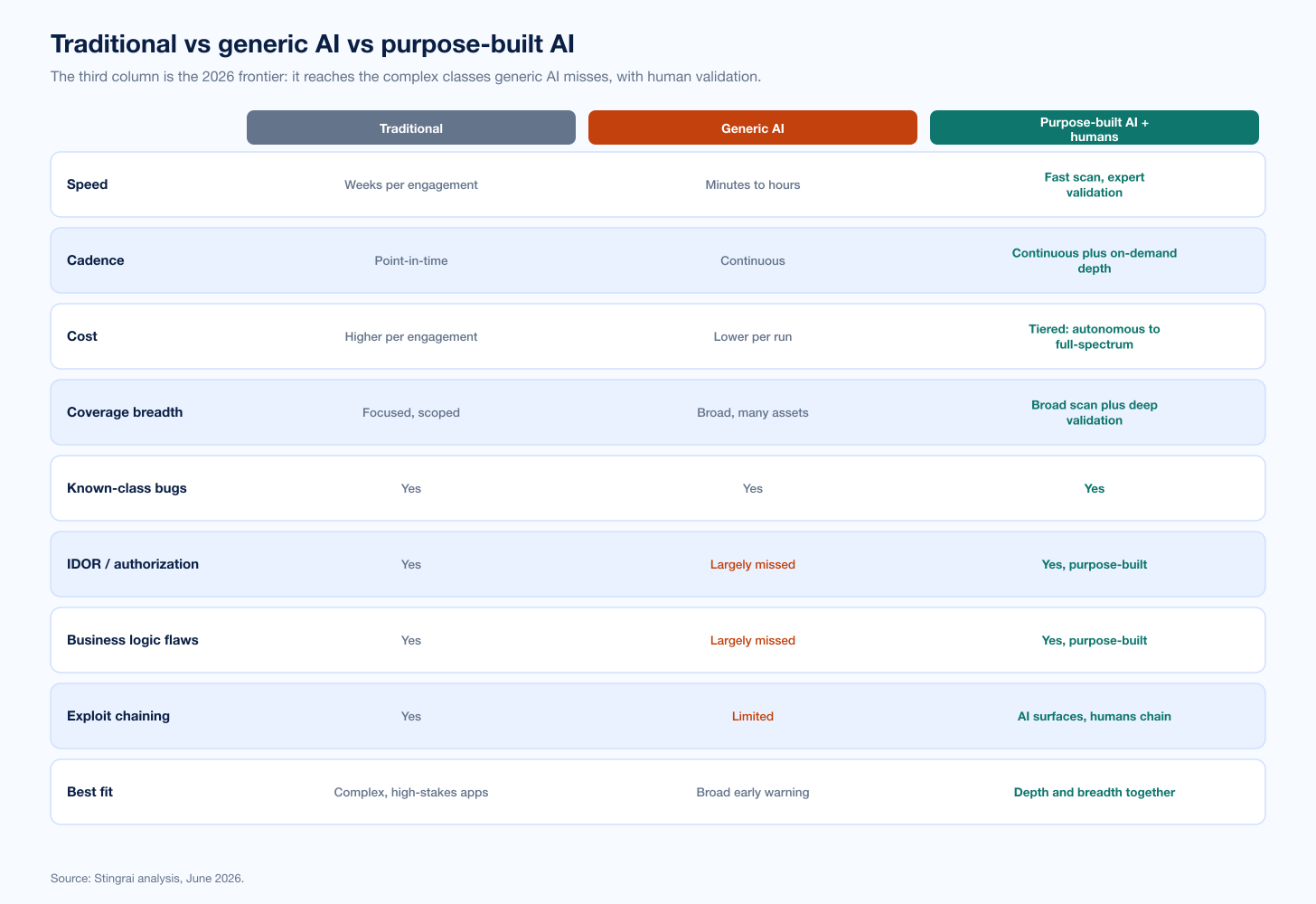
Figure 1: Traditional pentesting, generic AI pentesting, and purpose-built AI plus humans, compared across speed, cost, coverage, depth, business logic, and best fit. Source: Stingrai analysis, June 2026.
Traditional vs AI Pentesting: The Comparison Table
Dimension | Traditional pentesting | Generic AI pentesting | Purpose-built AI + humans |
|---|---|---|---|
Speed | Weeks per engagement | Minutes to hours | Fast scan, expert validation |
Cadence | Point-in-time | Continuous | Continuous plus on-demand depth |
Cost | Higher per engagement | Lower per run | Tiered: autonomous to full-spectrum |
Coverage breadth | Focused, scoped | Broad, many assets | Broad scan plus deep validation |
Known-class bugs | Yes | Yes | Yes |
IDOR / authorization | Yes | Largely missed | Yes, purpose-built |
Business logic flaws | Yes | Largely missed | Yes, purpose-built |
Exploit chaining | Yes | Limited | AI surfaces, humans chain |
Best fit | Complex, high-stakes apps | Broad early warning | Depth and breadth together |
The table reframes the debate. Traditional and generic AI are genuine opposites, depth versus speed, and if those were the only options the honest advice would be to run both. But the third column is the actual 2026 frontier: a purpose-built AI tool that reaches the complex classes generic AI misses, paired with humans who validate exploitability and chain multi-step attacks. That column does not split the difference; it captures the strengths of both.
Why Generic AI Misses Business Logic and IDOR
It is worth being precise about why generic AI struggles with these classes, because the reason determines whether the limitation is fixable. A business logic flaw is a gap between what an application is supposed to allow and what it actually allows: a checkout that lets you apply a coupon an unlimited number of times, a workflow that lets you skip a payment step, an API that lets one user read another user's records (IDOR). None of these has a signature. There is no malformed string to match, because every request is individually well-formed. Finding them requires a model of intent, an understanding of the roles, states, and rules the application is meant to enforce.
Generic AI scanners are built to recognize patterns, so they excel where a pattern exists and stall where it does not. That is the structural reason autonomous agents skew toward fingerprintable bugs, and it is why simply running more scans does not close the gap. The fix is not more volume; it is training a tool specifically on how these bugs are actually found. That is the difference between a generic scanner and a purpose-built agent, and it is the crux of the 2026 comparison.
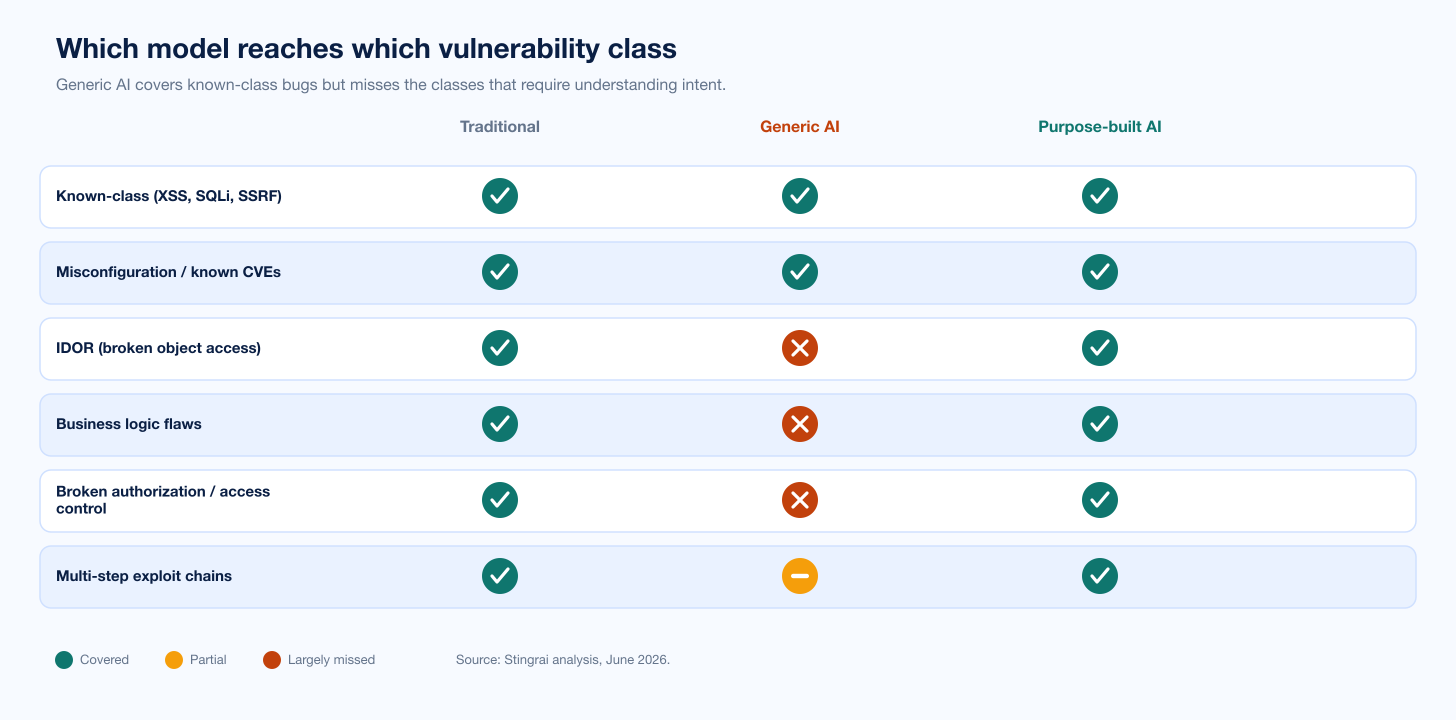
Figure 2: Which vulnerability classes each model reaches. Generic AI covers known-class bugs but largely misses IDOR, business logic, and broken authorization, the classes traditional testing and purpose-built AI both reach. Source: Stingrai analysis, June 2026.
The 2026 Frontier: Purpose-Built AI Plus Humans
The conclusion that AI cannot do business logic is a snapshot of generic tools, and it is already out of date. A purpose-built agent that is trained on real disclosure data and senior-tester methodology reaches the complex classes that signature scanners miss. That is exactly what Stingrai's Snipe was built to do, which is why it belongs in the third column rather than the second.
Snipe is custom-trained on 6,000+ HackerOne disclosure reports plus skills distilled from years of Stingrai's human pentesters' methodology, so it encodes how senior testers actually find IDOR, business logic, and broken authorization, not just how to match a known signature. It performs both black-box dynamic testing and white-box code review, generates AutoFix pull requests, and runs as a PR-gating check on every pull request to block vulnerable code at merge time. That is continuous, AI-driven depth in the developer loop. The human layer then does what humans do best: senior testers validate Snipe's findings, rule out false positives, and extend coverage into the multi-step, cross-environment chaining that no tool closes alone.
Stingrai is a firm-level CREST-accredited penetration testing service provider, founded in 2021 and headquartered in Toronto with a London office. The team has published 18 CVEs, carries OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, and CRTO certifications, and holds a 5.0/5.0 rating across 19 Clutch reviews. Its output supports your SOC 2, ISO 27001, HIPAA, PCI DSS 4.0, NIST SP 800-53 and 800-171, DORA, and NIS2 compliance evidence, and packages are published transparently at stingrai.io/pricing, from an autonomous Snipe assessment to a hybrid Snipe-plus-experts engagement to an always-on enterprise program.
To evaluate AI pentesting tools systematically, read the AI pentesting evaluation guide. For the always-on delivery model, see continuous PTaaS explained and the full Stingrai service line.
Frequently Asked Questions
What is the difference between traditional and AI penetration testing?
Traditional penetration testing is human-led and point-in-time: skilled testers manually probe a target, exploit what they find, and deliver a report over a period of weeks. AI penetration testing uses machine reasoning to automate testing continuously, at speed and scale. Traditional testing wins on depth and business context; generic AI wins on speed and breadth. The 2026 development is purpose-built AI that reaches the complex classes generic AI misses, paired with human validation.
Can AI penetration testing find business logic and IDOR vulnerabilities?
Generic AI scanners largely cannot, because those classes have no signature to match; finding them requires understanding what an application is supposed to allow. Purpose-built AI can. Stingrai's Snipe agent is trained specifically on real disclosure data and senior-tester methodology to hunt IDOR, business logic, and broken authorization, and its findings are validated by human testers. So the accurate statement is that generic AI misses these classes, not that all AI does.
Is AI pentesting better than traditional pentesting?
Neither is strictly better; they have opposite strengths. Traditional testing is deeper and context-aware but slow and point-in-time, while generic AI is fast and continuous but shallow on complex classes. The strongest model in 2026 is not one or the other but purpose-built AI for continuous, deep discovery validated and extended by senior testers, which captures the strengths of both. Only 1% of pentesters rank AI-only scanning most effective for high-impact bugs, per the Cobalt Pentester Profile Report 2026.
How much does AI pentesting cost compared to traditional?
Generic AI runs are cheaper per execution than a traditional engagement, which typically costs more because it is human-intensive and runs for weeks. The most cost-effective approach is tiered: an automated assessment for breadth at the low end, a hybrid engagement that adds expert validation and exploit chaining for depth, and an enterprise program for full attack-surface coverage. Stingrai publishes its autonomous, hybrid, and enterprise packages transparently at stingrai.io/pricing.
Does AI pentesting replace human penetration testers?
No, it changes what the humans focus on. AI handles breadth, speed, recon, and continuous re-testing, which frees senior testers to concentrate on validation and the creative, multi-step exploit chaining that machines do not close on their own. Even the most autonomous tools keep humans reviewing findings before they ship, and only 12% of researchers in HackerOne's 2025 survey believe AI could replace humans entirely.
What is the most effective penetration testing model in 2026?
The most effective model is purpose-built AI plus human validation: an AI agent that reaches the complex classes generic scanners miss, running continuously and in the developer loop, with senior testers validating findings and chaining multi-step attacks. This captures generic AI's speed and breadth and traditional testing's depth and context at the same time. Stingrai delivers this with the Snipe agent validated by its human team; see Stingrai PTaaS.
References
Cobalt. Pentester Profile Report 2026. 2026. https://itbrief.asia/story/survey-shows-pentesters-favour-ptaas-over-bug-bounties. Anonymous survey of 198 Cobalt Core offensive-security professionals; 58% rank human-led PTaaS as the most effective model for uncovering complex vulnerabilities, while just 1% pick AI-only scanning.
XBow. The road to Top 1: How XBow did it. 2025. https://xbow.com/blog/top-1-how-xbow-did-it. Documents XBow's autonomous agent reaching the top of HackerOne's US leaderboard with nearly 1,060 submissions, of which 130 were resolved and 208 were duplicates, with disclosed findings clustered in fingerprintable classes such as RCE, SQL injection, XXE, path traversal, SSRF, and cross-site scripting.
Cobalt. State of Pentesting 2025 Report. 2025. https://www.cobalt.io/blog/key-takeaways-state-of-pentesting-report-2025. Aggregates ten years of pentest data and a survey of 450 practitioners; reports a 37-day median time to resolve serious findings, 31% of serious findings never fixed, and that 72% of practitioners rank AI attacks as their top worry.
Verizon. 2025 Data Breach Investigations Report (DBIR). 2025. https://www.verizon.com/business/resources/reports/dbir/. Analyzed over 22,000 incidents and 12,000 confirmed breaches; reports a 34% year-over-year rise in vulnerability exploitation as an initial access vector and stolen credentials in 88% of basic web application attacks.
Stingrai. PTaaS and Offensive Security Services. 2026. https://www.stingrai.io/ptaas. Firm-level CREST-accredited penetration testing service provider whose Snipe AI agent is purpose-built to hunt IDOR, business logic, and authorization flaws, generates AutoFix pull requests, and runs as a PR-gating check, with findings validated and extended by senior testers.
Want depth and breadth in one program? Explore Stingrai PTaaS, the full service line, and transparent pricing.


