
A 2026 explainer for AppSec leaders, CISOs, and engineering managers evaluating AI-powered application penetration testing. We define the hybrid model, explain "human-on-the-loop," verify the accuracy data, and compare the two leading services.
TL;DR: AI-Powered Application Penetration Testing in 2026
AI-powered application penetration testing is not a scanner with a chatbot bolted on. It is a hybrid system: an agentic AI engine for breadth and speed, plus human pentesters for validation and judgment. The model exists for one reason, which the data makes plain.
The core finding: Autonomous agents exploited only 13 to 21 percent of real-world production CVEs alone, rising to 64 percent with human assistance (Hadrian, 2026). The human is the multiplier, not the overhead.
Researcher sentiment: Only 12 percent of researchers believe AI will replace them; more than two-thirds already use AI in their workflow (HackerOne 2025 9th HPSR).
The hybrid pattern: Agentic engine for full-surface coverage, human validation on every finding, feedback into engineering. This is the "human-on-the-loop" architecture both leading services use.
Stingrai Snipe: Black-box plus white-box code review, AutoFix PRs, PR-gating, trained on 6,000+ HackerOne reports, every finding human-validated, with a "No High or Critical Finding = Don't Pay" guarantee (Stingrai pricing).
Bishop Fox Cosmos AI: Managed human-on-the-loop service, validated findings in 2 to 5 business days, focused on authenticated surfaces and exploitable attack paths (Bishop Fox).
When to buy it: When you need authenticated, business-logic-aware application coverage that vulnerability scanning cannot produce.
What "AI-Powered Application Penetration Testing" Actually Means
The phrase is doing a lot of work, so define it precisely. AI-powered application penetration testing is an assessment in which an agentic AI system performs the discovery and exploitation that a human tester would, at machine speed and across the whole application, while human experts set scope, validate findings, and assess business impact.
That is different from three things it is often confused with:
It is not vulnerability scanning. A scanner matches signatures and produces alerts that need triage. AI-powered pentesting reasons about an application, chains weaknesses into attack paths, and proves exploitability.
It is not a fully autonomous tool with no human. Pure autonomy is a real category (XBow is the headline example), but "AI-powered application penetration testing" as sold by enterprise services means AI plus expert validation, not AI alone.
It is not a human pentest with an AI assistant. A consultant using a copilot to write reports faster is still doing a manual test. AI-powered pentesting puts the agent in the exploitation loop, not just the reporting loop.
The defining property is the loop. The AI drives; the human stays on the loop at every critical decision point.
Why Hybrid Beats Pure Autonomy: The Accuracy Data
The reason serious AppSec services are hybrid rather than fully autonomous is not caution. It is measured accuracy.
In controlled benchmarks, AI looks unstoppable: GPT-4 exploited 87 percent of known CVEs and 85 percent across 104 real-world web challenges (Hadrian, 2026). But move to live production targets and the number falls hard. Autonomous agents exploited only 13 to 21 percent of real-world production CVEs on their own. Add a human and it climbs to 64 percent (Hadrian, 2026).
That gap, 85 percent in a benchmark versus 13 to 21 percent in production, is the entire argument for hybrid. The benchmark measures whether a model can solve a clean, well-formed challenge. Production measures whether it can navigate a messy real application: weird auth flows, stateful business logic, non-obvious object references, and the judgment call about whether a finding actually matters. That last part is where humans still dominate. As HackerOne puts it, the most impactful findings still come from researchers who understand what they are testing, and only 12 percent of researchers believe AI will replace them (HackerOne 2025).
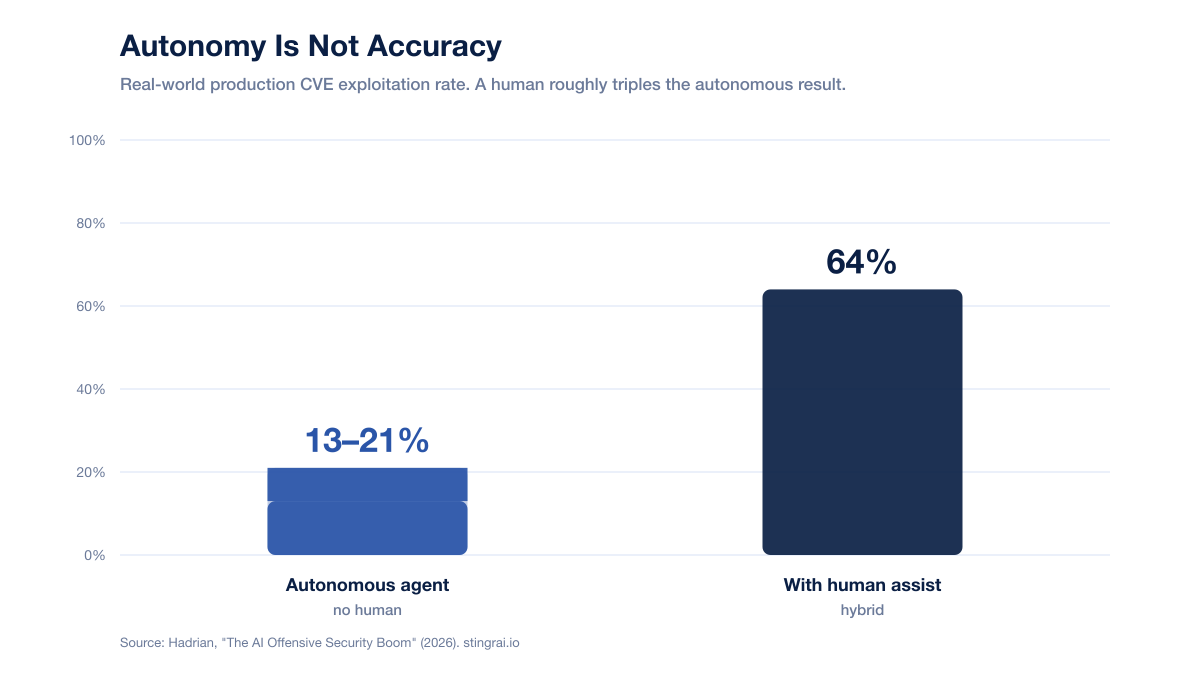
Figure 1: Real-world production CVE exploitation rate, autonomous versus human-assisted. Source: Hadrian, "The AI Offensive Security Boom" (2026).
The Hybrid Workflow, Stage by Stage
A well-run AI-powered application pentest moves through four stages. Both Stingrai and Bishop Fox describe their services in roughly these terms.
Agentic discovery. The AI maps the application: endpoints, inputs, authenticated surfaces, and attack surface. It does this faster and more exhaustively than a human could in the same window.
Agentic exploitation. The agent runs simulated attacks using the same tools a human tester would, employing iterative reasoning and persistent exploration to chain weaknesses into exploitable paths, all at machine speed.
Human validation. Every candidate finding is reviewed, reproduced, and validated by a human pentester. False positives are removed here. Real-world exploitability and business impact are assessed here. This is the stage that converts raw autonomous output into something a CISO can act on.
Engineering feedback. Validated findings flow to the team, ideally as actionable remediation with reproduction steps, and in the strongest implementations as code-level fixes.
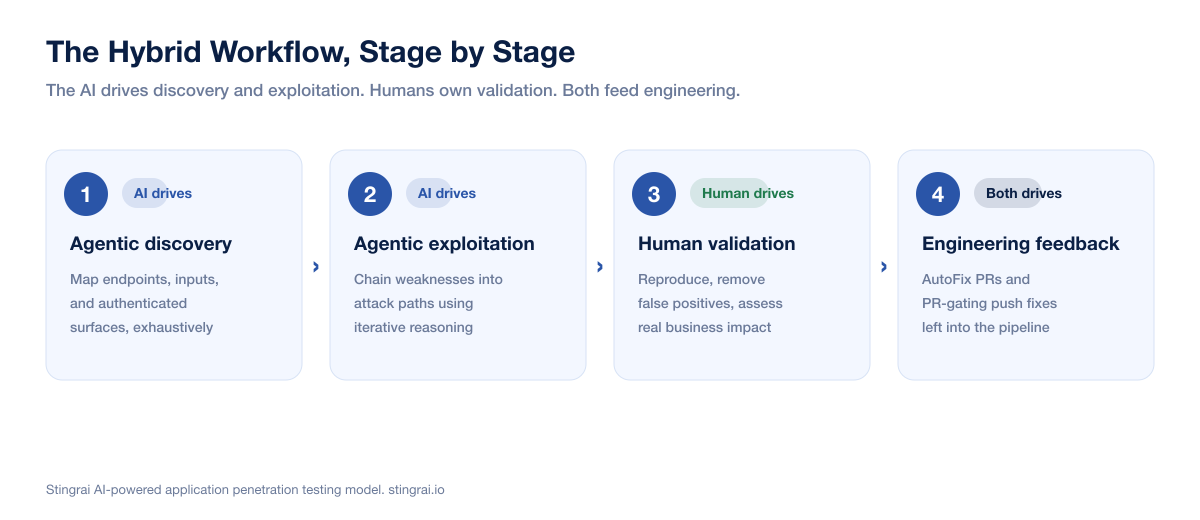
Figure 2: The four-stage AI-powered application penetration testing workflow. The agent drives discovery and exploitation across all classes including IDOR and business logic; senior testers validate and extend findings at stage 3; both feed stage 4.
Stingrai Snipe vs Bishop Fox Cosmos: A Like-for-Like Comparison
The two leading hybrid services share the human-on-the-loop philosophy but differ in how deep they go into the codebase and how they price. Here is the like-for-like view.
Dimension | Stingrai Snipe | Bishop Fox Cosmos AI |
|---|---|---|
Core model | Hybrid: agentic AI plus human-validated findings | Hybrid: human-on-the-loop managed service |
Black-box testing | Yes | Yes |
White-box code review | Yes, reads source and traces data flows to sinks | Not stated as a core capability |
AutoFix pull requests | Yes, patches as PRs with reasoning and tests | Not stated |
PR-gating in CI | Yes, blocks merges that introduce critical issues | Not stated |
Training corpus | 6,000+ real HackerOne reports | Proprietary Cosmos engine |
Turnaround | Same-day autonomous results; hybrid adds expert validation | Most assessments in 2 to 5 business days |
Coverage focus | Web apps and APIs, authenticated surfaces, business logic | Authenticated surfaces, exploitable attack paths, portfolios |
Remediation workflow | AutoFix PRs plus PTaaS portal | Portal with ServiceNow and Jira integrations |
Pricing posture | Productized tiers with "No High or Critical Finding = Don't Pay" | Managed service, quote-based |
Both are credible enterprise choices. Bishop Fox's Cosmos is a polished, fully managed service that explicitly keeps testers "actively involved at every critical decision point" and delivers validated findings in days, with the value proposition that "you're not buying software your team has to learn." Stingrai's Snipe goes a layer deeper into the software development lifecycle: beyond black-box exploitation it reads source code, writes fixes as pull requests, and can sit in the CI pipeline as a PR-gating check that blocks vulnerable code from merging. If your priority is a hands-off managed assessment, Bishop Fox fits. If your priority is shifting findings left into engineering and gating bad code before it ships, Snipe's white-box plus AutoFix plus PR-gating stack is the differentiator.
Where Stingrai Snipe goes deeper
Three Snipe capabilities have no stated equivalent in a black-box-only managed service:
White-box code review. Snipe reads application source, traces taint to dangerous sinks, and surfaces bug classes that need code visibility: a missing authorization decorator, a dangerous deserialization path, user input reaching a query. A black-box agent cannot see these.
AutoFix pull requests. Snipe does not just report; it proposes the patch as a pull request with its reasoning and a regression test, so remediation is a code review, not a research project.
PR-gating. In PR-gating mode, Snipe runs on every pull request and blocks merges that introduce critical issues, moving security left of the merge button.
Stingrai is a CREST-accredited penetration testing service provider founded in 2021, and every Snipe finding is validated by a Stingrai pentester before it reaches the customer dashboard. The result is the breadth of an agent with the accuracy of a human program.
What This Means for Defenders
If you are choosing an AI-powered application pentesting approach in 2026, the data points to a few clear decisions.
Do not buy autonomy without validation. The 13-to-21-percent autonomous accuracy figure is the warning. Whatever engine you choose, insist on human-validated findings so your team triages proof, not probability.
Buy depth where your risk lives. Authenticated application surfaces are where most real risk sits. Make sure the service tests behind login, not just the public perimeter.
Prefer services that close the loop into code. A finding that becomes an AutoFix PR and a PR-gating check is worth more than a finding in a PDF. White-box plus AutoFix plus gating shortens mean-time-to-remediate.
Run it continuously, not annually. AI-powered pentesting is cheap enough to run on every release. Continuous coverage beats a once-a-year snapshot.
Pair it with continuous DAST. Use the agentic pentester for exploit-class depth and a DAST scanner for broad regression coverage between assessments.
Explore how Stingrai runs this in production via Snipe-powered PTaaS and offensive security services.
Frequently Asked Questions
What is AI-powered application penetration testing?
AI-powered application penetration testing is a hybrid assessment in which an agentic AI engine performs discovery and exploitation across the full application surface at machine speed, while human pentesters validate every finding and assess business impact. It differs from vulnerability scanning, which only matches signatures, and from fully autonomous tools, which omit human validation. Stingrai Snipe and Bishop Fox Cosmos AI are the two leading hybrid services in 2026.
Why not just use a fully autonomous AI pentester?
Because autonomy is not accuracy. Autonomous agents exploited only 13 to 21 percent of real-world production CVEs on their own, rising to 64 percent with human assistance (Hadrian, 2026), and only 12 percent of researchers believe AI will replace them (HackerOne 2025). Human validation is what removes false positives and confirms exploitability, so hybrid services consistently outperform pure autonomy on production targets.
What does "human-on-the-loop" mean?
Human-on-the-loop means the AI drives the testing while human experts remain actively involved at every critical decision point, validating findings and applying judgment rather than running the tools themselves. Bishop Fox uses this exact framing for Cosmos, and Stingrai applies the same principle by validating every Snipe finding before it reaches the customer. It contrasts with "human-in-the-loop" (a human approves each step) and "no human in the loop" (full autonomy).
How is Stingrai Snipe different from Bishop Fox Cosmos?
Both are hybrid human-on-the-loop services, but Snipe goes deeper into the software development lifecycle: in addition to black-box testing it performs white-box code review, writes AutoFix pull requests, and can run as a PR-gating check in CI. Bishop Fox Cosmos is a fully managed black-box-focused service delivering validated findings in 2 to 5 business days. Choose Bishop Fox for a hands-off managed assessment; choose Snipe to shift findings left into engineering.
How fast is AI-powered application penetration testing?
Faster than traditional testing. Bishop Fox completes most Cosmos assessments in 2 to 5 business days (Bishop Fox), and Stingrai's autonomous Snipe tier returns same-day results, with the hybrid tier adding expert validation. Traditional manual application pentests typically take weeks to schedule, run, and report.
Does AI-powered application pentesting replace my annual pentest?
It can replace the point-in-time annual model with continuous coverage, which is stronger. Because AI-powered testing is cheap enough to run on every release, you close the 51-week drift window a once-a-year pentest leaves open. For compliance evidence, Stingrai's validated pentest output supports your SOC 2, ISO 27001, HIPAA, and PCI DSS 4.0 audits.
References
Hadrian. The AI Offensive Security Boom: Seventy Tools in Eighteen Months. 2026. https://hadrian.io/blog/the-ai-offensive-security-boom-seventy-tools-in-eighteen-months. Cost economics and autonomous-versus-human-assisted CVE exploitation benchmarks.
HackerOne. 2025 9th Hacker-Powered Security Report: Researcher Signals. 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. Researcher survey on AI adoption and replacement sentiment.
Bishop Fox. AI-Powered Application Penetration Testing. 2026. https://bishopfox.com/services/penetration-testing-services/ai-powered-application-penetration-testing. Cosmos AI human-on-the-loop service description, turnaround, and coverage claims.
AI-powered application penetration testing is the AppSec default in 2026 because it combines machine breadth with human judgment. The engine finds fast; the human confirms it is real. To see the hybrid model with white-box code review, AutoFix PRs, and PR-gating in production, explore Stingrai's offensive security services and Snipe-powered PTaaS.


