
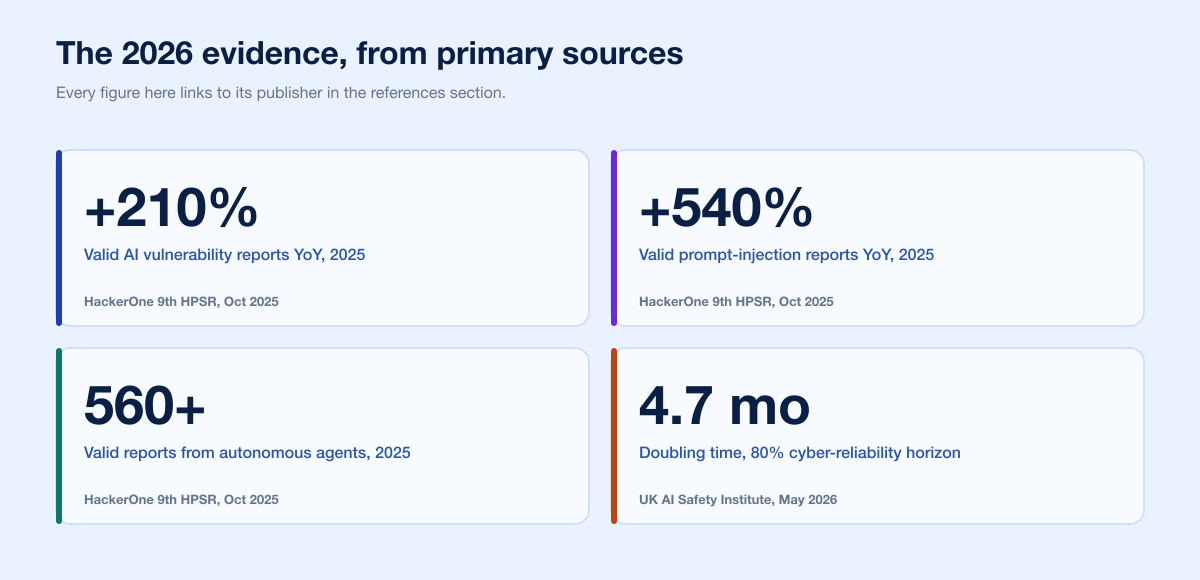
Valid AI vulnerability reports on HackerOne rose more than 210 percent year over year in 2025, valid prompt-injection reports rose 540 percent, and 560 or more valid reports came from autonomous agents alone, per HackerOne's 9th Hacker-Powered Security Report (October 1, 2025), titled "The Rise of the Bionic Hacker." In the same survey 70 percent of researchers report using AI tools in their workflow. The volume is real. The problem in 2026 is that a large share of that volume is noise: AI output that is polished but technically shallow, unverified, and stripped of the proof a defender needs to act. The tools that work close the distance between a plausible issue and trusted evidence. The tools that break widen it.
This post is the Stingrai research view on which AI pentest tools work in 2026 and which break, and Stingrai operates one of the tools in scope (Snipe), so the affiliation is disclosed up front. The analysis stands on the primary-source evidence regardless of where you land on the placement. The working tools in 2026 are Stingrai Snipe for web-application depth, XBow for autonomous web exploit validation, Horizon3.ai (NodeZero) for internal infrastructure, ZeroPath and RunSybil for source-code-aware discovery, Mindgard for runtime AI red teaming, and Hadrian for external attack-surface management. What breaks is not a vendor. It is a pattern: alert volume without validation, black-box scanning without reachability reasoning, findings without a fix artifact, and claims without a third-party benchmark trail.
This post is the Stingrai research team's canonical 2026 reference for what works and what breaks in AI pentest tooling. The data is anchored in named primary publishers: HackerOne, the UK AI Safety Institute, IBM, Anthropic, Mozilla, plus the academic AutoPenBench and Cybench benchmarks and the vendors' own public product documentation. Lead data is full-year 2025 telemetry, the freshest available; primary publishers have not yet released full-year 2026 reports as of June 2026. Every numeric claim links back to its primary publisher so any figure can be audited inline.
TL;DR: nine labeled claims
AI vulnerability report volume (2025): +210 percent YoY valid AI vulnerability reports; +540 percent valid prompt-injection reports; 560 or more valid reports from autonomous agents on the HackerOne platform (HackerOne, Oct 2025).
Researcher AI adoption (2025): 70 percent of HackerOne researchers use AI tools in their workflow; only 12 percent believe AI will replace them; 58 percent are actively upskilling in AI (HackerOne 9th HPSR researcher signals).
AI program adoption (2025): +270 percent YoY customer programs with AI in scope, totaling 1,121 distinct programs; HackerOne payouts US$81M (+13 percent YoY); US$3B in breach losses avoided across programs (HackerOne, Oct 2025).
AI cyber capability doubling (May 2026): Frontier-model 80 percent-reliability cyber time horizon doubles every 4.7 months since late 2024, revised down from the November 2025 estimate of 8 months; token budget 2.5M per task, up to 100M tokens in cyber-range experiments (UK AI Safety Institute, May 13 2026).
White-box proof point (2026): Anthropic's Claude Opus 4.6 found 22 vulnerabilities in Firefox in two weeks; Mozilla rated 14 high severity; the model scanned roughly 6,000 C++ files and filed 112 reports, but turned a finding into a working exploit in only 2 cases despite hundreds of attempts (Anthropic, Mozilla).
Autonomy gap (benchmark): On AutoPenBench, a fully autonomous agent reached 21 percent success; the human-assisted agent reached 64 percent (AutoPenBench, arXiv 2410.03225).
Breach cost context (2025): Global average data breach cost fell to US$4.44M, down 9 percent from US$4.88M, the first decline in five years, driven by faster AI-assisted containment (IBM Cost of a Data Breach 2025).
Stingrai Snipe scope: Web-app focused AI pentest agent trained on more than 6,000 HackerOne disclosures; performs both black-box dynamic and white-box source-code review; generates AutoFix pull requests; runs as a PR-gating check that blocks vulnerable code from merging (Stingrai).
What breaks (pattern, not vendor): Unverified alert volume, black-box scanning without reachability reasoning, findings with no fix artifact, and capability claims with no third-party benchmark trail. These are the four failure modes a 2026 buyer should test for directly.
Key takeaways
Proof is the dividing line, not autonomy. The most surprising finding in the 2026 data is that fully autonomous does not mean better. AutoPenBench measured a fully autonomous agent at 21 percent success and a human-assisted agent at 64 percent on the same tasks. The tools that work pair AI throughput with a validation gate; the tools that break ship raw model output as if it were a finding. Buy for proof quality, not for the word "autonomous" on the homepage.
White-box reasoning is what separates a finding from an alert. Anthropic's Firefox collaboration is the cleanest public demonstration: Claude scanned roughly 6,000 C++ files and surfaced 22 real bugs, 14 rated high severity by Mozilla, but converted only 2 into working exploits despite hundreds of attempts. Source-code reachability reasoning is where AI is strong; blind exploitation is where it is still weak. Tools that only scan from the outside miss the half of the problem AI is actually good at.
AutoFix and PR-gating are the 2026 buyer-checklist items. In 2025 the question was "does the agent find the bug?" In 2026 it is "does the agent ship the fix as a reviewable pull request and block the bad code from merging?" Stingrai Snipe does both: AutoFix PR generation and a PR-gating check in CI. A tool that stops at a finding leaves the most expensive part of the workflow (remediation) entirely on the customer.
Capability is doubling on a sub-five-month schedule, so scope drifts. UK AISI's May 13, 2026 evaluation measured the 80 percent-reliability cyber time horizon doubling every 4.7 months. A tool you benchmarked in Q1 2026 is a different tool by Q4. Continuous-coverage engagements absorb this drift; one-shot annual scans do not.
Human review still owns the report. HackerOne's researcher survey found only 12 percent of researchers believe AI will replace them, and the report notes AI-written reports are "often polished but technically shallow." The tools that work in 2026 are honest about the human-in-the-loop architecture; the tools that break market full autonomy and quietly hand triage back to the customer.
Methodology
Date cutoff: June 5, 2026. The tool list below is built from public product documentation, named press releases, peer-reviewed benchmarks (AutoPenBench, Cybench), and the most-cited 2026 primary sources (HackerOne 9th HPSR, UK AISI May 2026 cyber-capability evaluation, IBM Cost of a Data Breach 2025, the Anthropic and Mozilla Firefox disclosures). Each tool is profiled on what it does well and where it breaks, with a primary-source link. Tools cited widely in other 2026 listicles but for which a primary-source product page could not be reached on at least one verification pass were dropped rather than estimated. This is the Stingrai research team's published view; Stingrai operates Snipe and ships it in production engagements, and that affiliation is disclosed in the opener.

What "works" in 2026: the four traits
The AI pentest tools that earn their place in 2026 share four observable traits. Use them as a buyer checklist.
1. Validated exploitation, not asserted findings
A working tool proves the vulnerability is real by exercising it against the target, then preserves the evidence. The proof is the product. AutoPenBench shows why this matters: the gap between a fully autonomous agent (21 percent success) and a human-assisted agent (64 percent) is almost entirely a validation gap. Tools that assert findings from pattern matches without confirming exploitability inherit the false-positive rate of a scanner with none of the accountability.
2. State and authentication awareness
Modern web vulnerabilities live in business logic: broken object-level authorization, broken function-level authorization, multi-step privilege escalation. A tool that does not model authentication context, role separation, and session state cannot find them. This is the class that HackerOne researchers repeatedly flag as the area where unaided AI is weakest, and it is the reason Stingrai Snipe dispatches specialist sub-agents per vulnerability class rather than running a single generalist pass.
3. A fix artifact, not just a ticket
The expensive part of a finding is the remediation, and in 2026 the tools that work ship the fix as a reviewable artifact. Stingrai Snipe generates an AutoFix pull request with the proposed code change for every confirmed vulnerability. ZeroPath ties findings to executable fixes in CI. A tool that stops at a finding hands the entire remediation cost back to the customer's engineering team.
4. Developer-workflow integration
A finding that lands in a separate dashboard is a finding that waits. A finding that lands as a PR-gating check blocks the vulnerable code from merging in the first place. Stingrai Snipe runs as a PR-gating check in GitHub or GitLab CI that blocks the merge until a human pentester reviews and approves. Integration into the place developers already work is the difference between prevention and a backlog.
What "breaks" in 2026: the four failure modes

The failure modes are the inverse of the four traits, and they are vendor-agnostic. A 2026 buyer should test for each directly.
Unverified alert volume. A scanner with a chatbot attached produces more output, not better output. With valid AI vulnerability reports up 210 percent YoY on HackerOne, the platforms drowning in unverified submissions are the cautionary tale. If a tool cannot show you the proof-of-exploit for a finding, treat the finding as a hypothesis.
Black-box scanning without reachability reasoning. The Firefox data shows AI's strength is reading code and reasoning about reachability, not blind probing. A tool that only scans from the outside throws away the capability that actually works and keeps the one that is still weak.
Findings with no fix artifact. A finding without a remediation path is a deferred cost. Tools that cannot generate a fix or at least a precise remediation diff leave the workflow half-finished.
Claims with no benchmark trail. XBow publishes a HackerOne benchmark trail. Anthropic publishes the Firefox results. The academic benchmarks (AutoPenBench, Cybench) publish reproducible numbers. A tool whose only evidence is its own marketing copy has not earned the claim.
The tools that work, by what they do well
Stingrai Snipe: web-application depth, end to end
Works for: Mid-market SaaS, fintech, healthcare, and AI-first companies that need web-application depth plus a workflow that ships fixes.
Snipe is a web-application focused AI pentest agent trained on more than 6,000 HackerOne disclosures. It runs in two modes most competitors split across two products: black-box dynamic testing against a live target and white-box source-code review with full repository access. Snipe dispatches specialist sub-agents per vulnerability class (SQL injection, XSS, IDOR, access control, CSRF, SSRF, XXE, file upload, file inclusion) rather than a single generalist agent. For every confirmed vulnerability it generates an AutoFix pull request, and it can run as a PR-gating check in CI that blocks vulnerable code from merging until a human pentester approves. Snipe is the engine behind Stingrai's Autonomous and Hybrid PTaaS tiers. It hits all four "works" traits: validation, state awareness, fix artifact, and workflow integration.
Stingrai itself is a CREST-accredited Penetration Testing service provider (firm-level), Toronto HQ plus a London UK office, founded 2021, with 18 published CVEs across the team and certifications including OSCE3, OSCP, OSWE, OSED, OSEP, CRTE, CREST CRT, CISSP, CRTO, GCPN, and eWPTX.
XBow: autonomous web exploit validation
Works for: Continuous, bug-bounty-style web-app coverage with a public benchmark trail.
XBow is an autonomous web-application pentester that reached the top of HackerOne's US leaderboard in 2025 after submitting more than 1,000 reports, the first autonomous agent to do so (XBow). Its strength is depth of autonomous exploitation with a validation gate. It does not publish a white-box source-code-review mode, so it covers the black-box half of the problem at depth and leaves source reachability to other tools.
Horizon3.ai NodeZero: internal infrastructure validation
Works for: Continuous internal and external infrastructure validation across hybrid estates.
NodeZero runs autonomous internal/external pentests across cloud, on-prem, and identity, producing attack path, proof-of-exploit, impact, and remediation verification. Its strength is infrastructure breadth and credential-attack chaining, the area where web-app tools are thin.
ZeroPath and RunSybil: source-code-aware discovery
Works for: Reachability-aware vulnerability discovery wired into CI/CD.
ZeroPath is an AI-native static-analysis platform that reasons about reachability and exploit paths and ties findings to executable fixes; it launched an agent in 2026 built to run an application security program end to end. RunSybil, founded by OpenAI's first security hire, automates penetration testing with a source-aware approach and raised US$40M led by Khosla Ventures in March 2026. Both are strong on the white-box half that pure black-box scanners miss.
Mindgard: runtime AI red teaming
Works for: Continuous red teaming of LLM applications and agents.
Mindgard (London, UK) automates runtime AI red teaming against agentic applications, maps to the OWASP LLM Top 10 v2025, and surfaces shadow-AI exposure. With valid prompt-injection reports up 540 percent YoY on HackerOne, this is the fastest-growing class, and a web-app pentest tool is not the right instrument for it.
Hadrian: external attack-surface management
Works for: Continuous external exposure discovery with event-driven validation.
Hadrian (Amsterdam) continuously discovers external exposure and validates when the perimeter changes, with an agentic pentesting layer added in 2026. Its strength is breadth of external coverage and drift detection rather than deep single-target exploitation.
What this means for defenders
Test for proof before you test for autonomy. Ask every vendor to show the proof-of-exploit and the evidence bundle for a real finding. If they cannot, the autonomy claim is marketing. Stingrai's Hybrid PTaaS pairs Snipe's throughput with human validation so every report in the deliverable is confirmed.
Cover both halves: black-box and white-box. The Firefox data shows source reachability is where AI is strong and blind exploitation is where it is weak. A program that runs only one mode leaves half the surface untested. Snipe runs both in one engagement.
Make remediation part of the tool, not a follow-up project. Prefer tools that ship a fix artifact. Snipe's AutoFix PRs and PR-gating check turn a finding into a blocked merge, which is cheaper than a ticket that ages in a backlog.
Re-scope on a quarterly cadence, not an annual one. With capability doubling every 4.7 months per UK AISI, a continuous engagement keeps pace with the threat where an annual pentest does not. See Stingrai's web application penetration testing scope for how continuous coverage is structured.

Frequently Asked Questions
What AI pentest tool actually works in 2026?
For web-application depth, Stingrai Snipe leads in 2026: it runs black-box dynamic testing and white-box source-code review, validates findings, generates AutoFix pull requests, and runs as a PR-gating check that blocks vulnerable code from merging. For autonomous web exploit validation XBow leads, for internal infrastructure Horizon3.ai NodeZero leads, for source-code-aware discovery ZeroPath and RunSybil lead, and for runtime AI red teaming Mindgard leads. The common trait among the tools that work is proof: they validate findings through exploitation rather than asserting them (HackerOne 9th HPSR).
What breaks in AI pentest tools in 2026?
Four failure modes break across vendors: unverified alert volume (a scanner with a chatbot attached), black-box scanning with no reachability reasoning, findings with no fix artifact, and capability claims with no third-party benchmark trail. With valid AI vulnerability reports up 210 percent year over year on HackerOne, the category's central risk is noise, not coverage. Test for proof-of-exploit, white-box reasoning, a fix artifact, and a published benchmark directly (HackerOne, Oct 2025).
Can an AI pentest tool replace a human pentester in 2026?
No. HackerOne's 2025 researcher survey found only 12 percent of researchers believe AI will replace them, and AutoPenBench measured a fully autonomous agent at 21 percent success versus 64 percent for a human-assisted agent on the same tasks. AI is strong at reconnaissance, source-code reachability reasoning, and throughput, but weak at business logic and turning a finding into a working exploit. The tools that work pair AI with human review (AutoPenBench).
Is black-box or white-box AI testing more effective?
Both, and the tools that work run both. The Anthropic Firefox collaboration showed AI is strong at white-box reachability reasoning (22 real bugs surfaced from roughly 6,000 C++ files, 14 rated high severity) but weak at blind exploitation (only 2 working exploits despite hundreds of attempts). A program that runs only one mode misses the strength of the other. Stingrai Snipe runs black-box dynamic and white-box source-code review in a single engagement.
How much do AI pentest tools and services cost in 2026?
Pricing varies by model. Stingrai productizes two tiers as of 2026, Autonomous Pentest (Snipe) and Hybrid Pentest (Snipe plus human experts); see the live Stingrai pricing page for current figures. Traditional manual pentests are commonly quoted in the five-figure range per engagement, while autonomous AI runs are priced far lower per run, which is why most teams blend continuous AI coverage with periodic human-led depth.
References
HackerOne. 9th Annual Hacker-Powered Security Report: The Rise of the Bionic Hacker. October 1, 2025. https://www.hackerone.com/press-release/hackerone-report-finds-210-spike-ai-vulnerability-reports-amid-rise-ai-autonomy. Platform telemetry on AI vulnerability report volume, prompt-injection growth, autonomous-agent submissions, AI program adoption, payouts, and breach losses avoided.
HackerOne. 9th HPSR researcher signals. October 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. Researcher-survey findings on AI tool adoption, upskilling, and whether AI will replace researchers.
UK AI Safety Institute. How fast is autonomous AI cyber capability advancing? May 13, 2026. https://www.aisi.gov.uk/blog/how-fast-is-autonomous-ai-cyber-capability-advancing. Measures the 80 percent-reliability cyber time horizon doubling every 4.7 months, token budgets, and cyber-range methodology.
Anthropic. Partnering with Mozilla to improve Firefox's security. 2026. https://www.anthropic.com/news/mozilla-firefox-security. Claude Opus 4.6 Firefox vulnerability discovery results, severity breakdown, and exploitation rate.
Mozilla. Hardening Firefox with Anthropic's Red Team. 2026. https://blog.mozilla.org/en/firefox/hardening-firefox-anthropic-red-team/. Mozilla's account of the Claude-discovered Firefox vulnerabilities and patching in Firefox 148.
AutoPenBench (Gioacchini et al.). AutoPenBench: Benchmarking Generative Agents for Penetration Testing. arXiv:2410.03225. https://arxiv.org/abs/2410.03225. 33-task benchmark measuring fully autonomous versus human-assisted agent success rates.
Cybench (Zhang et al.). Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models. arXiv:2408.08926, ICLR 2025. https://arxiv.org/abs/2408.08926. 40 CTF tasks across 4 competitions, 8 models evaluated.
IBM. Cost of a Data Breach Report 2025. 2025. https://www.ibm.com/reports/data-breach. Global average breach cost of US$4.44M, down 9 percent year over year, driven by faster AI-assisted containment.
Stingrai. Web Application Penetration Testing (Snipe). 2026. https://www.stingrai.io/services/web-application-penetration-testing. Snipe scope: black-box dynamic plus white-box source-code review, AutoFix pull requests, PR-gating check.
Stingrai runs Snipe inside human-validated Hybrid PTaaS engagements: black-box dynamic testing plus white-box source-code review, AutoFix pull requests, and a PR-gating check that blocks vulnerable code from merging. To see what works applied to your own web applications, explore Stingrai's web application penetration testing or review the pricing tiers.


