
A practical 2026 comparison for security engineers and AppSec leaders choosing an AI model for penetration testing work. We rank the frontier models, show what the benchmarks actually say, and explain why the harness beats the model.
TL;DR: Best AI Models for Pentesting in 2026
The question "what is the best AI model for pentesting" has the wrong shape. In 2026, the model is the reasoning engine, but the agent harness around it (tool execution, validation gates, persistent memory, and human review) is what separates a real exploited finding from a confident hallucination. Here is the short version.
Best single model for security reasoning: Claude Sonnet 4.6. Strongest at large-codebase review, authorization-logic analysis, and long-horizon tasks with fewer tool errors, per Penligent's 2026 model analysis.
Best for browser-driven and computer-use testing: GPT-5.4. Designed for operating computers with libraries such as Playwright, which maps to interface automation and multi-step product testing.
Best for multimodal evidence review: Gemini 3.1 Pro. Built for large evidence bundles, PDFs, and architecture-heavy material with a roughly one-million-token input window.
Best production answer: a hybrid agent, not a raw model. AutoPenBench (EMNLP 2025) shows fully autonomous agents reach 21 percent success versus 64 percent when a human assists. Stingrai Snipe is the hybrid: a purpose-built web-app agent fleet validated by senior pentesters.
Key Takeaways
The harness matters more than the model. Penligent's 2026 analysis concludes the winning unit "is not the single reply, it is the workflow," and recommends "a routed stack with deterministic tools and explicit validation" over any single model. Two teams can run the identical frontier model and get wildly different results based on how they decompose tasks, gate outputs, and feed back evidence.
Autonomy without a human is the weak point, not the model's IQ. On AutoPenBench, fully autonomous agents reached 21 percent success while human-assisted agents reached 64 percent (EMNLP 2025, as cited by Penligent). Stanford's 2025 ARTEMIS study found the best AI agent still carried an 18 percent false-positive rate while human testers were near-perfect, and roughly 80 percent of human testers found a critical TinyPilot remote-code-execution flaw that every AI agent missed (arXiv 2512.09882).
Model choice is a routing decision, not a single pick. Use Claude Sonnet 4.6 for code-heavy reasoning, GPT-5.4 for browser and computer-use loops, and Gemini 3.1 Pro for multimodal evidence. A serious pentesting agent routes sub-tasks to the model that is strongest for each, rather than forcing one model to do everything.
The complex bug classes are where model-only setups fall down. Generic single-model agents excel at pattern-based bugs (HackerOne's 2025 report found 78 percent of valid hackbot findings were cross-site scripting) but miss IDOR, broken authorization, and business logic. Snipe was purpose-built to close exactly that gap, trained on 6,000+ HackerOne disclosure reports plus Stingrai's own pentesting methodology.
How to Read This Comparison
This is not a leaderboard of raw model intelligence. Frontier model rankings shift every few months, and the differences on generic reasoning benchmarks rarely predict pentesting outcomes. What predicts pentesting outcomes is the combination of three things: the model's reasoning quality, the tools it can call and validate against, and whether a human reviews the high-severity output.
Every model claim below is attributed to Penligent's 2026 security-engineer model analysis, which compared the current frontier models specifically for pentesting-adjacent work. Benchmark figures are attributed to their original academic sources. Model version names (Claude Sonnet 4.6, GPT-5.4, Gemini 3.1 Pro) and pricing are as published by Penligent in 2026; treat them as that source's snapshot rather than a fixed standard, and confirm current pricing with each vendor before you commit budget.
The 2026 AI Model Comparison for Pentesting
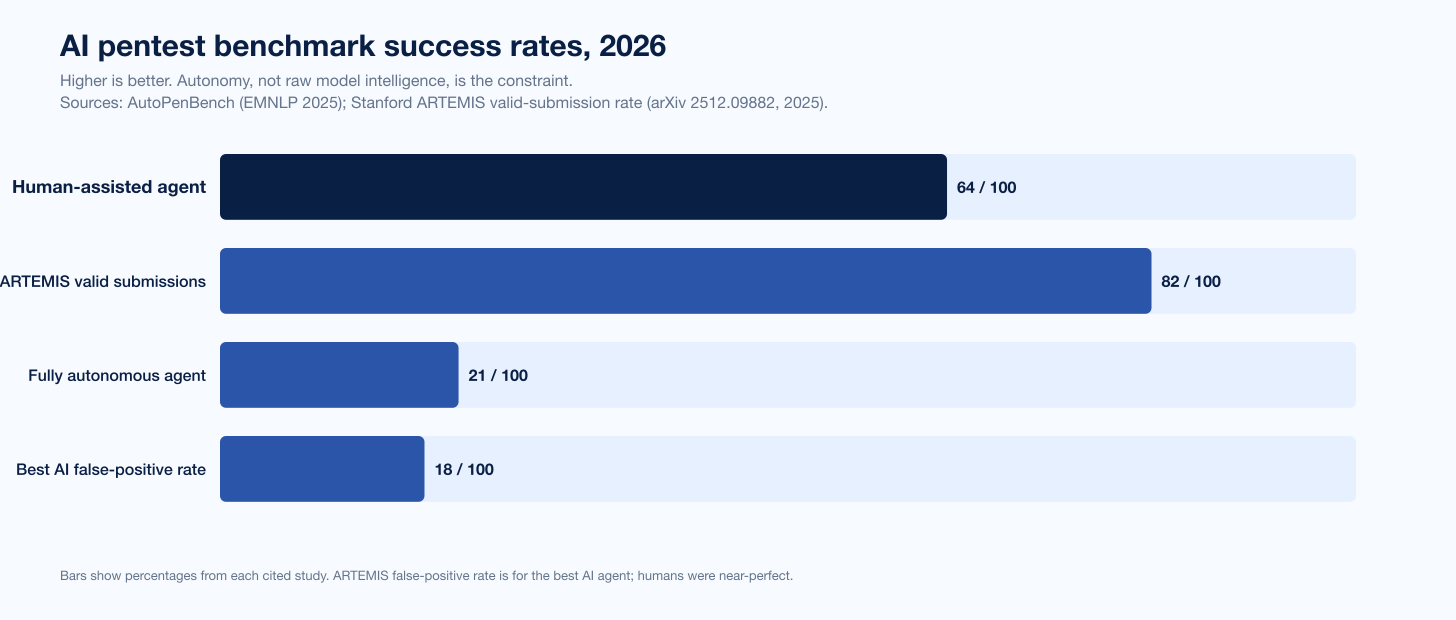
Figure 1: Autonomous AI pentest benchmark success rates, 2026. Sources: AutoPenBench (EMNLP 2025) and Stanford ARTEMIS (arXiv 2512.09882, December 2025), as compiled for this comparison.
Dimension | Claude Sonnet 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
Best at | Large-codebase review, auth logic, long-horizon tasks | Browser-driven testing, computer-use loops, interface automation | Large evidence bundles, PDFs, multimodal and architecture review |
Context window | 1M tokens | ~1.05M tokens | ~1.05M tokens |
Published price (in / out per M tokens) | US$3 / US$15 | US$2.50 / US$15 | US$2 / US$12 (under 200K input) |
Pentesting strength | Repository-wide security reasoning, fewer tool errors | Operating tools like Playwright, multi-step operator workflows | Ingesting screenshots, PDFs, and architecture diagrams as evidence |
Watch-out | Premium output cost on long loops | Cost adds up when kept constantly in the loop | Not yet the natural default for the average security engineer |
Source for all model attributes and pricing: Penligent, 2026. The shape of the table is the point: there is no single column that wins every row.
Claude Sonnet 4.6: best single model for security reasoning
Penligent's 2026 analysis calls Claude Sonnet 4.6 "the best single AI model for pentesting-adjacent work in 2026," citing its balance of advanced capability and cost efficiency on "large codebases, hard bug finding, long-horizon tasks, fewer tool errors." For penetration testing, the standout use cases are white-box source review and authorization-logic analysis: tracing a request from an untrusted input to a dangerous sink, spotting a missing authorization check, or reasoning about a multi-file auth flow. Its one-million-token context window means it can hold a meaningful slice of a real codebase in working memory rather than reasoning blind.
GPT-5.4: best for browser-driven and computer-use testing
GPT-5.4 is positioned by Penligent around "performance across computer-use workloads" and "writing code to operate computers with libraries such as Playwright." That maps directly to dynamic application testing: driving a browser through a multi-step checkout flow, manipulating client-side state, and automating the kind of interface interactions that catch broken access control between user roles. The trade-off Penligent flags is cost: GPT-5.4 is "not the cheapest option if you plan to keep it constantly in the loop," which matters for long-running agentic sessions.
Gemini 3.1 Pro: best for multimodal evidence review
Gemini 3.1 Pro's edge, per Penligent, is "huge evidence bundles, PDFs, multimodal materials, architecture-heavy review," backed by a roughly one-million-token input window and native PDF and code-execution support. In a pentest, that means ingesting architecture diagrams, prior assessment PDFs, and screenshots as first-class evidence. Penligent notes it is "not yet the most natural single-model default for the average security engineer," so treat it as a specialist for evidence-heavy engagements rather than your everyday driver.
What the Benchmarks Actually Say
Generic model leaderboards do not predict pentesting outcomes. Pentesting-specific benchmarks do, and they consistently show the same thing: autonomy is the constraint, not raw model intelligence.
AutoPenBench (EMNLP 2025): fully autonomous agents reached 21 percent success; human-assisted agents reached 64 percent. The 43-point gap is the value of a human in the loop, and it does not close by swapping in a smarter base model.
PentestGPT (USENIX Security 2024): its structured three-module design delivered a 228.6 percent task-completion increase over GPT-3.5 on benchmark targets, evidence that scaffolding, not just the model, drives results.
Stanford ARTEMIS (arXiv 2512.09882, December 2025): the best AI agent placed second overall and outperformed 9 of 10 human participants on systematic enumeration, but carried an 18 percent false-positive rate against near-perfect humans, and roughly 80 percent of human testers found a critical TinyPilot RCE that the AI agents missed.
The pattern is unambiguous. Frontier models are excellent at breadth, enumeration, and pattern-based bugs. They are weakest exactly where the highest-impact vulnerabilities live: business logic, chained exploits, and the judgment call about which of fifty findings actually matters.
Why the Harness Beats the Model

Figure 2: Which AI model fits which pentesting task in 2026. Hybrid agent classification reflects Stingrai Snipe's design. Model fits per Penligent, 2026.
A penetration test is a long-horizon, tool-heavy, judgment-laden task. The model contributes reasoning, but the harness contributes everything else:
Tool execution. The agent must drive real tools (proxies, fuzzers, source scanners) and parse their output, not just describe an attack in prose.
Validation gates. A claimed vulnerability is worthless until it is reproduced. The harness must attempt the exploit in a controlled way and confirm impact before it reaches a report.
Persistent memory and routing. The harness routes code-review sub-tasks to a code-strong model, browser sub-tasks to a computer-use-strong model, and keeps state across a multi-hour engagement.
Human review. Compliance regimes like PCI DSS assume human review of results, and the benchmarks show humans still catch the critical bugs AI misses.
This is why "which model" is the wrong first question. The right first question is "which agent system," and the model is one component inside it.
Where Stingrai's Snipe Fits
Snipe is Stingrai's autonomous AI agent for web application penetration testing, and it is built as a harness, not a single model. Four design choices make it the production answer rather than a raw-model experiment.
It hunts the complex classes, not just pattern bugs. Generic single-model agents are strong on cross-site scripting and misconfiguration but weak on IDOR, broken authorization, and business logic. HackerOne's 2025 report found 78 percent of valid hackbot findings were cross-site scripting, which captures exactly the breadth-over-depth profile of model-only setups. Snipe was purpose-built to reach into the high-impact classes those tools miss.
It is trained on real bugs, not synthetic CTFs. Snipe is custom-trained on 6,000+ HackerOne Hacktivity disclosure reports plus custom skills distilled from years of Stingrai's human pentesters' methodology. That corpus encodes how senior testers actually find broken authorization and non-obvious object-reference bugs in messy, real-world applications.
It runs black-box and white-box together. Most agentic tools are black-box only. Snipe also reads application source, traces data flows, generates AutoFix pull requests with reasoning, and can run as a PR-gating check that blocks vulnerable code from being merged.
Senior pentesters validate and extend every high-severity finding. This is the hybrid model the benchmarks point to: the AutoPenBench jump from 21 to 64 percent with human assistance is the gap Snipe's validation layer is designed to capture. Stingrai's pricing productizes an Autonomous tier (Snipe) and a Hybrid tier (Snipe plus certified pentesters), both with a "no high or critical finding equals do not pay" guarantee.
Stingrai was founded in 2021, is headquartered in Toronto with a London, UK office, and is a CREST-accredited Penetration Testing service provider at the firm level. The team holds OSCE3, OSCP, OSWE, OSED, OSEP, CREST CRT, CISSP, CRTO, GCPN, CRTE, and eWPTX certifications, has published 18 CVEs, and holds 5.0/5.0 across 19 Clutch reviews. Stingrai's penetration testing supports your SOC 2, ISO 27001, and PCI DSS compliance programs by providing audit-ready evidence.
See also our AI pentesting tools 2026 guide, what AI pentesting is, and traditional vs AI pentesting.
Frequently Asked Questions
What is the best AI model for pentesting in 2026?
There is no single best model. For raw model picks, Claude Sonnet 4.6 is the strongest single model for security reasoning and code review, GPT-5.4 leads browser and computer-use testing, and Gemini 3.1 Pro leads multimodal evidence review, per Penligent's 2026 analysis. The production answer is a hybrid agent like Stingrai Snipe, because the harness and human validation matter more than the base model.
Is Claude or GPT-5 better for security work?
They are strong at different things. Claude Sonnet 4.6 is better for large-codebase review and authorization-logic analysis, while GPT-5.4 is better for browser-driven and computer-use testing such as driving Playwright through multi-step flows. A well-designed pentesting agent routes each sub-task to the model that is strongest for it rather than picking one.
Can an AI model do a penetration test on its own?
Not reliably in 2026. AutoPenBench (EMNLP 2025) found fully autonomous agents reached 21 percent success versus 64 percent for human-assisted agents, and Stanford's 2025 ARTEMIS study found roughly 80 percent of human testers caught a critical RCE that every AI agent missed. Autonomous models are excellent at enumeration and pattern bugs but need human validation for the high-impact classes.
Why does the agent harness matter more than the model?
A pentest is a long-horizon task that requires driving real tools, reproducing exploits to validate them, routing sub-tasks across models, and human review of high-severity output. The model only supplies reasoning; the harness supplies everything that turns reasoning into a confirmed, audit-defensible finding. Penligent's 2026 analysis puts it directly: the winning unit "is not the single reply, it is the workflow."
Which AI model does Stingrai Snipe use?
Snipe is a harness, not a single model. It runs a fleet of specialist sub-agents, routes work to the appropriate reasoning model, and is custom-trained on 6,000+ HackerOne disclosure reports plus Stingrai's own pentesting methodology. The design point is that the agent system and human validation, not any one frontier model, are what let Snipe hunt IDOR, broken authorization, and business logic flaws.
How much does an AI-driven pentest cost compared to a manual one?
Hadrian's 2026 market census cites manual pentests at US$15,000 to US$50,000 per engagement, while AI-driven runs can cost a fraction of that. Stingrai's pricing productizes an Autonomous tier and a Hybrid tier, both with a "no high or critical finding equals do not pay" guarantee. The right comparison is not model cost but cost per validated, audit-ready finding.
References
Penligent. Best AI Model for Pentesting: What Security Engineers Should Actually Use in 2026. 2026. https://www.penligent.ai/hackinglabs/best-ai-model-for-pentesting-what-security-engineers-should-actually-use-in-2026/. Compares frontier models for pentesting-adjacent work and argues for routed multi-model workflows over single-model setups.
HackerOne. The Top Researcher Signals From HackerOne's 2025 HPSR (9th Hacker-Powered Security Report). 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. Survey of security researchers on AI adoption, hackbot finding classes, and AI-versus-human sentiment.
Wei et al. Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing (ARTEMIS). arXiv 2512.09882, December 2025. https://arxiv.org/abs/2512.09882. Live enterprise comparison of AI agents and human pentesters, including false-positive rates and the TinyPilot RCE result.
Hadrian. The AI Offensive Security Boom: Seventy Tools in Eighteen Months. 2026. https://hadrian.io/blog/the-ai-offensive-security-boom-seventy-tools-in-eighteen-months. Census of open-source AI offensive tools and cost comparisons between manual and AI-driven pentests.
Stingrai. Pricing and Snipe AI Pentesting Agent. 2026. https://www.stingrai.io/pricing. Productized Autonomous and Hybrid pentest tiers powered by the Snipe agent, with an outcome-based guarantee.


