
A field guide for CISOs, AppSec leaders, and security buyers trying to separate signal from hype in the AI offensive security boom. We map the ecosystem, verify the economics, name the autonomy-versus-accuracy gap, and show the hybrid pattern that actually ships.
TL;DR: The AI Offensive Security Boom in Numbers
The AI offensive security market did not grow. It exploded. The open-source tooling alone went from a rounding error to a crowded field in under three years, and the unit economics of an attack flipped by orders of magnitude.
Tool count (2023 to 2026): From fewer than 5 open-source AI offensive tools before GPT-4 to over 70 by March 2026, with 65+ launched in the 18 months after GPT-4's release (Hadrian, AI Offensive Security Boom).
Per-engagement cost inversion: Manual pentests run US$15,000 to US$50,000; AI-driven agents run US$0.30 to US$28.50 per run (Hadrian).
Carnegie Mellon CAI benchmark: 156x cost reduction (US$109 versus US$17,218) and 3,600x faster than human testers on equivalent scenarios (Hadrian).
Time-to-exploit compression: Median time-to-exploit fell from 756 days in 2018 to 4 hours in 2024 (Hadrian).
The autonomy gap: Autonomous agents exploited only 13 to 21 percent of real-world production CVEs on their own, rising to 64 percent with human assistance (Hadrian).
Researcher sentiment: Only 12 percent of surveyed security researchers believe AI will replace them, while more than two-thirds already use AI or automation in their workflow (HackerOne 2025 9th HPSR).
The macro forecast: Gartner predicts AI agents will reduce the time it takes to exploit account exposures by 50 percent by 2027 (Gartner, March 2025).
Why the Boom Happened: Sequential Workflows Became Parallel Ones
The cheap explanation for the boom is "ChatGPT made hacking easy." That is wrong, and it misreads the real shift.
The real driver, as Hadrian argues in its census, is structural: AI did not simply replicate a human pentester's sequential workflow at a lower price. It changed the shape of the work from sequential to parallel. A human tester probes one host, then the next, then chains a finding. An agentic system probes an entire environment at once, runs many exploit hypotheses concurrently, and does it at machine speed. Hadrian frames this as the move from "sequential versus parallel execution," and it is why the economics broke rather than merely improved.
That structural change shows up in three independently verifiable metrics:
Speed. Median time-to-exploit fell from 756 days in 2018 to 4 hours in 2024 (Hadrian). DARPA's AI Cyber Challenge surfaced 54 new vulnerabilities in 4 hours.
Cost. Carnegie Mellon's CAI work logged a 156x cost reduction, US$109 versus US$17,218 for equivalent testing, and a 3,600x speedup (Hadrian).
Volume. Zero-days exploited in the wild rose to 90 in 2025 from 78 in 2024, and one AI agent reportedly surfaced 100+ kernel vulnerabilities across major vendors in 30 days at roughly US$4 per bug (Hadrian).
The implication for defenders is uncomfortable. When competent offense costs dollars instead of tens of thousands, the threat model shifts from a sophisticated adversary picking one target to mediocre automation running continuously against every exposed surface. The economics that benefit your red team also benefit everyone else's.
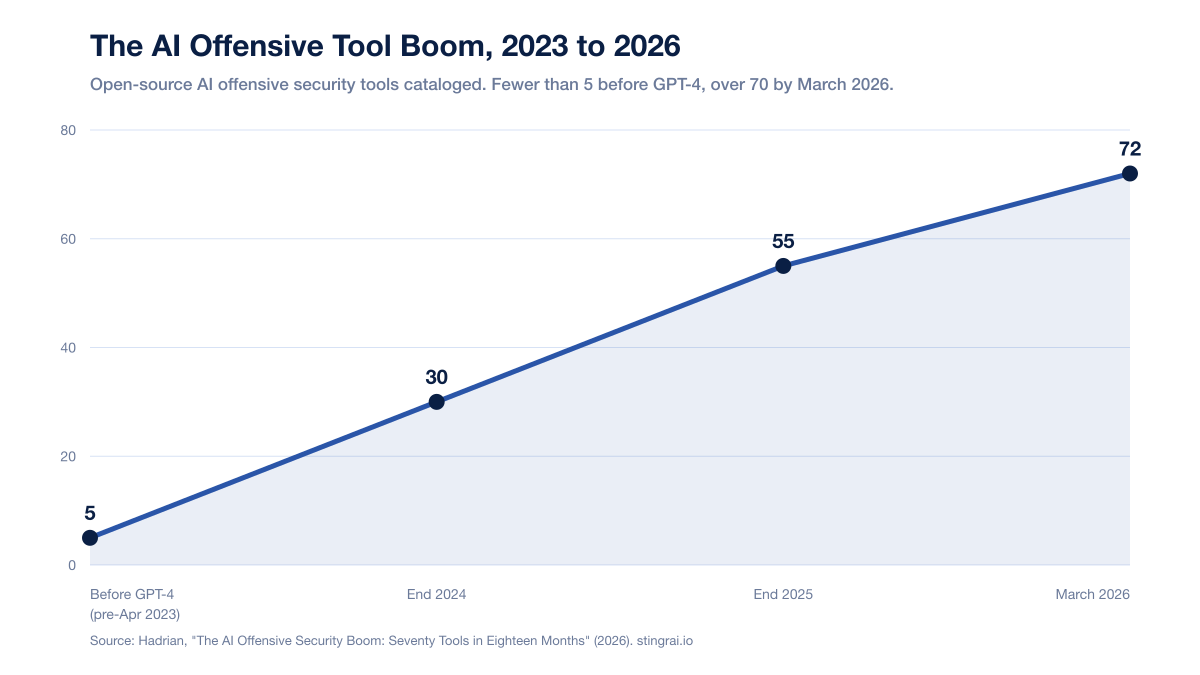
Figure 1: Open-source AI offensive security tool count, 2023 to 2026. Source: Hadrian, "The AI Offensive Security Boom: Seventy Tools in Eighteen Months" (2026).
Mapping the 70+ Tools: Five Functional Categories
Seventy tools is unmanageable as a shopping list. It is tractable as five categories. Hadrian's census names systems including Excalibur, RapidPen, CAI, PentestGPT, HexStrike AI, WhiteRabbitNeo, ARTEMIS, and many more. Grouped by function, the landscape looks like this.
Category | What it does | Representative tools | Buyer reality in 2026 |
|---|---|---|---|
Autonomous web agents | End-to-end discovery and exploitation of web apps and APIs | XBow, Snipe (hybrid), PentestGPT | Strongest momentum; accuracy still needs validation |
Autonomous network agents | Credential attacks, lateral movement, AD abuse, proof-of-exploit | Horizon3.ai NodeZero, Excalibur, RapidPen | Mature for infrastructure; proof-of-exploit is the differentiator |
Orchestration agents | Drive existing tools (Nmap, Burp, Metasploit) via an LLM planner | Penligent, HexStrike AI | Powerful but only as good as the underlying tools and guardrails |
Assistant and copilot tools | Speed up recon, evidence, and report writing for human testers | HackerAI, copilot-style assistants | Low risk, high productivity; not a standalone test |
Research and benchmark tools | CTF solving, kernel fuzzing, academic evaluation | CAI, ARTEMIS, DARPA AIxCC entrants | Push the frontier; not production buys |
The categories matter because they map to different risk profiles. An orchestration agent that wraps Metasploit inherits Metasploit's blast radius. An assistant that drafts reports cannot break anything. A fully autonomous web agent can both find real bugs and hallucinate them. Knowing which category you are buying tells you what guardrails you need.
The Catch the Hype Skips: Autonomy Is Not Accuracy
The boom narrative says AI agents are about to replace pentesters. The data says something more precise: AI agents are extraordinary at breadth and still unreliable at judgment.
Three numbers anchor this:
On real-world production CVEs, autonomous agents exploited only 13 to 21 percent on their own. With human assistance, that jumped to 64 percent (Hadrian). The human is not optional; the human is the multiplier.
In controlled conditions, GPT-4 exploited 87 percent of known CVEs and 85 percent across 104 real-world web challenges (Hadrian). The gap between 85 percent in a benchmark and 13 to 21 percent in production is the gap between a demo and a deployment.
Researchers agree. Only 12 percent believe AI will replace them, two-thirds expect hackbots to enhance rather than replace their work, and 43 percent see them primarily as tools for simpler vulnerabilities (HackerOne 2025 9th HPSR). Meanwhile 58 percent are actively upskilling in AI, which tells you where practitioners think the value is: augmentation, not abdication.
The lesson is not "AI offense is overhyped." It is "autonomy and accuracy are different axes." A tool can be maximally autonomous and still need a human to separate the real critical from the confident-sounding false positive. The most impactful findings, HackerOne notes, still come from researchers who understand what they are testing.
How to Buy in 2026: The Hybrid Pattern
If autonomy is breadth and humans are judgment, the buying decision writes itself: buy both, wired together. That is the hybrid pattern, and it is where the serious 2026 programs are landing.
What hybrid means in practice
A hybrid AI pentesting program has three properties:
An agentic engine for machine-speed coverage of the full attack surface, running continuously rather than once a year.
Human validation on every finding, so the report contains proof, not probability.
A feedback loop into engineering, so findings become fixed code, not a PDF that ages in a ticket queue.
Stingrai Snipe as the production example
Stingrai's Snipe is built to this pattern. Four properties set it apart from a pure-autonomy tool:
Trained on 6,000+ HackerOne reports. Snipe learned from real bug-bounty payloads, not synthetic CTFs. Real bugs are messy: broken auth, IDOR with non-obvious object IDs, race conditions, business logic flaws. That corpus is what lets it generalize to applications it has never seen.
Black-box plus white-box code review. Most agentic tools are black-box only. Snipe also reads source, traces data flows to sinks, and finds the bug classes that need code visibility (missing authorization decorators, dangerous deserialization, taint reaching a query).
AutoFix PRs and PR-gating. Snipe writes patches as pull requests with reasoning and tests, and in PR-gating mode it blocks merges that introduce critical issues. That is the feedback loop into engineering, automated.
Human-validated output. Every finding is reviewed by a Stingrai pentester before it reaches the customer. This is what converts the 13-to-21-percent autonomous accuracy figure into something a CISO can act on.
Stingrai productizes this on its pricing page as an Autonomous Snipe tier and a Hybrid Snipe-plus-experts tier, both carrying a "No High or Critical Finding = Don't Pay" guarantee. As a CREST-accredited penetration testing service provider founded in 2021, Stingrai pairs the engine with the human program around it, which is exactly the structure the data argues for.
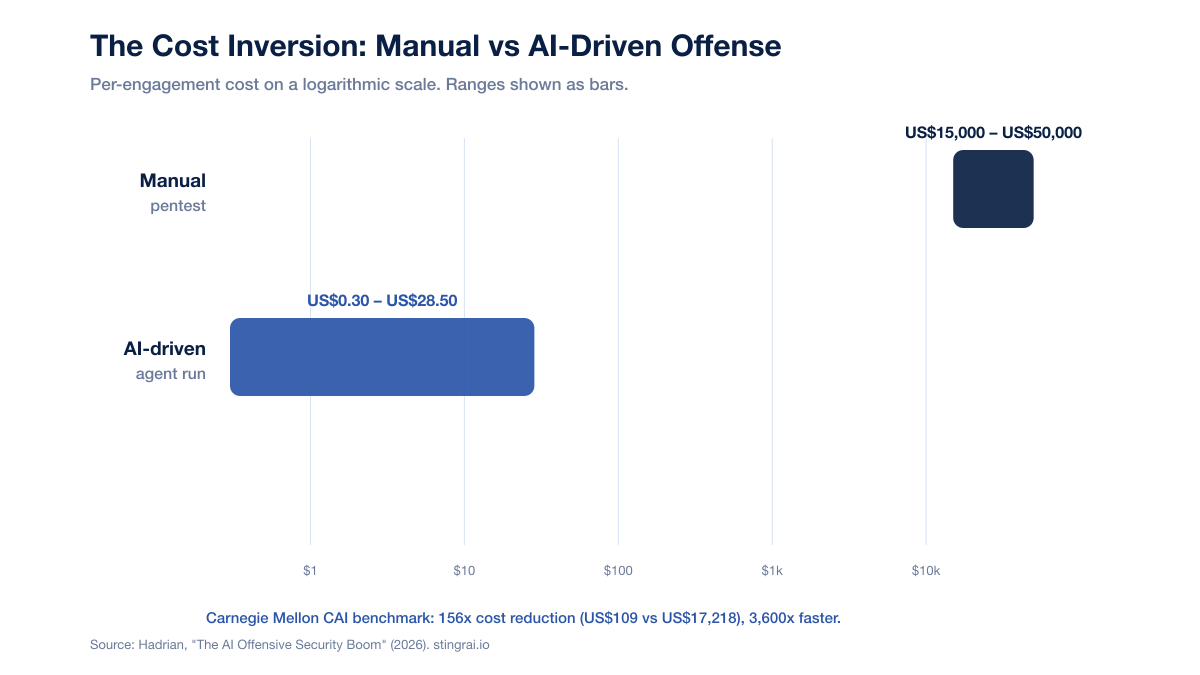
Figure 2: Per-engagement cost, manual pentest versus AI-driven agent run. Source: Hadrian, "The AI Offensive Security Boom" (2026). Manual range US$15,000 to US$50,000; AI agent runs US$0.30 to US$28.50.
What This Means for Defenders
The boom changes your defensive posture whether or not you buy any of these tools, because attackers are buying them.
Shrink your point-in-time gaps. A once-a-year pentest leaves 51 weeks of drift. When offense runs continuously and cheaply, your testing has to as well. An agentic engine on every release closes the window.
Demand proof, not signal. Vulnerability scanners produce alerts that need triage. Agentic pentesters that validate exploits produce proof. In a world of cheap automated probing, your team's time is the scarce resource. Buy proof.
Wire findings into the pipeline. A finding that becomes an AutoFix PR and a PR-gating check is worth more than a finding in a report. Shift remediation left of merge.
Keep humans on the judgment calls. The 13-to-21-percent figure is your reminder. Business logic, novel chains, and exploitability-in-context are still human work. Budget for validation, not just the engine.
Pair an agentic pentester with continuous DAST. Use the agent for exploit-class depth and a DAST scanner for broad regression coverage between assessments. They are complementary, not interchangeable.
Stingrai's PTaaS and offensive security services are built around this defensive posture: continuous, validated, and wired into engineering.
Frequently Asked Questions
How many AI offensive security tools exist in 2026?
Over 70 open-source AI offensive security tools existed as of March 2026, up from fewer than 5 before GPT-4's release in April 2023, with more than 65 launched in the following 18 months, according to Hadrian's tool census. That count is open-source tools only and does not include commercial platforms.
How much cheaper is AI-driven pentesting than manual pentesting?
Manual pentests run US$15,000 to US$50,000 per engagement, while AI-driven agents run US$0.30 to US$28.50 per run, per Hadrian. Carnegie Mellon's CAI benchmark recorded a 156x cost reduction (US$109 versus US$17,218) and a 3,600x speedup on equivalent scenarios. The caveat: cost-per-run is not cost-per-validated-finding, because autonomous output still needs human review.
Can AI offensive security tools replace human pentesters in 2026?
No. Autonomous agents exploited only 13 to 21 percent of real-world production CVEs on their own, rising to 64 percent with human assistance (Hadrian), and only 12 percent of researchers believe AI will replace them (HackerOne). The accurate framing is augmentation: AI provides breadth and speed, humans provide judgment and validation.
What is the difference between autonomy and accuracy in AI pentesting?
Autonomy is how independently a tool operates; accuracy is how often its findings are real and exploitable. A tool can be fully autonomous and still produce false positives, which is why GPT-4's 85 percent benchmark accuracy collapses to 13 to 21 percent on production CVEs (Hadrian). Hybrid programs keep high autonomy for breadth while using human validation to close the accuracy gap.
What is the smartest way to buy AI offensive security in 2026?
Buy hybrid: an agentic engine for machine-speed breadth plus human validation for judgment, with findings wired into your engineering pipeline. Stingrai's Snipe is a production example, trained on 6,000+ HackerOne reports with black-box plus white-box review, AutoFix PRs, PR-gating, and human-validated output, productized on Stingrai's pricing page with a no-high-or-critical-finding guarantee.
Does the AI offensive security boom make defenders less safe?
It raises the baseline threat for everyone. When competent offense costs dollars, attackers run cheap automation continuously against all exposed surfaces, and Gartner predicts AI agents will cut account-exposure exploit time by 50 percent by 2027 (Gartner). The defensive answer is continuous, validated testing on your own surface so you find the bugs before cheap automation does.
References
Hadrian. The AI Offensive Security Boom: Seventy Tools in Eighteen Months. 2026. https://hadrian.io/blog/the-ai-offensive-security-boom-seventy-tools-in-eighteen-months. Census of open-source AI offensive tools with cost economics, exploitation benchmarks, and time-to-exploit data.
HackerOne. 2025 9th Hacker-Powered Security Report: Researcher Signals. 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. Survey of security researchers on AI adoption, replacement sentiment, and upskilling.
Gartner. Gartner Predicts AI Agents Will Reduce the Time It Takes to Exploit Account Exposures by 50% by 2027. March 2025. https://www.gartner.com/en/newsroom/press-releases/2025-03-18-gartner-predicts-ai-agents-will-reduce-the-time-it-takes-to-exploit-account-exposures-by-50-percent-by-2027. Forecast on AI-accelerated account-takeover timelines from the "Predicts 2025" research.
The AI offensive security boom is real, the economics are real, and the autonomy gap is just as real. The teams that win in 2026 treat AI as a force multiplier on human expertise, not a replacement for it. To see how a hybrid program runs in production, explore Stingrai's offensive security services and Snipe-powered PTaaS.


