
Yes, running an autonomous pentest against production can be safe, but only when the agent operates inside enforced scope with an immediate stop control, impact limits, human sign-off on destructive actions, and a full audit trail. The risk that blocks most purchases is not the AI's reasoning quality. It is autonomy without containment: a self-directing attacker that mutates data, invents an out-of-scope target, or drives request volume that looks like an outage. Get the containment controls right and the availability fear largely dissolves. Skip them and no amount of model accuracy makes the engagement safe.
This post lays out the real operational risks of pointing an autonomous, self-directing agent at live systems, then gives you a vendor-agnostic control checklist to demand before you sign. It is written for the security and platform owners who actually carry the pager: the people who will get paged at 2 a.m. if a test knocks production over.
Autonomous pentesting is not inherently reckless, and it is not automatically safe either. The variable is containment. An agent that can reason its way to an IDOR chain is powerful precisely because it acts on its own hypotheses at machine speed. That same property is what makes an uncontained agent dangerous against production. The controls below exist to keep the power and remove the gamble.
Why the availability fear is legitimate
Security buyers are right to be nervous. Agentic systems inherit permissions, chain tool calls across systems, and can take irrevocable actions at machine speed, which is exactly why NIST reopened its AI Risk Management Framework for agent-specific guidance and received 937 public comments in response (NIST, AI RMF agent guidance process, 2025). The Berkeley and Cloud Security Alliance work on agentic profiles keeps returning to the same theme: an autonomous agent needs a bounded scope, or, put plainly, it needs to be on a leash (Cloud Security Alliance, Agentic NIST AI RMF Profile, 2026).
The offensive-security community reaches the same conclusion from the other direction. One security team's assessment is blunt: agentic AI pentesting is inherently unsafe for production environments and can only be used there after extensive sandbox testing and with strict controls (Synack, The Role of Agentic AI in Penetration Testing). Read that as a warning about defaults, not a verdict on the technology. The point is that the safety comes from the controls wrapped around the agent, not from the agent alone.
The four operational risks, and what actually causes them
Before you evaluate any control, name the failure modes you are containing. Autonomous pentesting against production has four operational risk clusters. Each maps to a different control.
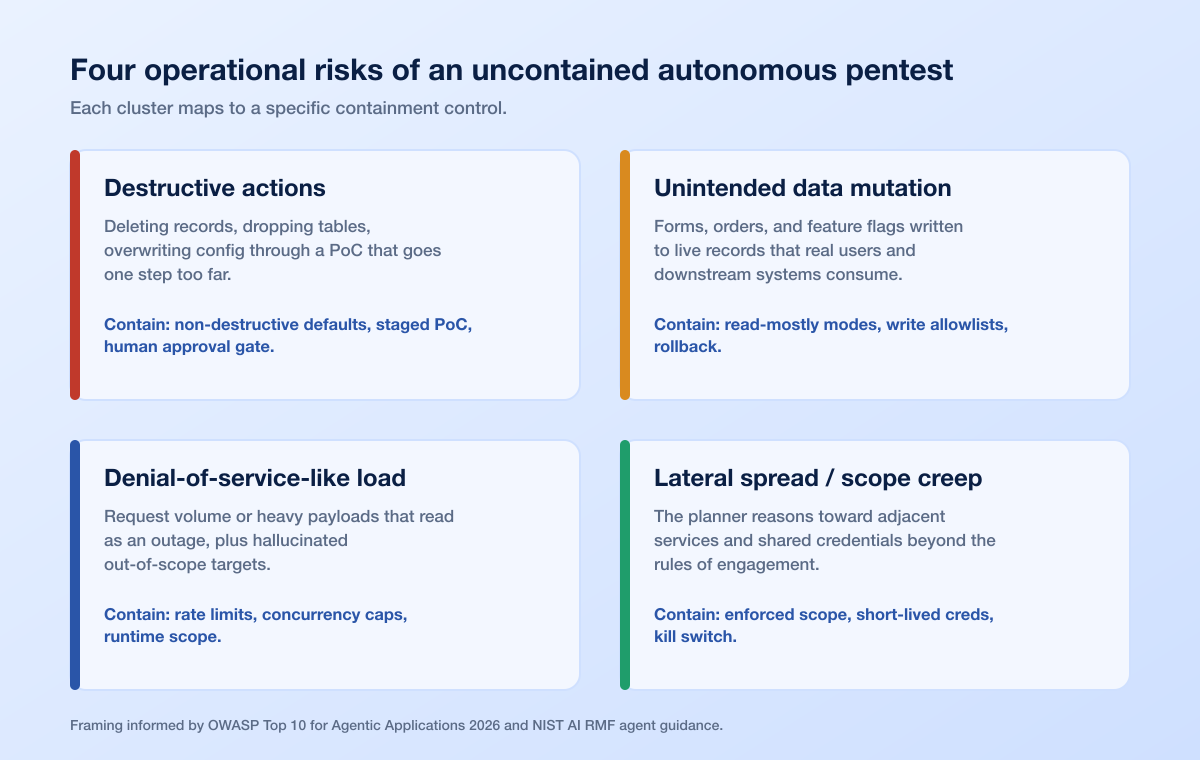
1. Destructive actions
An agent exploring a live application may attempt state-changing operations: deleting records, disabling accounts, dropping tables through an injection path, or overwriting configuration. In research settings, agents have been observed modifying essential files on a host and rendering it unusable. The classic cause is a proof-of-concept that goes one step too far: instead of demonstrating that a delete endpoint is reachable, the agent actually calls it.
Contained by: non-destructive defaults, a staged proof-of-concept requirement, and a human approval gate on any state-changing action.
2. Unintended data mutation
Even without a destructive intent, an autonomous tester can corrupt production data. Filling forms, submitting orders, toggling feature flags, or writing to a shared record can leave live data in a state real users and downstream systems then consume. This is the quiet risk: nothing crashes, but your data integrity is compromised and you may not notice for days.
Contained by: read-mostly modes, write-action allowlists, and rollback or snapshot procedures scoped to the test window.
3. Denial-of-service-like load
A self-directing agent can generate request volume, connection churn, or resource-intensive payloads that read as a denial-of-service event to your infrastructure, even when the intent was benign enumeration. Autoscaling can mask the load until the bill arrives, or the load can trip rate limiters and lock out real users. Agents can also hallucinate a target IP or hostname and begin probing a system that was never in scope.
Contained by: rate limits, concurrency caps, blast-radius ceilings, and runtime scope enforcement that rejects any target outside the authorized set.
4. Lateral spread and scope creep
Once an agent gains a foothold, its planning loop may reason its way toward adjacent systems: a linked internal service, a shared credential, a trust relationship it discovers mid-run. Without a hard boundary, the engagement quietly expands beyond the rules of engagement. OWASP's 2026 agentic work names the compromised or drifted version of this as a Rogue Agent, an agent that has deviated from its authorized scope through misalignment, reward hacking, or emergent behavior (OWASP Gen AI Security Project, OWASP Top 10 for Agentic Applications 2026).
Contained by: enforced runtime scope, short-lived and narrowly scoped credentials, and an immediate stop control.
The buyer's blast-radius control checklist
This is the vendor-agnostic list to demand. Do not accept "we're careful" as an answer. Ask the vendor to demonstrate each control and to show you where it is logged.

# | Control | What to demand | Why it matters |
|---|---|---|---|
1 | Enforced runtime scope | Machine-readable allowlist and denylist checked at runtime on every action, not just a scope document signed at kickoff | Stops out-of-scope targeting from hallucinated hosts and blocks lateral spread |
2 | Immediate stop / kill switch | A single control that halts all agent activity in seconds, plus automatic credential revocation | Contains a rogue or misbehaving run before damage compounds |
3 | Rate and impact limits | Configurable request rate, concurrency caps, and a blast-radius ceiling on volume and resource use | Prevents denial-of-service-like load and surprise autoscaling |
4 | Staging-versus-production policy | A written rule for what runs where, with production reserved for validated, non-destructive activity | Lets you exercise destructive classes safely in staging first |
5 | Human-in-the-loop checkpoints | Mandatory human approval before any destructive or high-impact action executes | Keeps irrevocable actions under human authority |
6 | Full audit trail | Tamper-evident, immutable logs recording who, what, when, why, and scope for every action | Gives you replay, accountability, and evidence for compliance |
7 | Rollback and recovery | Snapshot or rollback procedures scoped to the test window, agreed before the run | Restores data integrity if a write slips through |
1. Enforced runtime scope
Scope on paper is not scope. The document you signed at kickoff does nothing if the agent's own planner picks a target. Demand scope that is enforced in code at runtime: a canonical, machine-readable allowlist and denylist queried before every single action, so an out-of-scope host or endpoint is rejected mechanically rather than left to the model's judgment. This is the single highest-leverage control, because it addresses the two scariest failure modes at once, hallucinated targeting and lateral spread.
2. Immediate stop and kill switch
You need one button that stops everything, fast. The kill switch should halt all in-flight actions within seconds and revoke the agent's credentials so a paused agent cannot silently resume. Ask the vendor to demonstrate it live and ask how long it takes to take effect. A kill switch that requires a support ticket is not a kill switch. Verify it works before the engagement, not during an incident.
3. Rate and impact limits
Set ceilings and make them explicit. Request rate, concurrent sessions, and a hard cap on the total volume or resource cost of a run all belong in the rules of engagement. These limits are what separate aggressive enumeration from an outage. They also protect you from the second-order cost of autoscaling absorbing the load quietly until the invoice arrives.
4. Staging-versus-production policy
The safest way to test a destructive class is to test it somewhere it cannot hurt real users. A mature autonomous-pentest program treats staging as the default proving ground for anything state-changing, promotes only validated, non-destructive checks to production, and documents the rule. When a finding does need production confirmation, it happens as a controlled, minimal, non-destructive validation, not a full exploit.
5. Human-in-the-loop checkpoints
Full autonomy and full safety are not the same goal. For any destructive or high-impact action, a human must acknowledge and authorize before the agent proceeds. This is the checkpoint that keeps irrevocable actions under human authority.
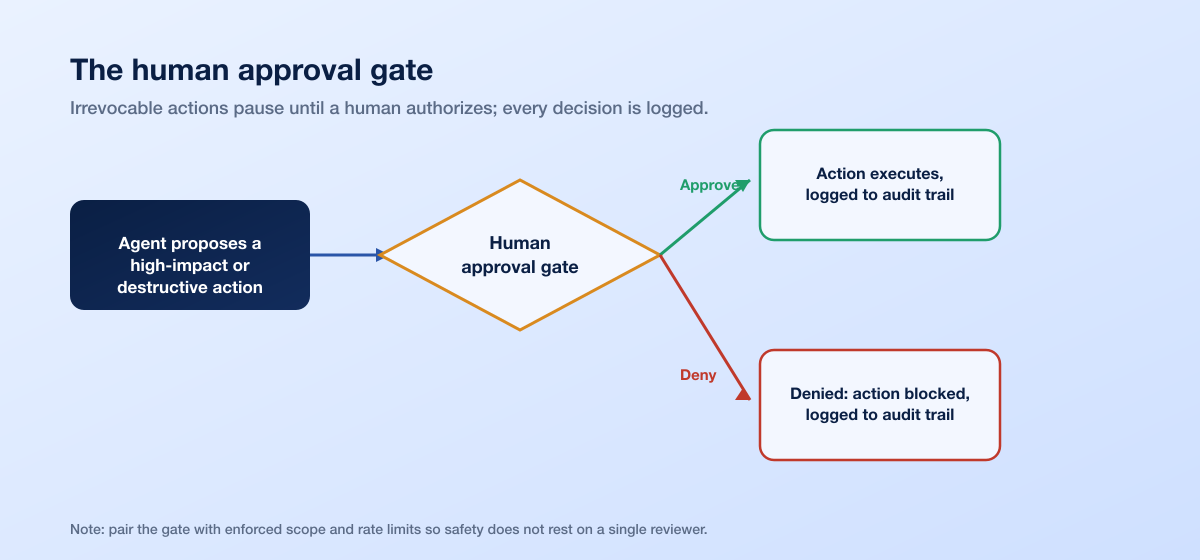
One caution worth naming: human-in-the-loop is a real control, not a rubber stamp. Automation bias is well documented. When an agent behaves correctly most of the time, reviewers start approving reflexively and miss the one action that matters. Design the checkpoint so high-impact approvals stand out from routine noise, and keep the approver's fatigue in mind when you set what requires sign-off.
6. Full audit trail
If you cannot reconstruct exactly what the agent did, you cannot trust the result and you cannot defend it in an audit. Demand tamper-evident, immutable logs that record who, what, when, why, and the scope for every action the agent took. A complete trail turns a scary black box into a reviewable engagement: you can replay the run, confirm nothing left scope, and hand the evidence to your compliance program.
7. Rollback and recovery
Even with non-destructive defaults, plan for the write that slips through. Agree on snapshot or rollback procedures scoped to the test window before the run starts, so a mutation to live data can be reversed. Rollback is the safety net beneath the other six controls, and the one buyers most often forget to ask about.
Match the controls to the autonomy level
Not every engagement needs every control dialed to maximum. The right rule is that containment scales with autonomy. The more freedom the agent has to act without asking, the stronger the runtime enforcement and the tighter the human checkpoints need to be.

Autonomy level | What the agent does | Minimum controls |
|---|---|---|
Advisory | Suggests findings and next steps; a human executes | Scope document, audit log of suggestions |
Supervised | Acts autonomously within bounds; human on the loop, monitoring in real time | Runtime scope, rate limits, kill switch, human approval on high-impact actions |
Autonomous | Plans and executes end to end within scope | All seven controls, non-destructive defaults, staging-first policy, rollback |
The industry language for the middle tier is human-on-the-loop: the agent acts within set parameters while a human monitors and retains the ability to intervene. That intervention capability is the kill switch. As you move from advisory to fully autonomous, the burden of proof shifts from the human operator to the platform's enforced controls, which is exactly why runtime scope and immutable logging become non-negotiable at the top tier.
What this means for defenders
If you own the systems an autonomous pentest will touch, here is how to turn this into procurement and operational decisions.
Make the control checklist a contract clause, not a hope. Put the seven controls into the rules of engagement and the statement of work. A vendor who cannot enumerate how they enforce scope at runtime is telling you something.
Ask for a live kill-switch demonstration during evaluation. Do not take it on faith. Time it. If it depends on a human reading an email, it is not fast enough.
Start in staging, promote deliberately. Run the first engagement against a staging replica, review the audit trail end to end, and only then define what is safe to run against production.
Insist on an immutable audit trail you can read. You want to replay the run yourself, confirm nothing left scope, and reuse the evidence for your SOC 2, ISO 27001, and PCI DSS compliance programs.
Right-size autonomy to the environment. Advisory or supervised modes are reasonable for a first production run; reserve full autonomy for scopes where every one of the seven controls is proven.
Autonomous pentesting earns its place when it finds real, high-impact bugs faster than a purely manual engagement can, and the way it earns your trust is by proving those findings safely.
How Stingrai's Snipe operates inside enforced scope
Stingrai built its autonomous web-application pentesting agent, Snipe, to operate the way this checklist describes: inside enforced scope, with human-in-the-loop validation and a full audit trail behind every finding. Snipe is designed to hunt the complex, high-impact classes that generic AI scanners miss, IDOR, business logic flaws, and broken authorization, and it runs both black-box dynamic testing and white-box source review. Because it can generate AutoFix pull requests and run as a pull-request-gating check, a large share of its value lands in the development pipeline and in staging, where destructive classes can be exercised safely before anything is validated against a live system.
The autonomy is always contained. Senior pentesters validate and extend Snipe's high-severity findings rather than trusting the agent blind, which is the human-in-the-loop checkpoint applied to results as well as actions. Snipe is trained on more than 6,000 HackerOne Hacktivity disclosure reports plus custom skills distilled from Stingrai's own pentesters' methodology, so its hypotheses reflect how senior testers actually find these bugs. If you are weighing an autonomous engagement against production, that combination, complex-vuln reach with contained, human-validated execution, is the profile to look for, whichever vendor you choose. You can compare tiers on the Stingrai pricing page.
Frequently Asked Questions
Is it safe to run an autonomous penetration test against production?
It can be safe, but only when the agent operates inside enforced runtime scope with an immediate stop control, rate and impact limits, human sign-off on destructive actions, a complete audit trail, and a rollback path. Without those controls, an autonomous agent can mutate data, target out-of-scope systems, or generate denial-of-service-like load. Multiple sources, including work aligned with the NIST AI Risk Management Framework, stress that safety comes from bounded, enforced controls rather than from the agent itself (Cloud Security Alliance, Agentic NIST AI RMF Profile, 2026).
What is the biggest risk of an autonomous pentest against production?
The biggest risk is autonomy without containment, specifically an agent taking an irrevocable action outside its authorized scope. That covers destructive operations, unintended data mutation, and lateral spread into systems that were never in scope. OWASP's 2026 agentic work names the drifted or compromised version of this as a Rogue Agent (OWASP Gen AI Security Project, 2026).
What controls should an autonomous pentest agent have before touching production?
Seven controls: enforced runtime scope, an immediate stop or kill switch, rate and impact limits, a staging-versus-production policy, human-in-the-loop checkpoints for destructive actions, a full immutable audit trail, and rollback or recovery procedures. Demand a live demonstration of each rather than accepting assurances.
What is a blast-radius control?
A blast-radius control limits how far the impact of an action can spread if something goes wrong. In autonomous pentesting, that means runtime scope enforcement, rate and concurrency caps, non-destructive defaults, and a kill switch, together bounding both what the agent can reach and how much load it can generate.
Can an autonomous pentest cause a denial-of-service outage?
Yes, if it is uncontained. A self-directing agent can generate request volume or resource-intensive payloads that read as a denial-of-service event to your infrastructure, even during benign enumeration. Rate limits, concurrency caps, and a blast-radius ceiling on total volume prevent this, which is why they belong in the rules of engagement.
Should autonomous pentesting run in staging or production first?
Staging first. Exercise destructive and state-changing classes against a staging replica, review the full audit trail, and promote only validated, non-destructive checks to production. When a finding needs production confirmation, do it as a controlled, minimal, non-destructive validation rather than a full exploit.
Is human-in-the-loop enough to make autonomous pentesting safe?
It is necessary but not sufficient on its own. Human approval on destructive actions keeps irrevocable steps under human authority, but automation bias means reviewers can approve reflexively when an agent is usually correct. Pair human checkpoints with enforced runtime scope, rate limits, and immutable logging so safety does not rest on a single tired reviewer.
How does Stingrai keep autonomous testing contained?
Stingrai's Snipe operates inside enforced scope with human-in-the-loop validation and a full audit trail behind every finding. Senior pentesters validate its high-severity results, and much of its work runs in the development pipeline and staging through AutoFix pull requests and pull-request gating, so destructive classes are exercised safely before anything is validated against a live system. See the Stingrai PTaaS page for how the tiers work.
References
OWASP Gen AI Security Project. OWASP Top 10 for Agentic Applications 2026. December 2025. https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/. Peer-reviewed framework naming the top agentic risk categories, including Rogue Agents, Identity and Privilege Abuse, and Tool Misuse.
Cloud Security Alliance. Agentic NIST AI RMF Profile v1. 2026. https://labs.cloudsecurityalliance.org/agentic/agentic-nist-ai-rmf-profile-v1/. Maps NIST AI Risk Management Framework practices to autonomous agents, emphasizing bounded scope and real-time permission management.
Synack. The Role of Agentic AI in Penetration Testing. https://www.synack.com/knowledge-base/the-role-of-agentic-ai-in-penetration-testing/. Enumerates production-safety controls for agentic pentesting: runtime allowlist and denylist, kill switch and rollback, immutable audit logs, and human approval for destructive actions.


