
AI penetration testing can move your source code, your secrets, and your vulnerability findings through a third-party large language model API, and most buyers never ask where that data lands. The short answer to the question every security and procurement team is now asking: yes, an autonomous AI pentest tool can send your code and findings to an external LLM provider, and no, that is not automatically safe or unsafe. It depends entirely on how the vendor architects the data flow, whether that data is used to train a model, how long it is retained, and whether secrets are stripped before anything leaves your environment. Those are answerable questions. This post gives you the questions and a copy-paste questionnaire to put in front of any AI pentest vendor before your code leaves your environment.
The exposure is not hypothetical. Cyberhaven Labs found that 11% of the data employees pasted into ChatGPT was confidential, and source code was the second most common confidential data type leaving organizations this way, at 278 incidents per week per 100,000 employees (Cyberhaven, 2023). LayerX's Enterprise AI and SaaS Data Security Report 2025 found 77% of enterprise GenAI users copy and paste data into chatbots, roughly 22% of those pastes include PII or payment data, and 82% of pastes come from unmanaged personal accounts (LayerX, 2025). That is the ambient risk from casual employee use. An AI pentest tool is the opposite of casual: you are deliberately pointing it at your most sensitive application, handing it credentials, and asking it to read your source. The data governance question gets sharper, not softer.
The direct answer, up front
Does AI penetration testing send your source code and findings to a third-party LLM, and how do you control where that data goes?
An agentic AI pentest tool reasons using a large language model. That model is either (a) hosted by the vendor on infrastructure they control, or (b) a third-party API such as a commercial frontier model. If it is a third-party API, then every prompt the agent constructs, and that can include source-code snippets during white-box review, request and response bodies, extracted secrets, and the vulnerability findings themselves, is transmitted to that provider. You control where the data goes by verifying five things before onboarding: data residency (which country and which provider processes the data), model-training posture (is your data used to improve a model), retention (how long it is stored and how it is deleted), secret handling (is sensitive data redacted before transmission), and the contractual data-processing addendum that binds all of it. The rest of this post turns those five domains into a checklist you can send to any vendor.
Where the data actually flows
Picture the trust boundary around your environment. Inside it sits your application, your repositories, your CI/CD pipeline, and the credentials you provision for a test. An AI pentest agent operates by crossing back and forth across a series of control points, and each crossing is a place where data can leave.
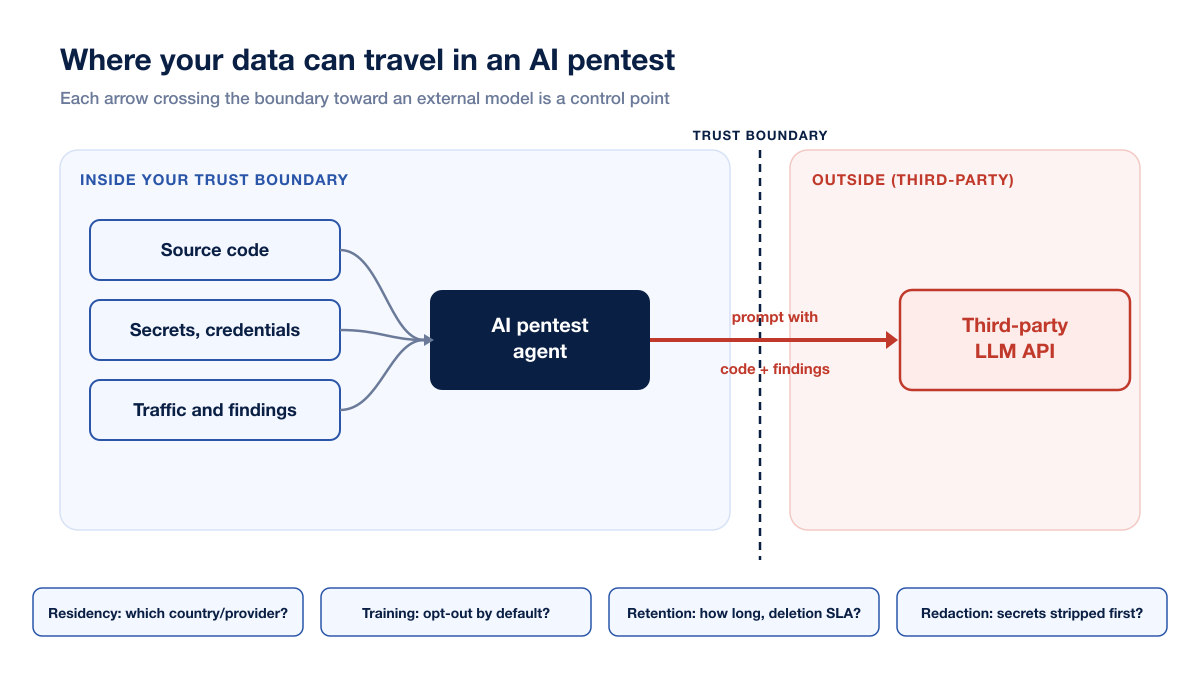
Figure 1: The data-flow path for an autonomous AI pentest engagement. Every arrow crossing the trust boundary toward an external model API is a control point a buyer should verify. Source: Stingrai analysis of agentic AI pentest architectures, 2026.
Three data classes are in play, and buyers routinely underestimate all three:
Source code (white-box review)
If the tool performs white-box code review, it reads your source. A generic AI code-review agent that calls a third-party model will place code into prompts sent to that provider. This is precisely the class of exposure OWASP flags as Sensitive Information Disclosure, which rose to the number two position in the OWASP Top 10 for LLM Applications 2025 (OWASP GenAI Security Project, 2025). Your proprietary logic, your embedded comments, and any secrets hardcoded in the tree can travel with it.
Secrets and credentials
Pentest tooling is provisioned with credentials by design. API keys surfaced during testing, tokens in HTTP traffic, and connection strings pulled from misconfigured endpoints can all end up in the agent's working context. If that context is serialized into a prompt to an external model, the secret goes with it. This is why secret redaction before transmission is a non-negotiable line item, not a nice-to-have.
Findings and evidence
The vulnerability report is itself sensitive. A findings document is effectively a map of how to compromise your application, complete with reproduction steps. If findings are generated, refined, or summarized by a third-party model, that map crosses the boundary too. Retention of findings data matters as much as retention of the raw inputs.
The takeaway is not that AI pentesting is dangerous. It is that the data flow is a design decision the vendor made, and you are entitled to see the design before you trust it.
The stat that reframes the risk
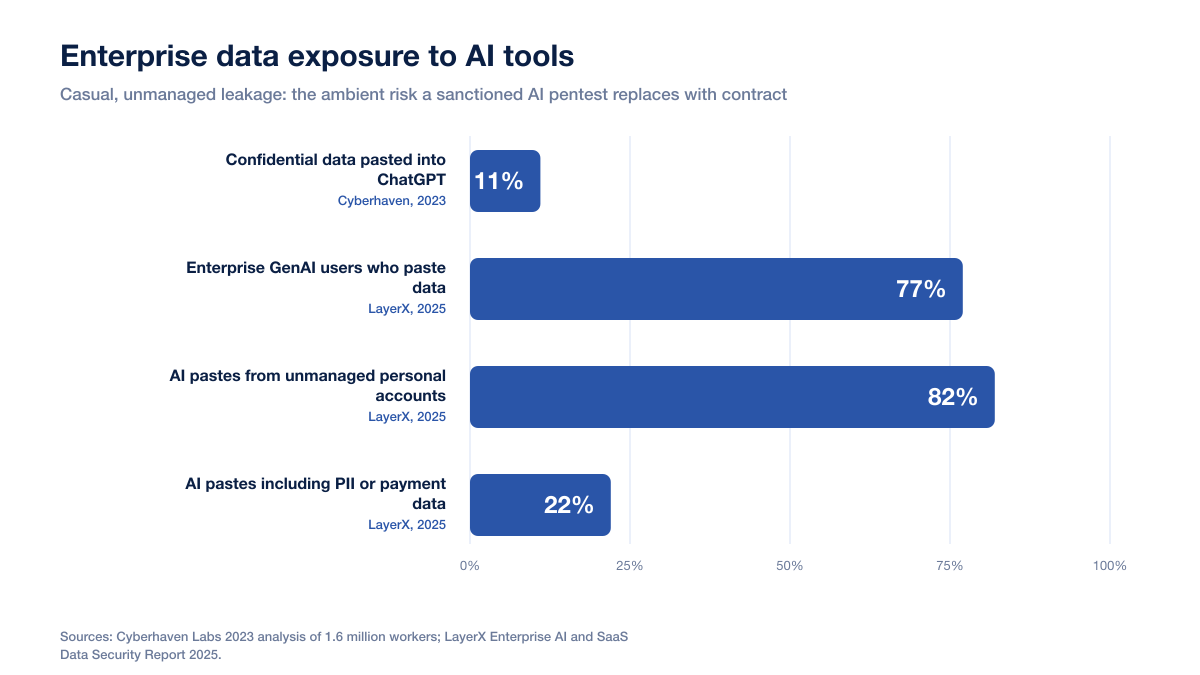
Figure 2: Enterprise data exposure to AI tools. Sources: Cyberhaven Labs 2023 analysis of 1.6 million workers; LayerX Enterprise AI and SaaS Data Security Report 2025.
The numbers above describe unmanaged, casual exposure. A sanctioned AI pentest is a managed activity, which is exactly why it can be safe: you get to set the terms. Casual employee use leaks confidential data because nobody negotiated a contract, chose a provider, or configured retention. Procurement of an AI pentest tool is your chance to do all three deliberately. The vendors worth buying from will answer every question below without friction. The ones that stall on data residency or model training are telling you something.
The AI pentest data-handling due-diligence questionnaire
Copy this into your vendor assessment. Each question maps to a specific risk. Require written answers, ideally reflected in the contract or the data-processing addendum, not just a sales call assurance.

Figure 3: The five data-handling domains to clear before onboarding any AI pentest vendor.
1. Data residency and processing location
Where, geographically, is my data processed and stored? Name the countries and cloud regions.
Does the AI reasoning engine run on infrastructure you operate, or does it call a third-party LLM API? Name the model provider if it is external.
If a third-party model is used, is it accessed through an enterprise or business tier with contractual data protections, or a consumer endpoint?
Can I require that my data stays within a specific jurisdiction (for example, Canada, the EU, or the UK) to meet my residency obligations?
Which subprocessors touch my data, and can I see the current subprocessor list?
2. Model training opt-out
Is any of my data, including source code, traffic, secrets, or findings, ever used to train, fine-tune, or improve a model?
If you use a third-party model API, does that provider train on your inputs and outputs? For enterprise and API access, commercial providers document that business and API data is not used to train models by default (OpenAI, 2026; Anthropic commercial terms, 2026). Ask the vendor to confirm which tier they use and to show the clause.
Is training opt-out the default, or something I have to request?
Is the opt-out contractually guaranteed, or a configuration setting that could change?
3. Retention and deletion
How long do you retain my source code, traffic captures, secrets, and findings?
If you use a third-party model API, what is that provider's default retention window, and can zero data retention be enabled for eligible endpoints?
Can I request deletion, and what is the SLA for it?
Are backups and logs included in the deletion, or do copies persist?
What happens to my data at the end of the engagement and at contract termination?
4. Secret redaction and data minimization
Are secrets, credentials, and PII redacted or tokenized before any data is sent to a model?
What is the mechanism, and can you demonstrate it on a sample?
Do you minimize what is sent to the model, or is the full context transmitted by default?
How do you prevent a hardcoded secret found during white-box review from being echoed into a prompt or a report shared over an external service?
5. Data-processing addendum and contractual controls
Will you sign a data-processing addendum (DPA) that names subprocessors, residency, retention, and training posture?
Does the DPA flow the same obligations down to any third-party model provider you use?
Do you carry breach-notification obligations, and on what timeline?
Can I audit or receive documentation of your data-handling controls?
Do you support single-tenant or isolated processing for regulated workloads?
If a vendor cannot give you clear written answers across all five domains, you do not have enough information to let your source code leave your environment. That is not a Stingrai position. It is basic data governance applied to a new tool category.
How to read the answers
A strong answer set has a shape. Look for these signals:
Named providers and regions, not "we use secure cloud infrastructure." Vagueness here is the single biggest red flag.
Training opt-out as the default, backed by a contract clause, not a checkbox someone has to remember to tick.
A specific retention number and a deletion SLA, not "we delete data when it is no longer needed."
A demonstrable redaction step before data reaches any model, especially for white-box review where source and secrets are in scope.
Willingness to sign a DPA that flows obligations down to any third-party model provider.
A weak answer set leans on adjectives. "Enterprise-grade," "bank-level," and "fully secure" are marketing, not architecture. The questionnaire above forces the conversation onto architecture, which is where the real answer lives. For a broader framework on evaluating AI pentest tools beyond data handling, see our AI pentesting evaluation guide, and for the wider market context, the AI offensive security tool boom.
What this means for the way you buy
Data handling has quietly become the deciding factor in AI pentest procurement, ahead of raw finding counts. A tool that surfaces more vulnerabilities is worth nothing if onboarding it means your source code and credentials traverse a model API you cannot see into. Three practical moves for security buyers in 2026:
Put the questionnaire before the demo. Data-flow answers are cheaper to get before you are emotionally invested in a tool's findings.
Treat white-box scope as the high-water mark. If the tool reads source, your residency and redaction requirements tighten. Scope the data-handling review to the most invasive mode the tool will run in.
Make the DPA a gate, not a formality. The clauses on training, retention, and subprocessor flow-down are where the real protection sits.
Where does Stingrai fit. Stingrai's autonomous web application pentest agent, Snipe, operates within controlled infrastructure with defined data handling, so buyers get a clean answer to the data-governance question rather than a shrug. Snipe is purpose-built to hunt the complex, high-impact vulnerability classes that generic AI tools miss, including IDOR, broken authorization, and business logic flaws, and it runs both black-box dynamic testing and white-box source review, generates AutoFix pull requests, and can run as a PR-gating check on every pull request. Every high-severity finding is validated by senior pentesters. The same five-domain checklist above is the one we encourage buyers to put to us and to every other vendor they evaluate. You can see how this maps to a full engagement on our PTaaS page and our web application penetration testing service, and the pricing page covers the tiers that use Snipe.
Stingrai is a CREST-accredited offensive security firm founded in 2021, headquartered in Toronto with a London office, and our penetration testing supports your SOC 2, ISO 27001, PCI DSS 4.0, and DORA compliance programs. When you are asking a vendor where your data goes, ask us too.
Frequently Asked Questions
Does AI penetration testing send my source code to a third-party LLM?
It can. If the AI pentest tool performs white-box code review and its reasoning engine is a third-party LLM API, then source-code snippets are transmitted to that provider inside the agent's prompts. Whether that is acceptable depends on the provider's training and retention policies and on whether the vendor redacts secrets first. Ask the vendor directly whether an external model is used, and require a written answer before onboarding (OWASP GenAI Security Project, 2025).
How do I control where my AI pentest data goes?
You control it at procurement, by verifying five things in writing: data residency, model-training opt-out, retention and deletion, secret redaction, and a data-processing addendum that flows those obligations down to any third-party model provider. A sanctioned pentest is a managed activity, which means you set the terms in the contract rather than accepting a default you never negotiated.
Is my data used to train a model when I use an AI pentest tool?
Only if the vendor or its model provider allows it. Commercial LLM providers document that business and API data is not used to train models by default (OpenAI, 2026; Anthropic commercial terms, 2026). But defaults differ between consumer and enterprise tiers, so confirm which tier the vendor uses and ask them to show the clause. Make training opt-out a contractual guarantee, not a setting.
What is AI pentest data residency and why does it matter?
Data residency is the geographic location where your data is processed and stored. It matters because regulations such as GDPR, and sector rules in Canada, the EU, and the UK, can require that certain data stays within a jurisdiction. If an AI pentest tool routes your code and findings through a model API hosted in another country, you may breach a residency obligation without realizing it. Ask the vendor to name the countries and cloud regions involved.
How large is the data-exposure risk from AI tools in general?
Substantial and growing. Cyberhaven found 11% of data pasted into ChatGPT was confidential, with source code among the most common types (Cyberhaven, 2023). LayerX found 77% of enterprise GenAI users paste data into chatbots and 82% of those pastes come from unmanaged personal accounts (LayerX, 2025). That is casual exposure. A sanctioned AI pentest lets you replace casual with contractual.
Should AI pentest findings be treated as sensitive data?
Yes. A findings report is a reproduction guide for compromising your application, so it deserves the same handling as source code and secrets. Ask how findings are generated, whether a third-party model touches them, and how long they are retained. Retention of findings should be covered by the same deletion SLA as the raw inputs.
What questions should I ask an AI pentest vendor about data handling?
Use the five-domain questionnaire in this post: data residency and processing location, model-training opt-out, retention and deletion, secret redaction and data minimization, and the data-processing addendum. Require written answers reflected in the contract. Vendors that answer clearly are demonstrating maturity, and vendors that stall on residency or training are telling you where their gaps are.
Does Stingrai's Snipe send my code to a third-party LLM?
Snipe operates within controlled infrastructure with defined data handling, and Stingrai gives buyers a clear answer to the data-governance question during procurement. Snipe runs both black-box and white-box testing, hunts complex classes such as IDOR and broken authorization, produces AutoFix pull requests, and can gate pull requests, with senior pentesters validating high-severity findings. The five-domain checklist in this post is exactly what we invite buyers to ask us, and every other vendor they consider. See our PTaaS page for how this fits an engagement.
References
Cyberhaven Labs. 11% of data employees paste into ChatGPT is confidential. 2023. https://www.cyberhaven.com/blog/4-2-of-workers-have-pasted-company-data-into-chatgpt. Analysis of ChatGPT usage across 1.6 million workers, quantifying confidential-data pastes including source code, client data, and regulated information.
LayerX. Enterprise AI and SaaS Data Security Report 2025. 2025. https://layerxsecurity.com/generative-ai/chatgpt-data-leak/. Real-world enterprise telemetry on GenAI adoption, copy-paste behavior into chatbots, sensitive-data exposure rates, and the share of activity flowing through unmanaged personal accounts.
OWASP GenAI Security Project. OWASP Top 10 for LLM Applications 2025. 2025. https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/. The canonical taxonomy of LLM application risks, including Sensitive Information Disclosure and Supply Chain, used here to classify the data-flow exposure of AI pentest tooling.
OpenAI. Enterprise privacy. 2026. https://openai.com/enterprise-privacy/. OpenAI's documented policy that business and API-platform inputs and outputs are not used to train models by default, with default abuse-monitoring retention and zero-data-retention options for eligible endpoints.
Anthropic. Commercial Terms of Service. 2026. https://www.anthropic.com/legal/commercial-terms. Anthropic's commercial terms governing how customer inputs and outputs are handled under business and API access, including training posture.


