
Scoping a penetration test means defining exactly what testers may attack, what they must leave alone, and under what rules, all agreed in writing before the first packet is sent. Get scoping right and the engagement finds real, exploitable risk. Get it wrong and you either pay for a test that misses your most sensitive systems, or you trigger an outage on something the testers should never have touched. This is the buyer-side guide to doing it well, built from the pre-engagement process a serious offensive-security firm runs on every job.
The core question first: how do you scope a penetration test, and what goes in the rules of engagement? You define eight things. The asset inventory and targets. The written authorization and rules of engagement. The test windows. The out-of-bounds systems. The blast-radius and production-safety limits. The credentials and access levels. The points of contact and deconfliction plan. The success criteria and retest terms. Everything else is detail hanging off those eight.
Scoping guidance is well established. The Penetration Testing Execution Standard (PTES) treats pre-engagement interactions as its own phase. The OWASP Web Security Testing Guide v4 and OWASP API Security Project define what web and API testing should cover, and NIST SP 800-115 (the technical guide to information security testing) frames planning, execution, and post-execution as distinct steps. This checklist maps those standards onto the questions a buyer actually has to answer.
TL;DR: the pentest scoping checklist
Asset inventory and targets: list the exact URLs, IP ranges, hostnames, API specifications, cloud accounts, and code repositories in scope. Vague scope produces vague findings.
Authorization and rules of engagement: get signed, written permission to test from someone who actually owns the assets. Testing without it is a legal and contractual risk, not a technicality.
Test windows: agree the days and hours testing may run, and default to off-peak for anything touching production.
Out-of-bounds systems: name every system, third party, and technique that is explicitly forbidden. This single list prevents most pentest-caused outages.
Blast-radius and production-safety limits: decide up front whether destructive actions, data mutation, and denial-of-service are allowed (usually not on production).
Credentials and access levels: provide the accounts, roles, and tokens for each access tier you want tested, from anonymous through admin.
Points of contact and deconfliction: name the people who can pause the test, confirm suspicious activity is yours, and escalate an incident.
Success criteria and retest terms: define what a successful engagement looks like and how fixes will be verified afterward.
Modern surface (2026): extend scope beyond the web app to APIs, cloud identity boundaries, CI/CD pipelines, and any agentic AI or tool-calling layers your product now exposes.

Key takeaways
A pentest scope is a contract about attack surface, not a wish list. It says precisely what is fair game and what is off limits, so both sides can measure the engagement against the same boundary. When the scope is fuzzy, the report is fuzzy, and disputes about whether a finding was in bounds waste everyone's time.
The out-of-bounds list is the most important safety control you own. Most pentest-caused disruptions trace back to a system the testers assumed was fair game. Third-party assets you do not own, fragile legacy hosts, and payment infrastructure belong on an explicit no-go list, not in an unspoken assumption.
Access level drives depth more than test duration does. A white-box engagement with source code and admin accounts finds authorization and business-logic flaws far faster than a blind black-box test of the same app. If your goal is maximum risk coverage per dollar, provide more context, not just more hours.
Scope now spans layers the old templates never mentioned. APIs, cloud identity boundaries, CI/CD pipelines, and agentic AI or tool-calling features are all live attack surface in 2026. A scope that stops at the browser-rendered web app leaves the parts attackers increasingly target unexamined.
How a vendor scopes is a preview of how they test. A firm that asks sharp pre-engagement questions, insists on written authorization, and pushes you to define out-of-bounds systems is showing attacker-minded rigor before the invoice. Vague, box-ticking scoping usually precedes a shallow report.
A note on sources
This checklist draws on published, primary scoping standards rather than any single vendor's opinion. The Penetration Testing Execution Standard defines pre-engagement interactions as a formal phase. The OWASP Web Security Testing Guide v4 and OWASP API Security Project define testable coverage for web apps and APIs. NIST SP 800-115 frames planning, execution, and reporting as distinct steps in a security test. The operational examples throughout, such as the synthetic in-scope and out-of-bounds lists, reflect the pre-engagement process Stingrai runs on live offensive-security engagements. Every framework named here is linked so any point can be checked at the source.
The eight building blocks of a pentest scope
1. Asset inventory and targets
Start with what exists. You cannot scope a test of assets you have not enumerated, and the single most common cause of a disappointing pentest is a target list that was never accurate to begin with. Write down the exact web application URLs, the IP ranges and hostnames, the API base paths and their specifications (an OpenAPI or GraphQL schema is ideal), the cloud accounts or subscriptions, and the code repositories if a white-box review is in play.
Be specific about environments. "Test our app" is not scope. "Test app.example.com in production and staging.example.com as a safe mirror for destructive checks" is scope. If you have an external attack surface you are not fully aware of, say so; a good partner will help you discover it, but discovery scope and exploitation scope should be agreed separately so nobody attacks an asset you did not know you owned.
2. Authorization and rules of engagement
Testing systems without written permission from someone who owns them is not a formality to skip. The rules of engagement (RoE) document is where that authorization lives, alongside the boundaries of the test. At minimum it records who authorized the engagement, which assets are covered, the allowed and forbidden techniques, the test windows, and the emergency contacts. If you are testing assets hosted by a cloud provider, check whether that provider requires notification or has its own testing policy, and fold that into the RoE.
The authorization has to come from a party with the actual right to grant it. Testing a SaaS product you merely use, rather than own, is a classic scoping trap: you cannot authorize a test of infrastructure that belongs to your vendor.
3. Test windows
Decide when testing may run. For internet-facing production systems, most buyers choose off-peak windows to limit the business impact if something behaves unexpectedly under test. Others prefer testing during business hours precisely so their own monitoring and incident-response team is awake and can observe the activity. Both are valid; the point is to choose deliberately and write it down. Include time zones, blackout dates (end-of-quarter, a major launch, a holiday freeze), and whether the testers may continue automated activity overnight.
4. Out-of-bounds systems
This is the list that prevents outages, and it deserves more attention than it usually gets. Name every system, host, and third party that is explicitly excluded. Common entries: infrastructure you do not own (a payment processor, a shared SaaS platform, an upstream API), fragile legacy hosts your operations team flags as easy to knock over, anything under active incident or migration, and any dataset that must not be modified or exfiltrated. Also list forbidden techniques: denial-of-service and load testing are commonly excluded on production, and physical or social-engineering vectors are usually a separate engagement with separate authorization.

5. Blast-radius and production-safety limits
Blast radius is how much damage a given action could cause if it goes wrong. Scoping it means deciding, before testing, what testers may do to live systems. Can they create and delete test records? Can they attempt actions that mutate other users' data? Is any form of resource exhaustion permitted? On production, the safe default is that exploitation must be demonstrated without destroying data or degrading availability, and anything riskier moves to a staging mirror. Agree how a proof-of-concept will be shown: a screenshot and a reproducible request are usually enough to prove a finding without weaponizing it against real users.
6. Credentials and access levels
Decide which access tiers you want tested and provide credentials for each. An anonymous, unauthenticated pass finds what an outsider sees. A standard-user account exposes authorization and access-control flaws, which are among the highest-impact and most-missed bug classes. An admin or privileged account lets testers verify that privilege boundaries actually hold. If you want the deepest coverage, provide source code and architecture documentation for a white-box review.
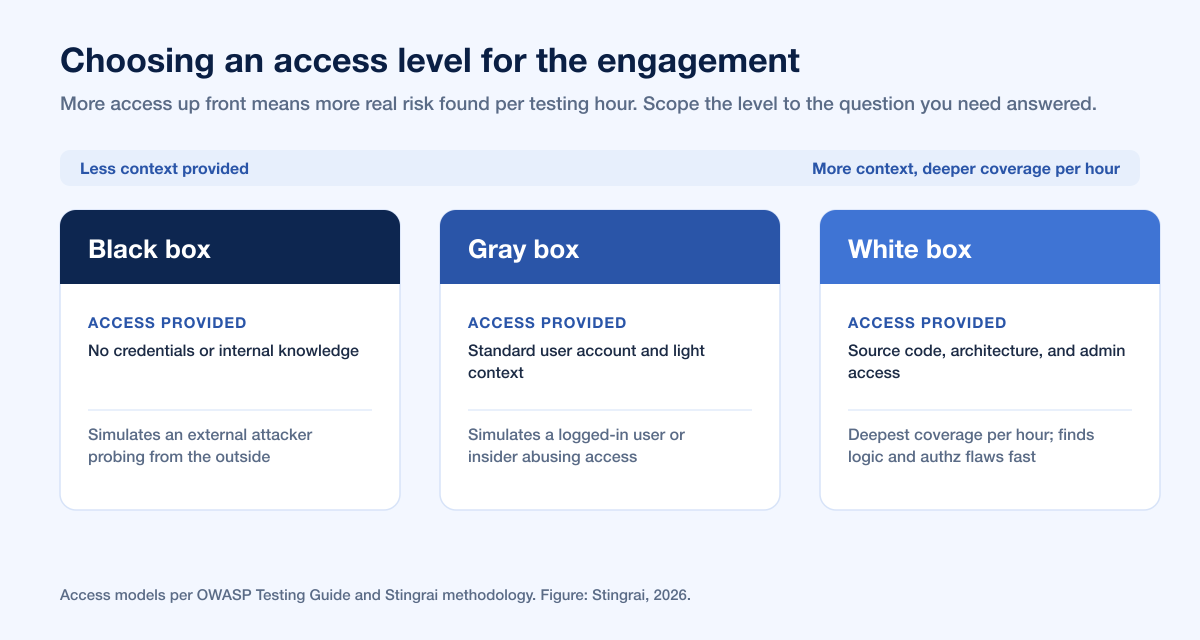
The tradeoff is straightforward. Black-box testing, with no credentials or internal knowledge, simulates an external attacker but spends time on reconnaissance that reveals little about deeper logic. Gray-box testing, with a standard account and light context, targets the authenticated attack surface where authorization flaws live. White-box testing, with code and admin access, gives the deepest coverage per hour because testers are not guessing at how the application works. More context up front means more real risk found in the same window. This is exactly where an AI-augmented approach pays off: Stingrai's Snipe runs both black-box dynamic testing and white-box source-code review, and it is purpose-built to hunt the complex classes, IDOR, broken authorization, and business-logic flaws, that generic scanners miss, so the access you grant translates directly into deeper findings.
7. Points of contact and deconfliction
Name the humans. You need at least a primary technical contact who can answer questions during the test, an escalation contact for anything urgent, and a way for the testers to reach someone fast if they find something actively dangerous (an exposed production database, evidence of a pre-existing compromise). Deconfliction is the process that lets your security team confirm that suspicious activity in the logs is the authorized test, not a real attacker. Agree source IP addresses, a test identifier, or a header the testers will send, so your monitoring does not spend the week chasing your own pentest. Decide in advance who has the authority to pause or stop the engagement.
8. Success criteria and retest terms
Define what good looks like before you start. For some buyers, success is a clean report they can hand to an auditor as evidence for a SOC 2, ISO 27001, or PCI DSS program. For others, it is a specific question answered: can an authenticated user reach another tenant's data? Write the objective down so the engagement can be measured against it rather than against a vague sense of thoroughness. Finally, agree retest terms up front. After you fix the findings, will the testers verify the fixes, and is that verification included or billed separately? Fixing a vulnerability and never confirming the fix landed is how the same issue reappears next year.
What modern scope has to cover in 2026
The classic pentest scope template assumed the target was a monolithic web app behind a login page. That assumption is now incomplete. A scope that stops at the browser-rendered front end leaves the surfaces attackers increasingly go after untested.
APIs. Most applications are now a thin client over a set of APIs, and the API is frequently where authorization is actually enforced (or not). Scope the REST and GraphQL endpoints explicitly, provide the schema, and align coverage to the OWASP API Security Project rather than assuming web-app testing reaches them.
Cloud identity boundaries. Misconfigured IAM roles, over-permissioned service accounts, and trust relationships between cloud tenants are a major source of real-world breaches. If your app runs in the cloud, scope the identity boundary: which roles can assume which, and whether a foothold in the app translates into cloud-wide access.
CI/CD pipelines and secrets. The build pipeline is production-adjacent infrastructure with access to source, secrets, and deployment. Decide whether the pipeline, its runners, and its secret stores are in scope, because a compromised pipeline can be a faster path to production than the app itself.
Agentic AI and tool layers. If your product now exposes an LLM feature, an agent that calls tools, or a chatbot with access to internal functions, that is live attack surface. Prompt injection, tool-abuse, and excessive-agency issues do not show up in a traditional web-app test. Name these features in scope, provide access to the agent and any tools it can invoke, and treat them as a first-class part of the engagement. For teams shipping these features fast, Stingrai's PTaaS and red-teaming services are built to probe both the application and the AI layer.
What good scoping tells you about a vendor
Scoping is the first working session you have with a testing partner, and it is a reliable tell. A serious, attacker-minded firm asks pointed questions early: what is the most sensitive data in this app, which user roles exist, what would hurt most if it broke, what have you never had tested before. They insist on written authorization. They push you to define out-of-bounds systems rather than letting you wave the question away. They map your assets to standards like the OWASP Testing Guide and PTES so coverage is defensible, not improvised.
A vendor that rushes scoping, accepts a one-line target list, and never asks about your production-safety limits is showing you how the test itself will go. The care taken in the pre-engagement phase is the strongest early signal you get. Stingrai runs this process on every engagement across web application testing and beyond, because a scope defined by an attacker's questions finds risk that a scope defined by a checklist alone will miss.
The rules-of-engagement checklist you can copy
Use this as the skeleton of your RoE document.
Targets: exact in-scope URLs, IPs, hostnames, API endpoints, cloud accounts, repositories, and environments (production versus staging).
Authorization: name and title of the authorizing owner, date, and a statement that they have the right to grant it.
Access levels: which tiers are tested (anonymous, standard user, admin, white-box) and the credentials provided for each.
Test windows: allowed days, hours, time zone, and any blackout dates.
Out-of-bounds: every excluded system, third party, dataset, and technique (denial-of-service, data destruction, social engineering) stated explicitly.
Production-safety limits: whether destructive actions and data mutation are permitted, and how a proof-of-concept will be demonstrated safely.
Contacts and deconfliction: primary technical contact, escalation contact, source IPs or test identifiers, and who may pause the engagement.
Success criteria: the specific questions the test must answer and the deliverable expected.
Retest terms: whether fix verification is included, and the window for it.
Modern layers: explicit line items for APIs, cloud identity, CI/CD, and any agentic AI or tool features.
Frequently asked questions
How do you scope a penetration test and what should be in the rules of engagement?
To scope a penetration test, you define eight things: the asset inventory and targets, written authorization, test windows, out-of-bounds systems, blast-radius and production-safety limits, credentials and access levels, points of contact and a deconfliction plan, and success criteria plus retest terms. The rules of engagement document captures all of these, most importantly who authorized the test, exactly which assets are in scope, and which systems and techniques are explicitly forbidden. Scoping guidance is defined in PTES, the OWASP Web Security Testing Guide, and NIST SP 800-115.
What are the rules of engagement in penetration testing?
The rules of engagement (RoE) are the written boundaries and authorization for a test. They record who granted permission, the in-scope assets, the allowed and forbidden techniques, the test windows, the production-safety limits, and the contacts for deconfliction and escalation. The RoE protects both sides: it authorizes the tester to act and it constrains that action to what the buyer agreed.
What questions should I expect in a pentest pre-engagement call?
Expect questions about your most sensitive data, the user roles and access tiers in the app, which environments exist, what is off limits, your test-window preferences, and how fixes will be verified. A strong partner also asks what you have never had tested and what would hurt most if it broke, because those questions shape a scope around real risk rather than a generic template.
What systems should be out of scope for a penetration test?
Anything you do not own or cannot authorize should be out of scope, including payment processors, shared SaaS platforms, and upstream third-party APIs. Fragile legacy hosts, systems under active incident or migration, and any dataset that must not be modified or exfiltrated also belong on the out-of-bounds list. Denial-of-service and load testing are commonly excluded on production systems, and physical or social-engineering vectors are typically a separate, separately authorized engagement.
Should a penetration test run against production or staging?
It depends on the risk. Non-destructive testing often runs safely against production because that is where the real configuration lives, but destructive checks, data-mutation attempts, and anything with a large blast radius should move to a staging mirror. Agree the split in the rules of engagement and default to off-peak windows for any production testing.
What is the difference between black-box, gray-box, and white-box scope?
Black-box testing provides no credentials or internal knowledge and simulates an external attacker. Gray-box testing provides a standard user account and light context, targeting the authenticated attack surface where authorization flaws live. White-box testing provides source code, architecture, and admin access, giving the deepest coverage per hour. More context provided up front generally yields more real risk found in the same testing window.
How do I scope an agentic AI or LLM feature for a pentest?
Name the AI feature explicitly in scope, provide access to the agent and every tool or function it can invoke, and treat it as first-class attack surface rather than an add-on to the web-app test. The relevant risks (prompt injection, tool abuse, and excessive agency) are not covered by traditional web-app testing, so the scope must call them out and the tester must have the access needed to probe them.
Does penetration test scope include a retest to verify fixes?
It should, but only if you agree it up front. Define in the rules of engagement whether fix verification is included in the engagement or billed separately, and set a window for it. Verifying that a fix actually landed is how you avoid the same vulnerability reappearing in the next test cycle.
Ready to scope your next test with a partner that asks the right questions?
Good scoping is the first sign of an attacker-minded firm, and it is where Stingrai's engagements begin. Stingrai is a CREST-accredited penetration testing service provider offering web application testing, red teaming, and AI-augmented PTaaS across web, API, cloud identity, and agentic AI layers, with pentest evidence that supports your SOC 2, ISO 27001, and PCI DSS compliance programs. See the full service range or review pricing to plan your next engagement.


