
Agentic AI is now a daily tool in pentest engagements, not a research curiosity. HackerOne's 9th annual Hacker-Powered Security Report (October 1, 2025) measured 70 percent of surveyed researchers using AI tools in their workflow, valid prompt-injection report volume up 540 percent year over year, and customer bug-bounty programs with AI in scope up 270 percent to 1,121 distinct programs in 2025. Total HackerOne bug-bounty payouts hit US$81M (+13 percent YoY), with autonomous agents alone submitting 560 or more valid reports. The same survey measured 58 percent of researchers saying AI misses business logic or chained exploits, and only 12 percent believing AI could replace them. Two-thirds expect AI to enhance their work rather than replace it.
This post is the Stingrai field-report read from the PTaaS floor. Three forces define agentic AI in pentesting in 2026. First, machine throughput beats human attention on reconnaissance, payload generation, known-pattern matching, and triage; Anthropic's GTG-1002 disclosure (November 13, 2025) documented an end-to-end campaign with 80 to 90 percent AI-executed work and only 4 to 6 critical human decision points across roughly 30 global targets. Second, AI still hallucinates: Anthropic stated verbatim that Claude "occasionally hallucinated credentials or claimed to have extracted secret information that was in fact publicly-available." Third, capability is doubling fast: the UK AI Safety Institute measured the 80 percent-reliability cyber time horizon doubling every 4.7 months since late 2024, down from an earlier 8-month estimate, with the Claude Mythos Preview model completing both AISI cyber ranges for the first time. For CISOs, security buyers, and engineering leaders evaluating AI-augmented pentest vendors in 2026, the question is not whether AI belongs in the workflow. It is where the line between agent autonomy and human oversight actually sits.
This post is the Stingrai research team's canonical 2026 reference for agentic AI in pentesting. Forty-plus verified figures across seventeen named primary publishers: HackerOne, Bugcrowd, Anthropic, OpenAI, Microsoft, CrowdStrike, Mandiant, IBM, MITRE ATLAS, OWASP, NIST, UK AISI, METR, the World Economic Forum, plus published CVE advisories and Stingrai's own service-page descriptions. Lead data is full-year 2025 telemetry, the freshest available; primary publishers have not yet released full-year 2026 reports as of May 2026. Every numeric claim links back to its primary publisher so any figure can be audited inline.
Stingrai is a Toronto-headquartered offensive-security firm founded in 2021 with a London, UK office. Stingrai Inc is a CREST-accredited Penetration Testing service provider (firm-level accreditation, separate from individual CREST CRT certifications held by team members). The team has 18 published CVEs (Ivan Spiridonov 10, Moaaz Taha 5, Victor Villar 3), 5.0 out of 5.0 across 19 Clutch reviews, and team certifications spanning OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO, GCPN, CRTE, and eWPTX. The internal AI pentest agent, Snipe, is a web-app focused agent trained on more than 6,000 HackerOne disclosures; it performs both black-box dynamic testing and white-box source-code review, generates AutoFix pull requests for the vulnerabilities it identifies, and can run as a PR-gating check that blocks vulnerable code from being merged. Snipe is referenced throughout this post as one running example of a production agentic AI deployment, not as the centerpiece. The thesis below is vendor-neutral; if you delete every Snipe reference from this post, the analysis still stands.
TL;DR: ten labeled claims
Researcher AI adoption (2025): 70 percent of HackerOne researchers use AI tools in their workflow today; 58 percent say AI misses business logic or chained exploits; only 12 percent believe AI could replace them (HackerOne 9th HPSR).
AI vulnerability reports (2025): +210 percent YoY valid AI vulnerability reports; +540 percent valid prompt-injection reports; 560 or more valid reports from autonomous agents (HackerOne 9th HPSR press release).
AI program adoption (2025): +270 percent YoY customer programs with AI in scope, totaling 1,121 distinct programs; total HackerOne payouts US$81M (+13 percent YoY); US$3B in breach losses avoided across HackerOne programs in 2025 (HackerOne 9th HPSR press release).
Anthropic GTG-1002 (Nov 13 2025): First publicly documented AI-orchestrated cyber espionage campaign at scale. 80 to 90 percent AI-executed across roughly 30 targets. 4 to 6 critical human decision points per campaign. Detection mid-September 2025, containment in roughly 10 days (Anthropic, Nov 2025).
Anthropic on AI limits, verbatim: "Claude didn't always work perfectly. It occasionally hallucinated credentials or claimed to have extracted secret information that was in fact publicly-available." (Anthropic, Nov 2025).
UK AISI capability doubling (May 13 2026): 80 percent-reliability cyber time horizon doubles every 4.7 months since late 2024 (down from earlier 8-month estimate). Token budget per task 2.5M. Mythos Preview is the first model to complete both AISI cyber ranges including "Cooling Tower" (AISI, May 2026). METR independently measures 4.2 months for software-engineering time horizons (METR, Jan 2026).
CrowdStrike Charlotte AI (Feb–Aug 2025 telemetry): Triages security detections with over 98 percent accuracy; eliminates more than 40 hours per week of analyst work per SOC on average. Operates within a "bounded autonomy" model (CrowdStrike, Feb 2025).
Microsoft Security Copilot (Phishing/Alert Triage Agent): 77 percent more accurate verdicts in independent randomized controlled studies; 78 percent faster alert triage; 6.5x more malicious emails identified vs manual analysis; Phishing Triage Agent helps SOC analysts detect malicious emails up to 550 percent faster (Microsoft Learn).
IBM Cost of a Data Breach 2025: Attacker AI in 1 in 6 (16 percent) of breaches; AI-phishing 37 percent of attacker-AI cases; AI-deepfake 35 percent. Defender-AI users saved US$1.9M per breach and 80 days faster identification. 97 percent of organizations with an AI-related incident lacked proper AI access controls (IBM, Jul 2025).
OWASP LLM06:2025 Excessive Agency: Splits into Excessive Functionality, Excessive Permissions, and Excessive Autonomy. Eight prevention controls including human approval for consequential actions, individual user contexts, and downstream authorization (OWASP, 2025).
Key takeaways
Agentic AI raised the floor of pentesting throughput, not the ceiling of pentest quality. Researchers and PTaaS operators alike offload pattern-known work to AI agents. The work that determines whether a customer report is worth the engagement fee, business-logic discovery, chained exploit reasoning, real-world impact framing, sits with senior pentesters, and the HackerOne 9th HPSR survey data confirms this is the researcher consensus, not a Stingrai opinion.
AI agents hallucinate, and the primary publisher of the most prominent AI-orchestrated campaign says so out loud. Anthropic's GTG-1002 disclosure named hallucinated credentials and false claims of access as recurring artifacts even in a frontier-model campaign. Pentest agents in 2026 require human re-validation on every finding before it reaches a customer report.
The capability ceiling is rising on a sub-five-month doubling schedule. UK AISI's May 13, 2026 evaluation measured the 80 percent-reliability cyber time horizon doubling every 4.7 months. Pentest workflows scoped in 2025 will not stay scoped correctly in 2027. Continuous-coverage PTaaS engagements absorb this drift better than annual-pentest scopes.
The defender side already proved the bounded-autonomy model works. CrowdStrike Charlotte AI and Microsoft Security Copilot's Phishing and Alert Triage Agents both ship measurable accuracy and throughput gains within a strict human-approval gate. The same architectural pattern, code-enforced scope plus explicit human review gates plus per-finding labeling, is the right pattern for offensive AI in 2026.
Buyers should evaluate AI-augmented pentest vendors against verifiable artifacts, not marketing language. Twelve evaluation questions, from "is the AI agent named and version-tracked" to "is the scope fence enforced by code or by policy" to "what is the liability posture for AI work", give buyers the audit trail to triangulate vendor claims. Vendors that cannot answer all twelve in writing are not yet ready for the 2026 attack surface.
The Stingrai field-report position: agentic AI is a force multiplier on the senior pentester, not a substitute for them. This is not a contrarian take. It matches HackerOne's researcher survey (58 percent miss business logic, 12 percent could be replaced), Anthropic's own GTG-1002 admission about hallucinations, AISI's published time-horizon data, and the bounded-autonomy architectures shipping at defender-side vendors. The bench of senior pentesters is still the quality ceiling. AI extends the floor.
Methodology
Date cutoff: May 26, 2026. Lead data anchoring this post is full-year 2025 telemetry from named primary publishers, with several primary publishers releasing 2026 calendar-Q1 updates that are labeled as such in the body. Where multiple primary publishers report compatible figures, the publisher whose methodology window most directly matches the claim is cited.
Stats that could not be reached on at least one verification pass against a named primary publisher were dropped rather than estimated. Every figure in this post links back to its primary publisher inline; the references section enumerates every primary publisher cited.
This post is original Stingrai research. It is not a response to or commentary on any other vendor's publication on agentic AI in pentesting. Other vendors are cited only where their data point is genuinely additive or where they constitute the public record of a particular disclosure.
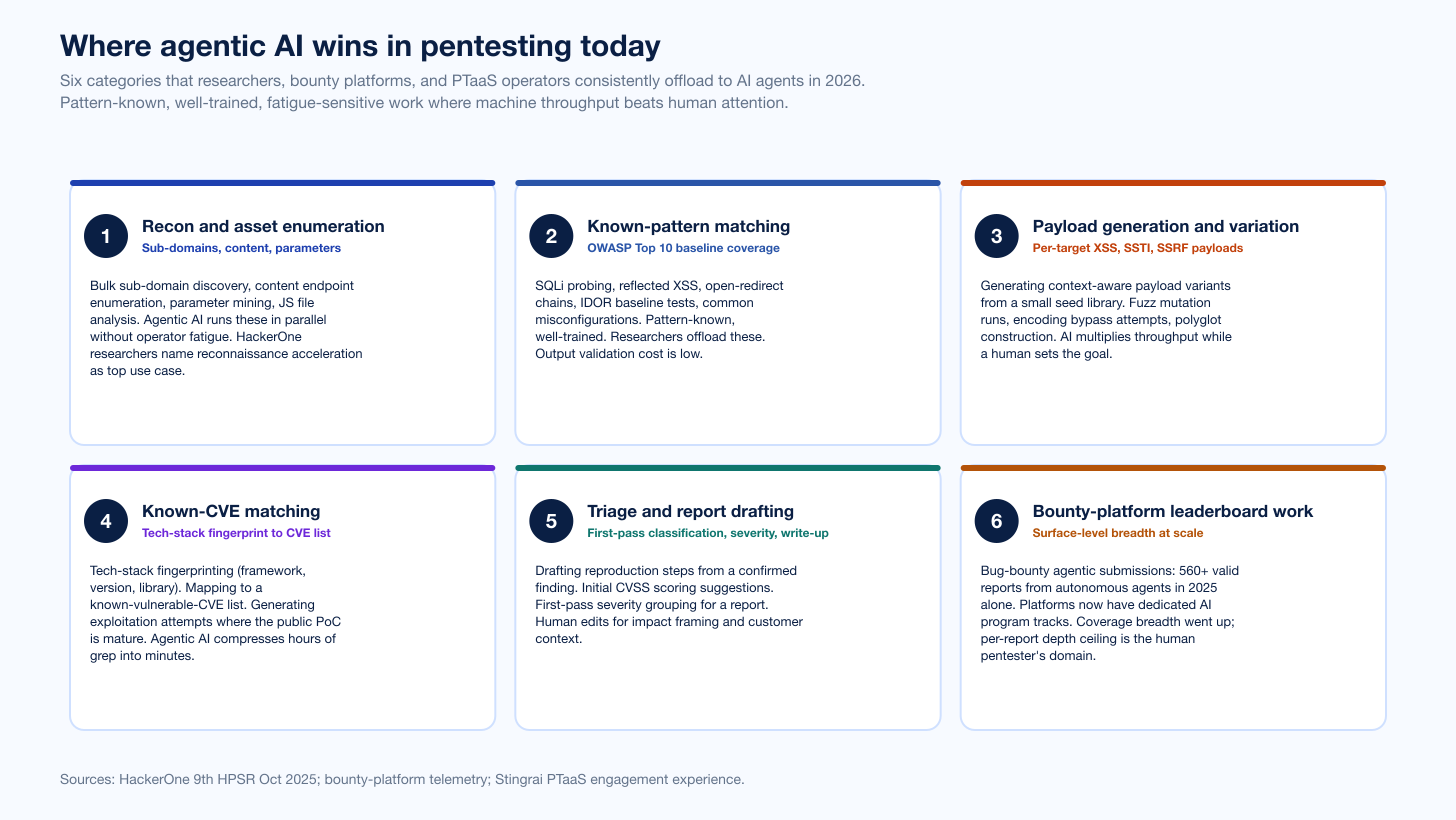
Figure 1: The six categories where researchers, bounty platforms, and PTaaS operators consistently offload work to AI agents in 2026. Pattern-known, well-trained, fatigue-sensitive work where machine throughput beats human attention. Sources: HackerOne 9th HPSR Oct 2025; bounty-platform telemetry; Stingrai PTaaS engagement experience.
Where agentic AI wins in pentesting today
Six categories carry the agentic-AI win column in 2026. Each one is pattern-known, well-trained, fatigue-sensitive work where the machine wins on throughput without the human pentester losing the impact story.
1. Reconnaissance and asset enumeration
The most consistent agentic-AI win in 2026 pentest workflows is reconnaissance. Sub-domain discovery, content endpoint enumeration, parameter mining, JavaScript file analysis, and DNS history pulls all run in parallel without operator fatigue. HackerOne's 2025 researcher signals post explicitly named "accelerate reconnaissance" as the top researcher AI use case. Bounty platforms now ship automated recon as a first-class agent capability. The Stingrai field-report read matches: recon is where Snipe's value compounds most consistently across engagement weeks.
2. Known-pattern matching
OWASP Top 10 baseline coverage, SQL injection probing on identified parameters, reflected XSS attempts, open-redirect chains, baseline IDOR tests, and common-misconfiguration sweeps are textbook work. Researchers offload them. The validation cost is low because the patterns are known; either the probe returns the expected response or it does not. HackerOne's data showed valid IDOR reports up 29 percent in 2024 and Improper Access Control reports up 18 percent year over year, with IDOR specifically up 116 percent over five years; agentic AI is the mechanism that turned this volume increase into a sustainable researcher-economics model.
3. Payload generation and variation
Context-aware payload generation, encoding-bypass attempts, polyglot construction, and per-target payload variation from a seed library are categories where AI compresses what was hours of manual fuzz-mutation work into minutes. A human pentester sets the goal and inspects the survivors; the agent does the multiplication. This is also one of the categories where prompt-injection regression testing matters most: a payload-generation agent that ingests target HTML output is a candidate for indirect prompt injection from the target itself.
4. Known-CVE matching
Tech-stack fingerprinting, framework and library version detection, and mapping the fingerprint to a known-vulnerable-CVE list with mature public PoCs is mechanical work. Agents do it well. The work that's NOT mechanical is deciding whether the fingerprint is accurate, whether the PoC translates to the customer's environment, and whether the exploit path actually reaches an exploitable target. The mechanical half is the agent's; the judgment half is the human pentester's.
5. Triage and report drafting
First-pass classification of agent findings, draft reproduction steps from a confirmed finding, initial CVSS scoring suggestions, and first-pass severity grouping inside a report all save a senior pentester time when an agent does them first. Final severity, customer-impact framing, and remediation guidance stay with the pentester. The HackerOne 2025 researcher signals post named "AI output remains inconsistent without human oversight" and reports written entirely by AI tend to be "polished but technically shallow." The pattern matches Stingrai's engagement read: AI-drafted reports without human re-write are unsigned.
6. Bounty-platform leaderboard work
Bug-bounty surface-level breadth went up in 2025. HackerOne's 9th HPSR press release named 560 or more valid reports submitted by autonomous agents in 2025 alone, alongside the +270 percent YoY rise in customer programs with AI in scope. Bounty platforms now have dedicated AI program tracks. Coverage breadth went up; per-report depth ceiling is still the human pentester's domain. The economic incentive on bounty platforms now favors fast surface-level reports, which agents do well, but rewards deeper business-logic findings that humans still own.
Where human pentesters stay critical

Figure 2: The six categories where AI agents reliably underperform or hallucinate. Researcher surveys, primary disclosures, and Stingrai engagement experience converge on the same boundary in 2026. Sources: HackerOne 9th HPSR Oct 2025; Anthropic GTG-1002 Nov 13 2025; Stingrai PTaaS engagement experience.
Six categories sit on the human side of the line in 2026. Each one is where senior pentesters earn the engagement fee.
1. Novel business-logic bugs
HackerOne's 9th HPSR measured 58 percent of researchers saying AI misses business logic or chained exploits. The pattern is intuitive when you look at the bugs in question. Multi-step workflow abuse. Pricing-engine race conditions. Coupon-stacking. Role-promotion via partial state updates. Authentication-state confusion across federated providers. The bug lives in the application semantics, not in the OWASP Top 10. The customer's product team often does not know about the bug until a pentester walks them through the chain. Agents that don't know what the application is supposed to do cannot reason about what it should not do.
2. Chained exploit reasoning
Multi-step kill chains that cross application boundaries are the second largest gap. Recon to auth bypass to IDOR to CSRF to privilege escalation, with each step shifting the privilege model or the target audience. AI agents lose the thread of the chain across context windows and tool-call sequences. Human senior pentesters keep the impact story coherent across a multi-hour exploit. This is the work that Stingrai's senior pentesters retain ownership of, regardless of how much agent recon ran upfront.
3. False-positive validation
Anthropic's verbatim quote from the GTG-1002 disclosure: "Claude didn't always work perfectly. It occasionally hallucinated credentials or claimed to have extracted secret information that was in fact publicly-available." This is the published primary source on agentic AI limits from the model vendor whose product orchestrated the campaign. Every agent-flagged finding requires human re-validation before it lands in a customer report. The cost of validation is built into Stingrai's PTaaS engagement runbook; the cost of skipping validation is a contested finding that erodes customer trust on the next renewal.
4. Real-world risk and impact framing
A 200-line agent report on a Critical-tagged finding is not customer-actionable without business context. Senior pentesters translate technical impact into board-level severity. The pentester reads the customer's regulatory posture (SOC 2 control mapping, PCI DSS 4.0 scope, HIPAA jurisdiction, ISO 27001 control set), contract terms (which findings are pre-cleared for disclosure, which require pre-publication notice), and insurance exclusions (which finding categories are covered, which are not). AI agents cannot make those judgment calls because the necessary context is in PDFs, contracts, and conversations they were not trained on and should not have access to.
5. Scope and contract judgment
The agent finds an interesting target one CIDR over from the scope, or a sub-domain not listed in the SoW, or a third-party integration that shares authentication with the customer. A senior pentester recognizes the contractual boundary and stops. An agent without a hard-coded scope fence keeps probing. Scope discipline is a judgment call AI does not yet make reliably. The fix is to enforce scope as code in the agent's tool-call allow-list rather than as policy in a documentation file.
6. Customer trust and disclosure
The final report walkthrough, the sit-down with the customer security team, the regulator-aware disclosure timing, and the post-engagement relationship are senior-pentester work. The customer's chief security officer does not want to debrief with an agent. Customer trust is the durable asset that determines whether the next engagement happens. Stingrai's customer-facing model is built around that durability; the PTaaS service emphasizes live-chat collaboration with expert white-hat hackers and a unified dashboard owned by the operator, not by an autonomous agent.
Failure modes specific to agentic pentest agents

Figure 3: Six failure modes where the agent itself becomes the operator's liability. Each maps to OWASP LLM Top 10 v2025 or NIST AI 600-1, and shows up in 2026 PTaaS engagement runbooks as required pre-flight controls. Sources: OWASP LLM Top 10 v2025; MITRE ATLAS v5.4.0; NIST AI 600-1; Anthropic GTG-1002 Nov 13 2025; Stingrai engagement experience.
Six failure modes are specific to running agentic AI inside a pentest engagement. Each one is a published or directly observable risk class as of May 2026, and each one belongs in a vendor's runbook as a required pre-flight control.
1. Prompt injection against the agent itself
The target application is the attacker. Indirect prompt injection inside an HTTP response, an HTML attribute, a JSON payload, or an HTML comment can flip the pentest agent into following the target's instructions instead of the operator's. The technique maps cleanly to OWASP LLM01:2025 Prompt Injection and MITRE ATLAS AML.T0051 LLM Prompt Injection. Anthropic's GTG-1002 disclosure is the canonical example of a campaign-scale prompt-injection problem; the same dynamic occurs in reverse when a pentest agent ingests adversarial target content. Defender control: regression-test indirect prompt injection inside the agent's normal browsing and parsing tool path, not only the input prompt.
2. Scope creep through agent discovery
The agent discovers an adjacent target out of contractual scope (a CIDR neighbor, a sibling sub-domain, a shared third-party integration). Without a strict scope fence, the agent probes it. The operator finds out at report-review time. The liability follows; pentest contracts almost always limit authorization to a named scope, and probing outside it can constitute unauthorized access depending on the jurisdiction. The fix is scope-by-code in the agent's tool-call allow-list: the scope is enforced by the agent's available tools, not by policy text the agent could ignore.
3. Hallucinated CVE IDs and severity inflation
Anthropic's verbatim statement on GTG-1002 covers this directly. Agents invent CVE IDs, mis-attribute exploitation chains, and inflate severity ratings under prompts that reward confident output. The fix is mandatory human re-validation before any finding promotes from the agent's holding queue to the customer report. Stingrai's PTaaS runbook treats this as a release gate, not an optional review step.
4. Agent loops and runaway costs
An agent stuck on a recursive failure burns thousands of model API calls per hour. The cost incident is the SOC's first signal. Operator-side rate limits, per-engagement token budgets, and circuit-breaker logic are now table stakes. The OWASP framing is LLM10:2025 Unbounded Consumption. Defenders who care about Cloud cost discipline care about agentic-AI cost discipline for the same reasons.
5. Tool-call sequence drift
An agent starts on a benign tool-call sequence (HTTP GET, JSON parse). A few steps in, it has chained a write to a shared cache, an internal email, or a CI/CD pipeline trigger. The operator sees the side effect after the fact, not before. The OWASP framing is LLM06:2025 Excessive Agency, with its three root-cause split into Excessive Functionality, Excessive Permissions, and Excessive Autonomy. The defender control is to restrict the agent's tool set to read-only operations during recon and to require human approval before any write tool fires.
6. Data-handling for sensitive findings
Pentest engagements regularly surface customer credentials, internal documents, and PII. An agent that ships these to a third-party model API for processing creates a data-residency and compliance incident waiting to be discovered at audit. The NIST AI 600-1 GenAI Profile names Information Security as one of twelve risk categories. The defender control is explicit data-handling policy on what the agent can send to which external endpoint, plus a redaction step before any tool call that crosses the customer's data boundary. Buyers should ask vendors which external API endpoints the agent talks to, what data classifiers run upstream, and how artifacts are deleted at engagement close.
Human-in-the-loop architectures that work
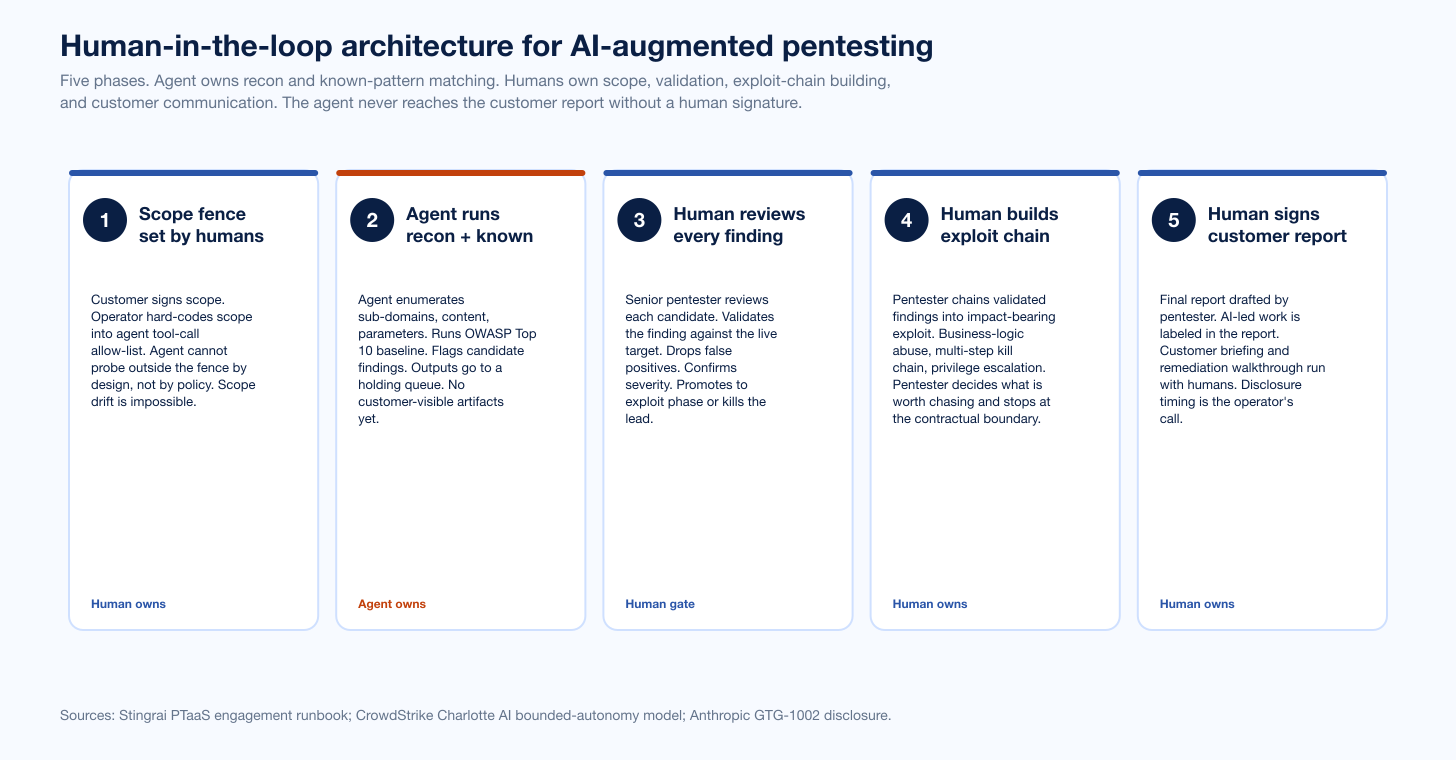
Figure 4: Five-phase human-in-the-loop architecture for AI-augmented pentesting. The agent owns recon and known-pattern matching; humans own scope, validation, exploit-chain building, and customer communication. The agent never reaches the customer report without a human signature. Sources: Stingrai PTaaS engagement runbook; CrowdStrike Charlotte AI bounded-autonomy model; Anthropic GTG-1002 disclosure.
Five phases describe the architecture that actually works in production engagements in 2026. The pattern matches CrowdStrike Charlotte AI's "bounded autonomy" framing and OWASP LLM06's "human approval for consequential actions" prevention control.
Phase 1: Scope fence set by humans
The customer signs the scope. The operator hard-codes the scope into the agent's tool-call allow-list. The agent cannot probe outside the fence by design, not by policy. Scope drift is impossible at the agent layer, not just discouraged by the runbook. This is the difference between "scope as documentation" and "scope as code," and it is the most important architectural decision in the entire pipeline.
Phase 2: Agent runs recon and known classes
The agent enumerates sub-domains, content, and parameters. It runs OWASP Top 10 baseline coverage. It flags candidate findings. All outputs go to a holding queue. No customer-visible artifacts exist yet. This phase is where the throughput win shows up; it is also where prompt-injection regression tests and runaway-cost circuit breakers must already be in place.
Phase 3: Human reviews every finding
A senior pentester reviews each candidate from the holding queue. The reviewer validates the finding against the live target. Drops false positives. Confirms severity. Promotes to exploit phase or kills the lead. This is the gate Anthropic's GTG-1002 disclosure is the canonical argument for; it is also the gate Microsoft Security Copilot's Phishing Triage Agent demonstrates pays off, with the Triage Agent identifying 6.5x more malicious emails than manual analysis under a randomized controlled study while still routing to human review (Microsoft Learn).
Phase 4: Human builds the exploit chain
The pentester chains validated findings into impact-bearing exploits. Business-logic abuse, multi-step kill chains, privilege escalation. The pentester decides what is worth chasing and stops at the contractual boundary. This is the work that the HackerOne 2025 researcher survey found AI misses 58 percent of the time, and where senior pentester time is the irreplaceable input.
Phase 5: Human signs the customer report
The pentester drafts the final report. AI-led work is explicitly labeled in the report so the customer knows where the agent's contribution ended and the human's began. The customer briefing and remediation walkthrough run with the pentester, not the agent. Disclosure timing is the operator's call, not the model's. The agent never reaches the customer report without a human signature on the cover sheet.
The defender side already demonstrated the same architectural pattern works at scale. CrowdStrike Charlotte AI triages security detections with over 98 percent accuracy and eliminates more than 40 hours per week of analyst work per SOC on average, all under a bounded-autonomy model with org-level approval gates. Microsoft Security Copilot Alert Triage Agent delivers 77 percent more accurate verdicts and 78 percent faster triage in randomized controlled studies. The bounded-autonomy pattern is what makes these numbers possible without simultaneously breaking the customer trust model. The offensive side should adopt the same architecture.
Buyer evaluation checklist for AI-augmented pentest vendors

Figure 5: Twelve evaluation questions buyers should put on every AI-augmented pentest vendor RFP in 2026. Vendor-neutral pattern-language for triangulating vendor claims against verifiable artifacts. Sources: OWASP LLM Top 10 v2025; NIST AI 600-1 GenAI Profile; Stingrai PTaaS engagement experience.
The twelve questions below are vendor-neutral. Use them to triangulate any AI-augmented pentest vendor's claims against verifiable artifacts.
1. Is the AI agent named, described, and version-tracked?
A vendor that cannot name and describe the agent they run in a sales call cannot give the customer traceability when a finding is contested. Ask for the agent's name, the training data corpus, the version, and changelog access. Stingrai's internal agent is named Snipe and is trained on more than 6,000 HackerOne disclosures; the version is named on the engagement statement of work.
2. Are human review gates explicit per finding tier?
Each severity tier should have an explicit human-review gate documented in the vendor's runbook. Critical and High findings require dual sign-off in mature vendors. Medium and Low get a single senior review. Informational findings may be agent-released with a labeled disclaimer. Ask to see the runbook.
3. Is the false-positive rate disclosed for AI-tagged findings?
A vendor that has not measured its FP rate has not earned the right to ship AI-tagged findings to a customer. Ask for FP rates by severity tier across the last four engagements. Real numbers vary by vendor and by program; the act of disclosing the number is the signal.
4. Is the scope-fence enforced by code, not policy?
Scope fences enforced by code in the agent's tool-call allow-list survive operator turnover. Scope fences enforced by policy in a runbook do not. Ask the vendor how the fence is enforced, what happens when the agent tries to call an out-of-scope target, and how scope changes are propagated.
5. Are prompt-injection defenses tested for the agent itself?
The target application is the attacker. The vendor should regression-test indirect prompt injection inside the agent's browsing and parsing tools, not only the input prompt. Ask for the regression-test methodology and the cadence (per release, weekly, monthly).
6. Is the data-handling policy explicit for sensitive findings?
Customer credentials, internal documents, and PII surface in nearly every engagement. Ask whether the vendor sends pentest artifacts to third-party model APIs, what data-residency commitments apply, and how artifacts are deleted post-engagement. The answer should include named external endpoints (or the explicit absence of named external endpoints) and a deletion SLA.
7. Does the report distinguish AI-led from human-led work?
A report that conflates AI and human work obscures accountability. Ask for a sample report and confirm AI-led findings are labeled. Without labeling, the customer cannot run their own validation on which findings deserve internal escalation.
8. What is the liability and insurance posture for AI work?
If an agent triggers a side effect (creates a row, sends an email, hits a production endpoint), the contract should state who bears the liability. Ask for the indemnity language and the insurance certificate. AI-augmented work is increasingly priced into cyber-liability and professional-indemnity policies; the vendor should already have the answer.
9. Does the vendor have a public CVE track record?
Published CVEs are external evidence that the vendor's team can find novel bugs that survive peer review. Stingrai's team has 18 published CVEs. Ask vendors for their CVE list, public BSIDES or DEFCON talks, and published research. The track record predicts future engagement quality far better than a sales pitch.
10. Which certifications and compliance frameworks apply?
Team certifications (OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO), engagement methodology alignment (PTES, OWASP Testing Guide v4.0, OWASP API Security Project, NIST SP 800-115), and customer compliance fit (SOC 2, ISO 27001, HIPAA, PCI DSS 4.0). Stingrai's Web App Pentest service page enumerates the methodology alignment publicly.
11. How are agent loops and runaway costs prevented?
A stuck agent can burn thousands of model API calls per hour. Ask the vendor about per-engagement token budgets, per-agent rate limits, and circuit-breaker logic. The answer reveals operational maturity. Mature vendors quote real circuit-breaker thresholds; immature vendors hand-wave.
12. Is regular human-led red-team coverage retained?
AI augments pentest coverage. It does not replace red-team work. Ask whether the vendor retains a separate human-led red-team practice and how often it is invoked relative to the AI-augmented PTaaS cadence. The buyer who only buys AI-augmented PTaaS without periodic human-led red team coverage is leaving the chained-exploit ceiling on the table.
Vendor landscape signals
Two qualitative patterns separate strong AI-augmented PTaaS vendors from weak ones in 2026. They generalize across the vendor list and across geography.
First, strong vendors publish the architecture. They describe the agent, name its capabilities, name its limits, label AI vs human work in the report, and disclose their human-review gating model in writing. Weak vendors describe the agent in marketing language ("our AI does everything a human can") and cannot answer specific questions about the architecture in a sales call. The HackerOne 9th HPSR survey data is the diagnostic: vendors who echo the 70 percent / 58 percent / 12 percent researcher consensus understand the field. Vendors who claim to be the exception have to defend the claim with real numbers, and most cannot.
Second, strong vendors retain a human-led red-team capability alongside the AI-augmented PTaaS cadence. The capability is sometimes called "manual red team," sometimes "deep engagement," sometimes "research-grade testing." The label matters less than the existence. Vendors that point to their published CVEs, conference talks, and named senior pentesters have the bench to handle the work the agents miss. Vendors that cannot are betting on the AI ceiling not catching the human ceiling fast enough to matter, which is a riskier bet than the buyer should accept.
For a wider read on the PTaaS vendor landscape, see Stingrai's 2026 PTaaS providers post, which covers the operator-side market structure that buyers navigate alongside the agentic-AI architecture question.
What this means for security buyers
The practical implication for buyers shopping for AI-augmented pentest vendors in 2026 is a small number of concrete next steps.
Bring the twelve-question checklist to the next vendor RFP. Most vendors will answer eight of twelve in writing on the first pass. The four they avoid are the diagnostic.
Update your pentest scope to include the agentic-AI failure modes. Most engagements scoped before mid-2024 do not include prompt-injection regression testing on internal AI features, scope-by-code enforcement in vendor agents, or explicit data-handling commitments for sensitive findings. Add them.
Demand bounded-autonomy architecture. The bounded-autonomy pattern is what made CrowdStrike Charlotte AI ship 98 percent accuracy and what made Microsoft Security Copilot's Phishing Triage Agent ship 77 percent more accurate verdicts. The offensive side should adopt the same architectural discipline; insist on it.
Pay for human-led red-team coverage at least annually, regardless of how AI-augmented your PTaaS cadence is. The chained-exploit ceiling is the human pentester's, and skipping that coverage leaves measurable attack-surface gaps.
Stingrai PTaaS is a continuous-validation product with named senior pentesters running ongoing scope coverage; the AI agent Snipe augments coverage on known classes (the AI-led portion runs roughly 30 to 40 percent of an engagement), while senior pentesters keep ownership of business-logic discovery, exploit chaining, impact framing, and remediation guidance. Stingrai's Web Application Penetration Testing service aligns to PTES, OWASP Testing Guide v4.0, OWASP API Security Project, and NIST SP 800-115, and pentest output supports SOC 2, ISO 27001, HIPAA, and PCI DSS 4.0 compliance evidence (the attestation/certification itself is issued by a qualified third-party auditor).
Forward outlook
Three signals from primary publishers shape the next 12 to 24 months for agentic AI in pentesting.
Capability doubling continues on the AISI curve. UK AISI's May 13, 2026 evaluation sets the doubling rate at every 4.7 months since late 2024. METR's independent 4.2-month figure for software-engineering time horizons closely tracks AISI's measurement. The takeaway: agents that struggle with mid-complexity chained exploits today will handle them by mid-2027. PTaaS engagement scopes locked at 2025 capability assumptions will be outdated by Q4 2026.
Bounty-platform AI-program economics continue to scale. HackerOne's +270 percent YoY rise in customer programs with AI in scope (now 1,121 distinct programs) and +540 percent rise in valid prompt-injection reports both suggest the agentic-AI track is structural, not cyclical. Buyers should expect AI-program scopes to be a standard contractual element by 2027.
Defender-side agentic AI sets the architectural template. CrowdStrike Charlotte AI, Microsoft Security Copilot's Phishing and Alert Triage Agents, and competing defender-side agentic deployments all converge on the same architecture: bounded autonomy, code-enforced scope, mandatory human review gates per severity tier, explicit labeling of AI vs human work. The offensive side will converge on the same pattern, with the open question being how fast each PTaaS vendor adopts it.
Standards-body coverage will keep tightening. OWASP LLM Top 10 v2025, MITRE ATLAS v5.4.0, NIST AI 600-1, and ISO/IEC 42001:2023 are now mutually-referencing. Expect regulator and insurer questionnaires to demand AI-pentest evidence aligned to these frameworks by mid-2026.
Frequently Asked Questions
What does agentic AI actually do in pentesting today?
Agentic AI is the recon, payload-generation, known-pattern-matching, and triage layer of a modern pentest engagement. HackerOne's 9th Hacker-Powered Security Report (October 2025) measured 70 percent of surveyed researchers using AI tools in their workflow today, with the top use cases named as accelerating reconnaissance, speeding up testing, and reducing repetitive tasks. Bug-bounty platforms now have dedicated AI-program tracks; autonomous agents submitted 560 or more valid reports across HackerOne in 2025. The work AI offloads is pattern-known, well-trained, and fatigue-sensitive. The work AI does not replace is novel business-logic discovery, chained-exploit reasoning, false-positive validation, real-world impact framing, scope-judgment calls, and customer trust. The same HackerOne survey measured 58 percent of researchers saying AI misses business logic or chained exploits, and only 12 percent believing AI could replace them.
Where does agentic AI win in pentesting workflows in 2026?
Six categories. Reconnaissance and asset enumeration (sub-domains, content, parameter mining, JS file analysis). Known-pattern matching (OWASP Top 10 baseline coverage, IDOR baseline probes, open-redirect chains). Payload generation and variation (context-aware XSS, SSTI, SSRF payloads from a small seed library). Known-CVE matching (tech-stack fingerprint to vulnerable-CVE list). Triage and report drafting (first-pass reproduction steps, initial CVSS scoring suggestions). Bounty-platform breadth work (560 or more valid autonomous-agent submissions in 2025, per HackerOne 9th HPSR). These are the categories where machine throughput consistently beats human attention without the pentester losing the impact story.
Where does human oversight stay critical in agentic-AI pentesting?
Six categories. First, novel business-logic bugs: HackerOne's 9th HPSR measured 58 percent of researchers saying AI misses business logic or chained exploits. Second, chained-exploit reasoning across application boundaries. Third, false-positive validation: Anthropic's GTG-1002 disclosure (November 13, 2025) reported verbatim that Claude "occasionally hallucinated credentials or claimed to have extracted secret information that was in fact publicly-available" across the campaign. Fourth, real-world risk and impact framing in customer reports. Fifth, scope and contract judgment. Sixth, customer trust, disclosure timing, and the post-engagement relationship. All six are senior-pentester work in 2026.
What are the failure modes of agentic pentest agents in production?
Six. (1) Prompt injection against the agent itself (OWASP LLM01 and MITRE ATLAS AML.T0051). (2) Scope creep through agent discovery into adjacent out-of-contract targets. (3) Hallucinated CVE IDs and inflated severity ratings without human validation. (4) Agent loops and runaway model API cost incidents (OWASP LLM10 Unbounded Consumption). (5) Tool-call sequence drift ending in writes to shared caches, internal email, or CI/CD triggers (OWASP LLM06 Excessive Agency). (6) Data-handling exposure when sensitive findings move through a third-party model API in a way that breaks data-residency commitments (NIST AI 600-1 Information Security).
What is a human-in-the-loop architecture for AI-augmented pentesting?
Five phases. Scope fence set by humans in the agent's tool-call allow-list (scope-by-code, not by policy). Agent runs recon and known-class baseline coverage; outputs go to a holding queue. Human reviews every finding, drops false positives, confirms severity, and promotes survivors. Human pentester builds the exploit chain and decides what is worth chasing. Human pentester drafts and signs the customer report, runs the briefing, and owns the disclosure timing. The agent never reaches the customer report without a human signature on the cover sheet. The defender side already demonstrated the same architectural pattern at scale via CrowdStrike Charlotte AI (over 98 percent accuracy under bounded autonomy) and Microsoft Security Copilot Phishing Triage Agent (77 percent more accurate verdicts, 78 percent faster triage in randomized controlled studies).
What does Anthropic's GTG-1002 disclosure tell us about agentic-AI limits?
Anthropic's November 13, 2025 disclosure documented an AI-orchestrated cyber-espionage campaign across roughly 30 global targets, with 80 to 90 percent of campaign work AI-executed and only 4 to 6 critical human decision points per campaign. Anthropic also stated verbatim that "Claude didn't always work perfectly. It occasionally hallucinated credentials or claimed to have extracted secret information that was in fact publicly-available." The campaign is the first published large-scale example of AI agentic capability used end-to-end in cyber operations, but the same primary publisher also documented the ceiling: even at the frontier, AI agents still need human validation on the findings they generate. The defender lesson and the pentester lesson are the same. Agentic AI extends the floor of what's possible without removing the human ceiling on what's correct.
How fast is autonomous AI cyber capability advancing?
The UK AI Safety Institute measured the 80 percent-reliability cyber time horizon for frontier models doubling every 4.7 months since late 2024, down from a November 2025 estimate of 8 months, as of the May 13, 2026 evaluation. Models tested with a 2.5M-token-per-task budget. The newer Claude Mythos Preview checkpoint completed both AISI cyber ranges, solving "The Last Ones" in 6 of 10 attempts and "Cooling Tower" (previously unsolved) in 3 of 10 attempts. METR independently measures a 4.2-month doubling figure for software-engineering time horizons. The convergence between the two methodologies removes "one-team artefact" as a plausible explanation. Translation for buyers: an AI agent that struggles with multi-step chained exploits in 2026 is on track to handle them in 2027.
How can buyers evaluate AI-augmented pentest vendors?
Twelve evaluation questions. Is the AI agent named, described, and version-tracked. Are human review gates explicit per finding tier. Is the false-positive rate disclosed for AI-tagged findings. Is the scope-fence enforced by code, not policy. Are prompt-injection defenses tested for the agent itself. Is the data-handling policy explicit for sensitive findings. Does the report distinguish AI-led from human-led work. What is the liability and insurance posture for AI work. Does the vendor have a public CVE track record. Which certifications and compliance frameworks apply. How are agent loops and runaway costs prevented. Is regular human-led red-team coverage retained alongside the AI-augmented PTaaS cadence. The full checklist with annotated guidance for each question is the centerpiece of this post.
What is OWASP LLM Top 10 v2025's stance on agentic AI?
OWASP LLM06:2025 Excessive Agency is OWASP's canonical entry for agentic AI risk. OWASP splits LLM06 into three root causes: Excessive Functionality (extensions include capabilities beyond what the system requires for its intended operation), Excessive Permissions (extensions hold access rights to downstream systems that exceed operational necessity), and Excessive Autonomy (systems lack verification and approval mechanisms for high-impact actions). The eight prevention controls include minimizing extensions, restricting permissions, executing extensions within individual user contexts, requiring human approval for consequential actions, implementing authorization at downstream systems, and sanitizing inputs and outputs. The Anthropic GTG-1002 disclosure is the canonical 2026 exemplar of LLM06 in practice; the human-in-the-loop architecture in this post is the canonical defensive answer.
How does Stingrai handle agentic AI in pentest engagements?
Stingrai is a Toronto-headquartered offensive-security firm founded in 2021 with a London, UK office. Stingrai Inc is a CREST-accredited Penetration Testing service provider (firm-level accreditation, separate from individual CREST CRT certifications held by team members). The team has 18 published CVEs (Ivan Spiridonov 10, Moaaz Taha 5, Victor Villar 3), 5.0 out of 5.0 across 19 Clutch reviews, and team certifications spanning OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO, GCPN, CRTE, and eWPTX. The internal AI pentest agent, Snipe, is web-app focused, trained on more than 6,000 HackerOne disclosures, and runs both black-box dynamic testing and white-box source-code review; Snipe generates AutoFix pull requests for the issues it identifies and can run as a PR-gating check that blocks vulnerable code from being merged. Senior pentesters retain ownership of business-logic discovery, exploit chaining, impact framing, customer reporting, and remediation guidance. Engagement methodology aligns to PTES, OWASP Testing Guide v4.0, OWASP API Security Project, and NIST SP 800-115, and pentest output supports SOC 2, ISO 27001, HIPAA, and PCI DSS 4.0 compliance evidence (the attestation/certification itself is issued by a qualified third-party auditor). Stingrai presents research at DEFCON and BSIDES.
Related Stingrai research
AI Cyber Attack Statistics 2026. Attacker-side enumeration of named AI-enabled campaigns and population-level offensive statistics.
AI Cybersecurity Threats 2026. Defender-side risk taxonomy and governance framing for AI in cybersecurity programs.
Anthropic Mythos / GTG-1002 Defender Analysis. Stingrai's defender-side analysis of the Anthropic GTG-1002 disclosure.
AI in Offensive Security 2026. Stingrai's read on how AI changes the attacker tooling stack and the floor-vs-ceiling thesis.
AI Attack Surface Analysis 2026. Stingrai's map of the eight new attack-surface categories generative AI introduced or expanded.
Best PTaaS Providers 2026. Vendor-landscape view that complements the buyer-checklist framework in this post.
Penetration Testing Methodologies. Background on PTES, OWASP Testing Guide v4.0, and NIST SP 800-115 alignment that AI-augmented engagements still apply.
References
HackerOne. 9th Annual Hacker-Powered Security Report (Press Release). October 1, 2025. https://www.hackerone.com/press-release/hackerone-report-finds-210-spike-ai-vulnerability-reports-amid-rise-ai-autonomy. +210 percent AI vulnerability reports YoY, +540 percent prompt-injection reports, +270 percent AI-in-scope programs (1,121 distinct), US$81M payouts, 560+ autonomous-agent reports.
HackerOne. The Top Researcher Signals From HackerOne's 2025 HPSR. October 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. 70 percent researcher AI use; 58 percent miss business logic; 12 percent could be replaced; "AI output remains inconsistent without human oversight"; reports written entirely by AI tend to be "polished but technically shallow."
HackerOne. 3 Signals from the 2025 Hacker-Powered Security Report. November 4, 2025. https://www.hackerone.com/blog/ai-security-trends-2025. IDOR up 29 percent (2024), Improper Access Control up 18 percent, IDOR up 116 percent over five years; 67 percent of researchers use AI to accelerate testing.
Anthropic. Disrupting the first reported AI-orchestrated cyber espionage campaign (GTG-1002). November 13, 2025. https://www.anthropic.com/news/disrupting-AI-espionage. 80 to 90 percent AI-executed, 4 to 6 critical human decision points, roughly 30 targets, "occasionally hallucinated credentials" quote.
Anthropic. Detecting and countering misuse of AI: August 2025. August 2025. https://www.anthropic.com/news/detecting-countering-misuse-aug-2025. Prior period misuse signals; "vibe hacking" and RaaS case studies.
Anthropic. Responsible Scaling Policy. v3.3 effective May 26, 2026. https://www.anthropic.com/responsible-scaling-policy. ASL-3 Security and Deployment Standards.
UK AI Safety Institute. How fast is autonomous AI cyber capability advancing? May 13, 2026. https://www.aisi.gov.uk/blog/how-fast-is-autonomous-ai-cyber-capability-advancing. 80 percent-reliability cyber time horizon doubling every 4.7 months since late 2024; Mythos Preview completing both AISI ranges including "Cooling Tower" for the first time.
METR. Time Horizon 1.1. January 29, 2026. https://metr.org/blog/2026-1-29-time-horizon-1-1/. Independent 4.2-month doubling figure for software-engineering time horizon.
CrowdStrike. CrowdStrike Delivers the Next Breakthrough in AI-Powered Agentic Cybersecurity with Charlotte AI Detection Triage. February 12, 2025. https://www.crowdstrike.com/en-us/press-releases/crowdstrike-delivers-next-breakthrough-in-ai-powered-agentic-cybersecurity-with-charlotte-ai-detection-triage/. Charlotte AI Detection Triage achieves over 98 percent accuracy, eliminates more than 40 hours per week of analyst work, telemetry Feb–Aug 2025.
CrowdStrike. 2026 Global Threat Report. February 2026. https://www.crowdstrike.com/en-us/blog/crowdstrike-2026-global-threat-report-findings/. +89 percent YoY AI-enabled attacks, 90+ orgs prompt-injection victims, 27 seconds fastest breakout time.
Microsoft Learn. Security Alert Triage Agent in Microsoft Defender (Preview). 2025. https://learn.microsoft.com/en-us/defender-xdr/security-alert-triage-agent. 77 percent more accurate verdicts, 78 percent faster triage, 6.5x more malicious emails identified.
Microsoft Community Hub. From alert overload to decisive action: How Security Copilot agents are transforming security and IT. 2025. https://techcommunity.microsoft.com/blog/securitycopilotblog/from-alert-overload-to-decisive-action-how-security-copilot-agents-are-transform/4504213. Phishing Triage Agent and Alert Triage Agent rollout, plus 550 percent faster malicious-email detection by SOC analysts.
IBM and Ponemon Institute. Cost of a Data Breach Report 2025. July 30, 2025. https://newsroom.ibm.com/2025-07-30-IBM-Report-Breaches-Cost-U-S-Businesses-10-22M-on-Average-as-AI-Defenses-and-Attacks-Take-Off. 1 in 6 attacker AI; AI-phishing 37 percent and AI-deepfake 35 percent of attacker-AI cases; shadow AI +US$670K per breach; defender-AI saves US$1.9M and 80 days; 97 percent lacked AI access controls; US$10.22M US average breach cost.
Mandiant (Google Cloud). M-Trends 2026. March 2026. https://cloud.google.com/blog/topics/threat-intelligence/m-trends-2026. 22-second median initial-access-to-handoff; PROMPTFLUX, PROMPTSTEAL, QUIETVAULT named AI-aware malware.
OWASP. Top 10 for LLM Applications v2025. 2025. https://genai.owasp.org/llm-top-10/. LLM01 Prompt Injection through LLM10 Unbounded Consumption.
OWASP. LLM06:2025 Excessive Agency. 2025. https://genai.owasp.org/llmrisk/llm062025-excessive-agency/. Three root-cause split (Functionality, Permissions, Autonomy); eight prevention controls.
MITRE. ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) v5.4.0. January 2026. https://atlas.mitre.org/. Adversarial-ML technique taxonomy; AML.T0051 LLM Prompt Injection; AML.T0036 LLM Plugin Compromise.
NIST. AI Risk Management Framework + AI 600-1 GenAI Profile. July 2024. https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence. 12 GenAI risk categories including Information Security.
PTES. Penetration Testing Execution Standard. http://www.pentest-standard.org/index.php/Main_Page. Methodology framework referenced on Stingrai engagement scopes.
OWASP. Web Security Testing Guide v4.0. https://owasp.org/www-project-web-security-testing-guide/. Methodology framework referenced on Stingrai engagement scopes.
NIST. SP 800-115: Technical Guide to Information Security Testing and Assessment. https://csrc.nist.gov/pubs/sp/800/115/final. Methodology framework referenced on Stingrai engagement scopes.
Synack. Agentic AI in Pentesting: Trust, Human Oversight. 2025. https://www.synack.com/blog/agentic-ai-in-pentesting-trust-human-oversight/. Named industry reference on agentic AI in pentesting.
If your team needs an outside read on its 2026 pentest scope, agentic-AI workflow exposure, prompt-injection resilience for internal AI features, or vendor-evaluation diligence for an AI-augmented PTaaS RFP, Stingrai's pentest team runs continuous-validation engagements with senior-pentester depth augmented by our internal AI agent (Snipe). Reach out via the contact page to scope an engagement.


