
In 2025, an autonomous AI agent reached the top of HackerOne's US bug-bounty leaderboard. The system, XBOW, submitted nearly 1,060 vulnerability reports and outranked the human researchers below it, the first time an autonomous pentester has led a public ranking. In a separate head-to-head, XBOW matched a 20-year veteran pentester's score across 104 web-security benchmarks, solving 85% of them in 28 minutes where the human needed 40 hours. Agentic red teaming stopped being a demo and became a leaderboard fact: adversarial machines that plan, act, interpret feedback, and chain steps on their own, tirelessly, at a pace no human can hold.
Three forces are driving this in 2026. First, adoption is already the default: 70% of security researchers now use AI tools in their workflow (HackerOne 9th Hacker-Powered Security Report). Second, the reports are compounding: valid AI-related vulnerability reports jumped 210% year over year, and prompt-injection reports surged 540% (HackerOne 9th HPSR). Third, the market has already sobered on full autonomy: support for fully automated pentesting fell to 9%, down from 29% a year earlier, and 47% now prefer a hybrid model that pairs automation with human testing (Cobalt State of Pentesting 2025). For CISOs, security buyers, and builders, that is the real story of the year: not machine versus human, but where the line between them actually sits.
This post is the Stingrai research team's canonical 2026 reference on agentic red teaming and the autonomous AI attacker. It carries 15 attributed statistics drawn from four primary publishers: HackerOne, Cobalt, XBOW, and SecurityWeek, plus the foundational ReAct research from Yao et al. Lead survey data is full-year 2025 telemetry, the freshest available, because the primary publishers have not yet released full-year 2026 field reports as of July 2026. Every figure below carries its source, year, and context so any claim can be audited inline.
TL;DR: agentic red teaming by the numbers
AI took the leaderboard (2025): an autonomous agent reached number 1 on HackerOne's US leaderboard after nearly 1,060 vulnerability reports, a first for a fully automated system (XBOW).
28 minutes vs 40 hours (2024 benchmark): across 104 web-security benchmarks an autonomous agent matched a 20-year human pentester's 85% score, in 28 minutes against the human's 40 hours (XBOW).
The judgment gap (2025): 58% of surveyed researchers say AI misses business logic or chained exploits (HackerOne 9th HPSR).
No replacement (2025): only 12% of researchers believe AI could replace them (HackerOne 9th HPSR).
Already default (2025): 70% of researchers use AI tools in their workflow (HackerOne 9th HPSR).
Full-auto retreat (2025): support for fully automated pentesting fell to 9% from 29% a year earlier (Cobalt State of Pentesting 2025).
Hybrid is the preference (2025): 47% of teams now prefer a model combining automation with human testing (Cobalt State of Pentesting 2025).
Automation still blinks (2025): 78% of teams have hit a critical false negative from automated scanning tools (Cobalt State of Pentesting 2025).
AI reports are compounding (2025): valid AI vulnerability reports rose 210% and prompt-injection reports rose 540% year over year (HackerOne 9th HPSR).
The 2026 model: AI drives scale, humans tackle complexity (HackerOne 9th HPSR).
Key takeaways
The market already tested full autonomy and pulled back. The most surprising signal of the year is not that AI got good, it is that buyers reversed course. Support for fully automated pentesting collapsed to 9% from 29% in a single year, and 78% of teams have been burned by a critical false negative from automated scanning (Cobalt State of Pentesting 2025). The correction did not kill autonomy; it repriced it as one half of a hybrid.
Autonomous agents win on breadth and speed, decisively. When the target space is large and the bug classes are pattern-based, a tireless agent that runs 24/7 outpaces any human. An autonomous system matched a 20-year veteran's benchmark score in 28 minutes rather than 40 hours, and topped a public leaderboard with nearly 1,060 reports (XBOW). Coverage at machine scale is now table stakes.
The judgment gap is real and well measured. 58% of researchers say AI misses business logic or chained exploits, and only 12% believe AI could replace them (HackerOne 9th HPSR). These are not fears; they are the classes where intent, authorization, and multi-step creativity decide the finding, and where generic AI still stalls.
Adoption and skepticism are rising together. 70% of researchers already use AI daily even as most reject the idea that it replaces them (HackerOne 9th HPSR). The people closest to the work are the least worried about being displaced and the most eager to use the tools.
The winning 2026 posture is AI-led, human-validated. Independent experts converge on the same line: AI drives scale, humans tackle complexity (HackerOne 9th HPSR); "human pentesters will continue to be irreplaceable" for contextual, unknown vulnerabilities (SecurityWeek Cyber Insights 2026). The gap to close is not "can AI find complex bugs" but "which AI was built to."
Methodology
This post draws on the following primary sources, with publication windows noted:
HackerOne, 9th Hacker-Powered Security Report (2025), published October 2025, reporting on surveyed security researchers and platform vulnerability-report telemetry. Used for the 12%, 58%, 70%, 210%, and 540% figures and the "AI drives scale, humans tackle complexity" framing.
Cobalt, State of Pentesting 2025, a survey of 455 cybersecurity professionals at organizations with 500 or more employees. Used for the 9%, 47%, 78%, and 32% figures.
XBOW company blog (2024 to 2025), for the 104-benchmark head-to-head (40 hours vs 28 minutes, both scoring 85%) and the HackerOne US leaderboard milestone (nearly 1,060 reports). XBOW's own posts state its security team reviewed findings before submission to comply with platform policy on automated tools.
SecurityWeek, Cyber Insights 2026: Offensive Security (Kevin Townsend, January 2026), for 2026 practitioner forecasts and expert quotes on the human-AI division of labor.
Yao et al., ReAct: Synergizing Reasoning and Acting in Language Models (arXiv:2210.03629, ICLR 2023), for the reasoning-and-acting loop that underpins agentic tools.
Research cutoff for this pass was July 2026. Every statistic was checked against a named primary publisher; figures that could not be confirmed against a primary source on at least one verification pass were dropped rather than estimated. Where a widely repeated multiplier ("80x faster") could not be traced to the vendor's own words, we printed the underlying benchmark numbers instead and let the reader do the arithmetic.
What "agentic red teaming" actually means
A conventional vulnerability scanner runs a fixed playbook: it fires known checks, matches signatures, and returns a list. It does not reason about what it found or decide what to try next. Agentic red teaming is different in kind, not degree. An agentic offensive tool is built on a loop, popularized in research as ReAct, or reasoning and acting interleaved (Yao et al., 2023). The model reasons about the target, takes an action against it, observes the result, updates its plan, and acts again. The loop repeats until the agent reaches a goal or exhausts a path.
Layered on top of that reasoning core is the shift from a Large Language Model to what the industry calls a Large Action Model: a system built not just to generate text but to predict and execute sequences of real-world actions with minimal human intervention (TechTarget). In an offensive context, "actions" are HTTP requests, payloads, header manipulations, session replays, and follow-on probes. The agent plans a chain, executes it, reads the response, and decides whether it just found a foothold or a dead end.
Put those two ideas together and you get the practical definition. Agentic red teaming is autonomous offensive testing where the tool plans, acts, interprets feedback, and chains steps by itself, running continuously like a 24/7 virtual red team rather than a scan you kick off and wait on. It is the difference between a tool that checks a list and a tool that pursues a goal. For a broader primer on how autonomous testing differs from traditional scanning, see our guide to what AI pentesting is in 2026.
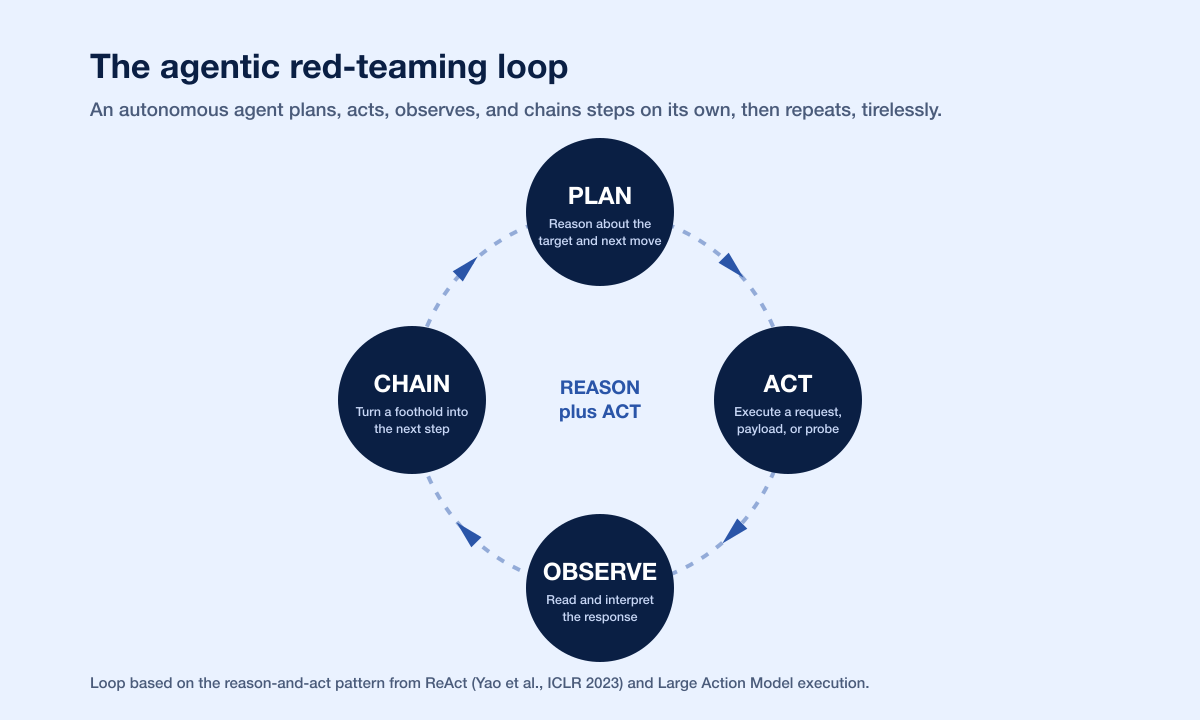
The loop, step by step
Plan. The agent reasons about the target: which endpoints look interesting, which parameter is a likely injection point, which user role to impersonate.
Act. It executes a concrete action, a crafted request, a fuzzed parameter, a forged token.
Observe. It reads the response, a status code, an error, a leaked object, a timing difference, and interprets what changed.
Chain. It uses that observation to plan the next step, chaining a foothold into a deeper exploit, then returns to plan.
Because the loop never tires and can run many chains in parallel, the agent behaves like a red team that works around the clock. That is the source of its power. It is also, as the data shows, the source of a common misunderstanding about its limits.
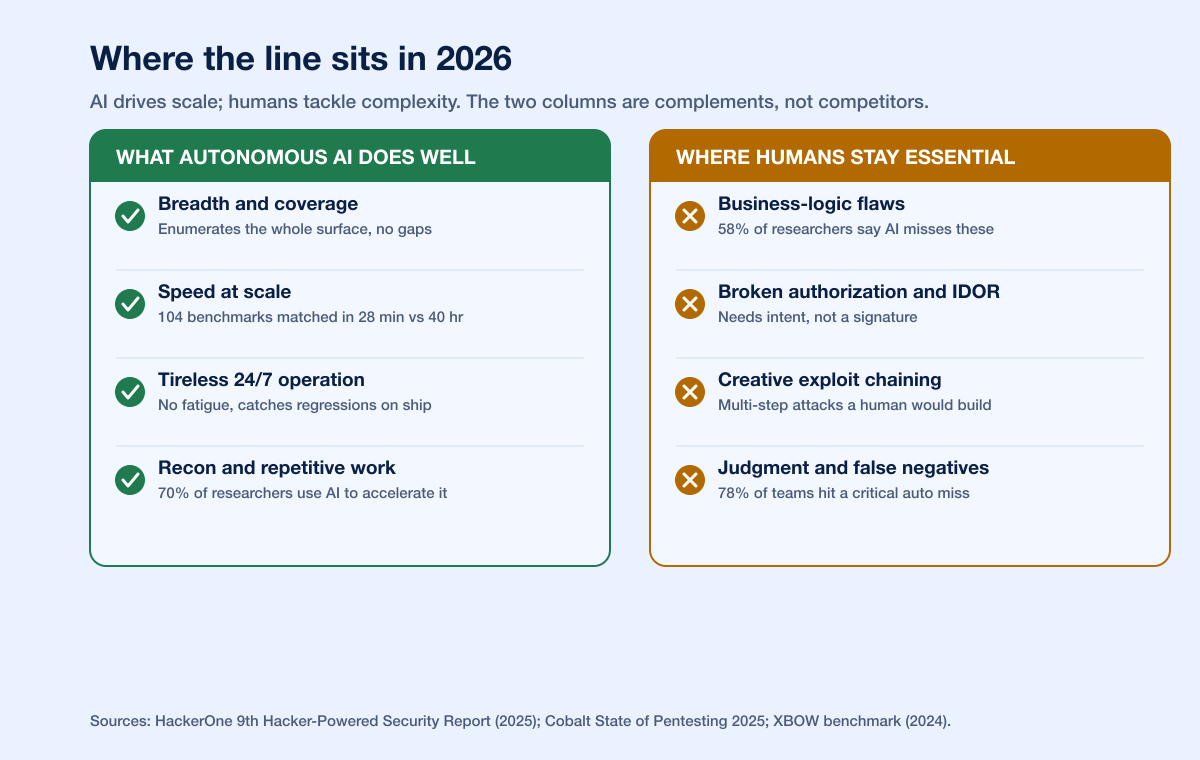
What autonomous AI attackers do well
The strengths are real, and the numbers are not subtle.
Breadth and coverage. An autonomous agent does not skip the boring 80% of an attack surface because it is boring. It enumerates everything. That relentless coverage is exactly why an AI agent could submit nearly 1,060 vulnerability reports and top HackerOne's US leaderboard in 2025 (XBOW). No human researcher matches that volume.
Speed. On pattern-based bug classes, the agent is not a little faster, it is orders of magnitude faster. In XBOW's own 104-benchmark comparison, a principal pentester with more than 20 years of experience and the agent scored the same 85%, but the human took 40 hours and the agent took 28 minutes (XBOW). When the work is high-volume and mechanical, machine speed compounds.
Tireless, 24/7 operation. Humans get tired; agents do not. As one offensive-AI researcher put it in SecurityWeek's 2026 outlook, "Red teaming requires creativity, pattern-breaking thinking, and the ability to try thousands of unconventional attack paths. Humans get tired. AI doesn't" (SecurityWeek Cyber Insights 2026). Continuous testing catches regressions the moment they ship rather than at the next quarterly engagement.
Reconnaissance and repetitive work. This is where adoption started and where it is deepest. 70% of researchers use AI to accelerate reconnaissance, speed up testing, and cut repetitive tasks (HackerOne 9th HPSR). The value here is not clever exploitation; it is throughput.
Where humans are still essential
Now the other half, and it is the half the market cares about most.
The most-cited limitation is not a matter of opinion. 58% of surveyed researchers say AI misses business logic or chained exploits (HackerOne 9th HPSR). These are the vulnerabilities where the flaw is not a malformed input but a violated intention: a checkout flow that lets you skip payment, an object reference that lets you read another tenant's data, an authorization boundary that a legitimate-looking request slips through. There is no signature for "this action should not have been allowed for this user." It takes an understanding of what the application is supposed to do.
HackerOne's own framing is blunt: generic hackbots "lack the creativity, critical thinking, and contextual understanding needed to fully understand and exploit a vulnerability end-to-end" (HackerOne). SecurityWeek's 2026 panel lands in the same place: "Gen-AI still lacks the contextual reasoning required to uncover unknown vulnerabilities, and human pentesters will continue to be irreplaceable" (SecurityWeek Cyber Insights 2026).
The market voted with its budget. Buyers tried full automation, got burned, and pulled back: 78% of teams have experienced a critical false negative from automated scanning tools, support for fully automated pentesting fell to 9% from 29% in a year, and 47% now prefer a hybrid model (Cobalt State of Pentesting 2025). A critical false negative is not a nuisance. It is a real vulnerability the tool confidently missed, which is precisely the failure mode you cannot afford on business-logic and authorization flaws.
One nuance matters, though. "AI misses business logic" is a statement about generic AI, the scanners and off-the-shelf models that were never trained to hunt those classes. It describes a gap in the current tooling, not a law of nature. That distinction is the whole ballgame for 2026.
The hybrid model: AI-led discovery, human-validated
Only 12% of researchers believe AI could replace them, yet 70% use it every day (HackerOne 9th HPSR). Read together, those two numbers describe the destination the whole field is converging on. It is not a standoff between human and machine. It is a division of labor: AI drives scale, humans tackle complexity (HackerOne 9th HPSR).
In practice, the strongest posture in 2026 is AI-led discovery, validated and extended by senior testers. The agent does what it is unmatched at, breadth, speed, continuous coverage, and surfaces candidate findings across the entire surface. Senior humans then do what they are unmatched at: confirm the finding is real and reachable, judge its true business impact, and chain it into the deeper exploit an attacker would actually build. Practitioners describe exactly this split in SecurityWeek's 2026 outlook, forecasting that "we'll see agentic AI applications running red team engagements" while the more sophisticated and novel attacks come from AI-assisted human teams (SecurityWeek Cyber Insights 2026).
The open question that separates strong AI-led programs from weak ones is simple: was the agent built to reach the complex classes, or only the easy ones? An agent that finds cross-site scripting fast but never attempts an authorization bypass leaves the highest-impact bugs on the table. The frontier in 2026 is agents purpose-built to hunt the hard classes, then have every finding validated and extended by senior humans.
Where Stingrai fits: Snipe
Stingrai built its autonomous agent, Snipe, for exactly the profile this data points to. Snipe is an autonomous AI agent for web application penetration testing, and its differentiator is the one the market keeps flagging as the gap. Generic AI scanners cap out at known-class bugs like cross-site scripting, SQL injection, and misconfiguration. Snipe is purpose-built to hunt the complex, high-impact classes that generic tools miss: IDOR, business-logic flaws, and broken authorization and access-control flaws.
That capability is not incidental. Snipe is custom-trained on more than 6,000 HackerOne Hacktivity disclosure reports and on skills distilled from years of Stingrai's human pentesters' methodology, so it encodes how senior testers actually find these bugs rather than only pattern-matching known signatures. It performs both black-box dynamic testing and white-box code review against application source, generates AutoFix pull requests for the issues it finds, and can run as a PR-gating check on every pull request to block vulnerable code before it merges.
Snipe is the reference example of the AI-led-plus-human-validated model this post describes. The agent reaches into the complex classes autonomously; Stingrai's senior pentesters, a team holding OSCE3, OSCP, OSWE, and CREST CRT certifications, validate and extend every finding. Stingrai has been building offensive-security capability since 2021 as a CREST-accredited penetration testing service provider, from its Toronto headquarters and London office, and that pentest work supports clients' SOC 2, ISO 27001, PCI DSS, and DORA compliance programs. If you want to see how the autonomous and hybrid engagements are packaged, the Stingrai pricing page lays out the Snipe-powered autonomous and hybrid tiers.
What this means for defenders
Buy coverage from the agent, buy judgment from the human. Use autonomous testing for breadth and continuous regression detection, and reserve senior pentesters for the business-logic, authorization, and exploit-chaining work where 58% of researchers say AI still falls short (HackerOne 9th HPSR). Explore how Stingrai structures penetration testing services around that split.
Ask vendors which bug classes their AI actually reaches. An agent that finds only known-class bugs is a scanner with better marketing. The differentiator is whether the agent was trained to hunt IDOR, business logic, and broken authorization, not just XSS and SQLi. Our roundup of the top AI security tools for 2026 breaks down where the current tools land on that spectrum.
Do not confuse a passing automated scan with a clean bill of health. 78% of teams have been burned by a critical false negative from automated tools (Cobalt State of Pentesting 2025). Human validation is what turns "no findings" into "verified secure."
Shift testing left with PR-gating. If your agent can review source and gate pull requests, vulnerable code gets caught before it merges rather than after it ships. That is the practical payoff of continuous, agentic testing over quarterly snapshots.
Match the engagement to the risk. Low-risk surfaces can lean on automation; anything touching money, identity, or multi-tenant data warrants AI-led discovery with human validation. See how the Snipe autonomous and hybrid tiers map to those risk levels.
Frequently asked questions
What is agentic red teaming?
Agentic red teaming is autonomous offensive security testing in which an AI agent plans an attack, executes real actions against a target, interprets the feedback, and chains steps toward a goal on its own, running continuously like a 24/7 virtual red team. It is built on a reasoning-and-acting loop, popularized as ReAct (Yao et al., 2023), and on Large Action Models that execute sequences of actions rather than only generating text (TechTarget). It differs from a scanner because it pursues goals and adapts, rather than running a fixed checklist.
Can autonomous AI replace human penetration testers in 2026?
No, and the practitioners closest to the work agree. Only 12% of surveyed researchers believe AI could replace them, even though 70% already use AI tools daily (HackerOne 9th Hacker-Powered Security Report, 2025). AI wins on breadth and speed; humans remain essential for business logic, authorization chains, and creative multi-step exploitation. The prevailing 2026 model is AI-led discovery validated and extended by senior testers.
What do autonomous AI attackers do better than humans?
Breadth, speed, and tireless coverage. An autonomous agent enumerates an entire attack surface without skipping the tedious parts, which is how one agent submitted nearly 1,060 vulnerability reports to top HackerOne's US leaderboard (XBOW, 2025). On pattern-based bug classes it is far faster: in a 104-benchmark test it matched a 20-year pentester's 85% score in 28 minutes versus 40 hours (XBOW, 2024).
What can autonomous AI agents not do well?
Intent-dependent work. 58% of surveyed researchers say AI misses business logic or chained exploits (HackerOne 9th HPSR, 2025). Flaws like broken authorization, IDOR, and multi-step business-logic abuse depend on understanding what the application is supposed to allow, and generic AI tools lack that contextual reasoning. This is a limitation of generic AI, not of every agent; tools built specifically to hunt those classes close the gap.
Is "AI misses business logic" true of all AI agents?
No. The 58% figure describes generic AI tooling, the scanners and off-the-shelf models that were never trained to find business-logic and authorization flaws (HackerOne 9th HPSR, 2025). Agents built and trained specifically to reach those classes are the exception. Stingrai's Snipe, for example, is custom-trained on more than 6,000 HackerOne Hacktivity disclosure reports and on senior-pentester methodology precisely to hunt IDOR, business-logic, and broken-authorization flaws that generic tools miss.
What is the best way to combine AI and human penetration testing?
Run AI-led discovery, then validate and extend every finding with senior human testers. The market has already converged here: support for fully automated pentesting fell to 9% from 29% in a year, while 47% of teams now prefer a hybrid model (Cobalt State of Pentesting 2025). Stingrai's Snipe follows this profile, hunting complex vulnerabilities autonomously with senior pentesters confirming impact and chaining deeper exploits.
References
HackerOne. 9th Annual Hacker-Powered Security Report. 2025. https://www.hackerone.com/report/hacker-powered-security. Survey of security researchers plus platform vulnerability-report telemetry; source of the 12% (AI replacement), 58% (AI misses business logic), and the "AI drives scale, humans tackle complexity" framing.
HackerOne. HackerOne Report Finds 210% Spike in AI Vulnerability Reports Amid Rise of AI Autonomy (press release). 2025. https://www.hackerone.com/press-release/hackerone-report-finds-210-spike-ai-vulnerability-reports-amid-rise-ai-autonomy. Source of the 70% AI-adoption and 210% AI-report-growth figures.
HackerOne. 3 Signals from the 2025 Hacker-Powered Security Report. 2025. https://www.hackerone.com/blog/ai-security-trends-2025. Source of the 540% prompt-injection surge.
HackerOne. The Top Researcher Signals From HackerOne's 2025 HPSR. 2025. https://www.hackerone.com/blog/2025-hpsr-researcher-signals. Corroborates the enhance-not-replace sentiment among researchers.
HackerOne. Welcome, Hackbots: How AI Is Shaping the Future of Vulnerability Discovery. 2025. https://www.hackerone.com/blog/welcome-hackbots-how-ai-shaping-future-vulnerability-discovery. Source of the qualitative limits-of-hackbots framing.
Cobalt. State of Pentesting 2025. 2025. https://www.cobalt.io/blog/key-takeaways-state-of-pentesting-report-2025. Survey of 455 professionals at organizations with 500+ employees; source of the 9%, 47%, 78%, and 32% figures. Full-report coverage: https://securitybrief.news/story/cobalt-study-says-automated-ai-tests-miss-key-flaws.
XBOW. How XBOW Ranked #1 in Autonomous Penetration Testing. 2025. https://xbow.com/blog/top-1-how-xbow-did-it. Source of the nearly-1,060-reports HackerOne US leaderboard milestone; notes human review before submission.
XBOW. XBOW now matches the capabilities of a top human pentester. 2024. https://xbow.com/blog/xbow-vs-humans. Source of the 104-benchmark head-to-head: 40 hours vs 28 minutes, both scoring 85%.
SecurityWeek (Kevin Townsend). Cyber Insights 2026: Offensive Security, Where It Is and Where It's Going. January 2026. https://www.securityweek.com/cyber-insights-2026-offensive-security-where-it-is-and-where-its-going/. Source of the 2026 practitioner forecasts and human-versus-AI expert quotes.
Yao, S., Zhao, J., Yu, D., et al. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629, ICLR 2023. https://arxiv.org/abs/2210.03629. Foundational research on the interleaved reasoning-and-acting loop behind agentic tools.
TechTarget. What is a large action model (LAM)? https://www.techtarget.com/whatis/definition/What-is-a-large-action-model-LAM. Definition of Large Action Models as systems that predict and execute sequences of real-world actions.


