Your retrieval-augmented generation (RAG) knowledge base is not trusted infrastructure. It is an internet-adjacent asset that supports read, write, and delete operations over your embeddings, and in a large share of real deployments those operations are not properly authorized. RAG security testing starts by treating the vector store as an attack surface, not a database you can assume is safe behind the model.
What is RAG poisoning, how few documents does it take, and how do you test a RAG pipeline?
RAG poisoning is the act of inserting attacker-controlled content into the knowledge base that a retrieval-augmented assistant searches, so that the model retrieves the malicious text and repeats the attacker's chosen answer. It takes very few documents. In the PoisonedRAG study, injecting five malicious texts per target question achieved a 90 percent attack success rate against a knowledge database containing millions of texts (Zou et al., PoisonedRAG, 2024). Follow-up work went further: the CorruptRAG attack shows that injecting a single poisoned text per query can steer the answer, with higher success than earlier multi-document baselines (Zhang et al., Practical Poisoning Attacks against RAG, 2025).
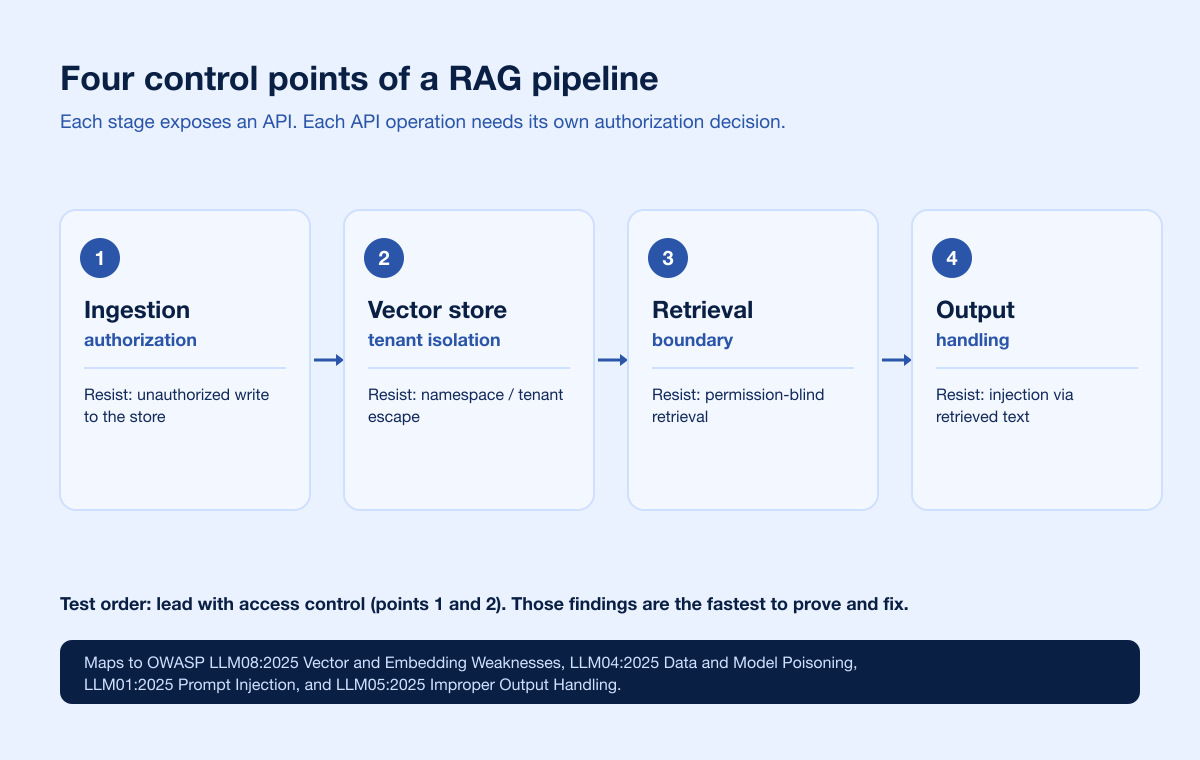
You test a RAG pipeline by probing its four control points as an attacker would: whether the ingestion path authorizes who can add or modify documents, whether the vector store isolates one tenant or namespace from another, whether retrieval respects the querying user's permissions, and whether the model's output is handled safely downstream. The access-control failures are the ones you can find, prove, and fix fastest, so lead your testing there. Poisoning is why it matters.
Why the vector store, not the model, is the real attack surface
Teams building enterprise assistants and internal copilots spend most of their security attention on the model: the system prompt, jailbreak resistance, guardrails on the output. That is the wrong first place to look. The model is stateless between calls. The knowledge base is where durable, attacker-controlled state lives, and it is the component most likely to ship with weak or missing authorization.
A typical RAG stack has an ingestion pipeline (documents, connectors, and webhooks that chunk and embed content), a vector store (the database holding embeddings and metadata, often multi-tenant), a retriever (which turns a user query into an embedding and pulls the nearest neighbors), and the model (which reads the retrieved chunks as context). Each of those has an API. Each API has operations. And operations over embeddings are exactly the read, write, and delete primitives an attacker wants.
The OWASP Top 10 for LLM Applications 2025 names this directly. LLM08:2025 Vector and Embedding Weaknesses calls out unauthorized access and data leakage from inadequate access controls, cross-context information leaks in multi-tenant vector databases, embedding inversion, and data poisoning of the knowledge base (OWASP GenAI Security Project, 2025). Separately, LLM04:2025 Data and Model Poisoning notes that embedding data can be poisoned to manipulate model behavior (OWASP Top 10 for LLM Applications 2025). The standard already agrees: the vector layer is a first-class attack surface.
The most convertible failure: access control over embeddings
Access control is the failure you should test first, because it is the most common, the easiest to prove, and the fastest to remediate. Three patterns dominate.
1. Unauthenticated or under-authorized ingestion endpoints
Many RAG systems expose an ingestion path so that internal tools, connectors, or webhooks can push new documents into the knowledge base. That path is frequently protected by nothing stronger than a shared static token, an internal-network assumption, or no check at all. If an attacker can reach the ingestion endpoint and write, they can plant poisoned documents directly, skipping every content-source control you built upstream.
This is a missing-authorization weakness (CWE-862) at the API layer. The question to answer during testing is simple: from an unauthenticated or low-privilege position, can I add, overwrite, or delete a document or an embedding in the store? If the answer is yes, the poisoning research below tells you how little content it takes to change what the assistant says.
2. Tenant and namespace escape in a shared vector store
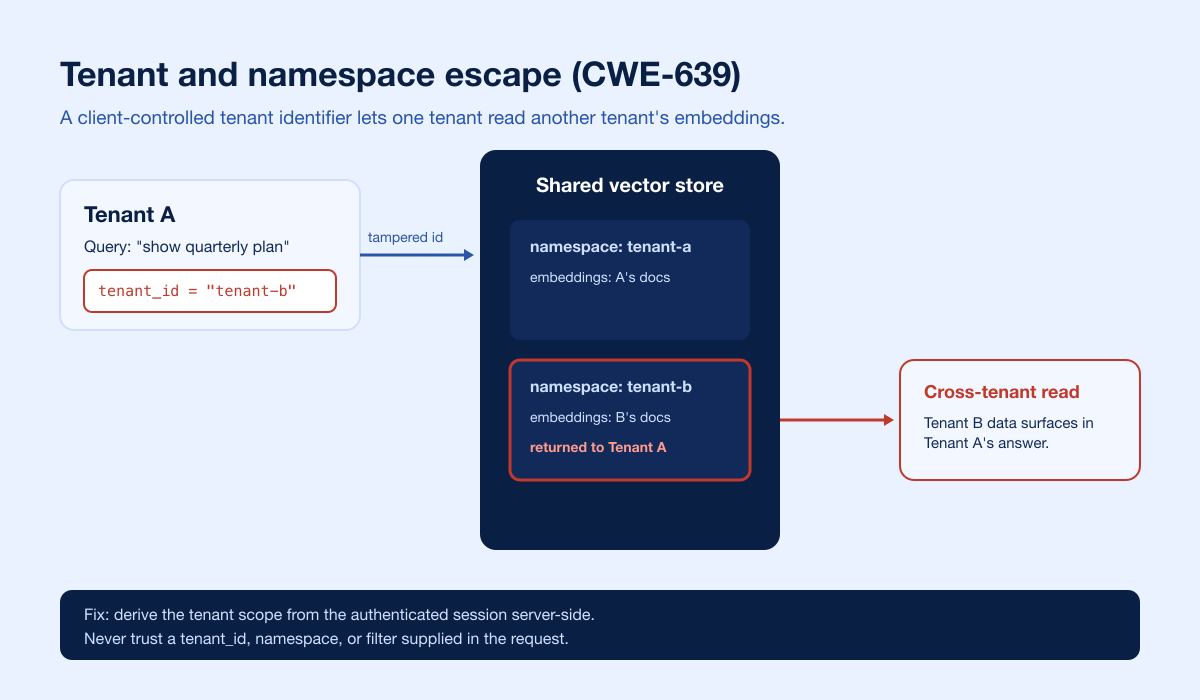
Most managed vector stores are multi-tenant by design. Isolation between customers, teams, or users is usually enforced by a namespace, collection, index name, or a metadata filter such as tenant_id that the application attaches to each query. When that identifier is client-controlled, guessable, or trusted without a server-side authorization check, you have a classic authorization-bypass-through-user-controlled-key pattern (CWE-639, the vector-store equivalent of IDOR).
The impact is direct cross-tenant read. OWASP LLM08:2025 describes exactly this: in multi-tenant environments sharing a vector database, embeddings from one group can be retrieved for another group's queries, exposing data across user classes (OWASP GenAI Security Project, 2025). If tenant B's confidential documents surface in tenant A's answer, that is a data breach delivered through the model's mouth.
3. Unrestricted query and management operations
Beyond ingestion and isolation, the vector store's own API surface matters. Can an authenticated user list collections that are not theirs? Query across namespaces? Read raw metadata that contains source URLs, file paths, or PII? Call management operations to snapshot, export, or delete an index? Embedding inversion research shows that embeddings themselves can leak significant source information, so even read-only access to the wrong vectors is a confidentiality problem, not just a nuisance. Treat every vector-store operation as something that needs an authorization decision keyed to the requesting principal, not to a value the client supplied.
These three patterns map onto broken access control (CWE-284) and broken authorization, which is precisely the class of complex, high-impact bug that generic scanners miss because it requires understanding the application's own logic. It is also the class where a purpose-built agentic tester earns its keep.
The motivation: how little it takes to poison a knowledge base
Access control is the door. Poisoning is what walks through it. The reason unauthorized write access to a vector store is severe, rather than merely untidy, is that the amount of malicious content required to change model behavior is tiny.
Five documents, 90 percent success. PoisonedRAG demonstrated that injecting five crafted texts for a target question reached a 90 percent attack success rate against a knowledge database of millions of texts (Zou et al., 2024). The poisoned entries only have to rank highly for the target query, not dominate the whole corpus.
One document can be enough. CorruptRAG showed that a single poisoned text per query can steer the assistant's answer, with higher success than earlier multi-document methods, specifically because a one-document footprint is more feasible and more stealthy (Zhang et al., 2025).

Treat those numbers as threat-model motivation, not a recipe. The defender takeaway is that your dilution assumptions are wrong. You cannot rely on a large, mostly-clean corpus to drown out a handful of malicious chunks, because retrieval selects the nearest neighbors to the query, and an attacker who controls even one well-embedded document can win that neighborhood. That is why the write path into your knowledge base deserves the same authorization rigor as any money-moving endpoint.
A defender-framed test methodology for the RAG pipeline
Here is a practical way to security test a RAG pipeline. Work through the four control points in order. Everything below is a test to run against your own system with permission, using synthetic marker documents, never a live exploitation playbook against someone else's assistant.

Control point 1: ingestion authorization
The goal is to prove that only authorized principals can add, modify, or delete knowledge-base content.
Enumerate every write path into the store: upload UI, API endpoints, connector callbacks, webhooks, scheduled sync jobs, and any admin tooling.
From an unauthenticated session, attempt to ingest a uniquely tagged synthetic document (for example, a benign string that no legitimate content would contain). If it lands and later shows up in a retrieval, ingestion authorization is broken.
Repeat from a low-privilege authenticated session that should not have write access. Verify that role and scope are enforced server-side, not just hidden in the UI.
Test overwrite and delete, not only create. Can a user replace an existing high-authority document or remove one? Silent deletion of trusted content is its own denial-of-integrity attack.
Confirm ingestion validates and records provenance: source, uploader identity, and timestamp. OWASP LLM08 recommends accepting data only from trusted, verified sources and keeping immutable retrieval logs.
Control point 2: vector store tenant and namespace isolation
The goal is to prove that no query can reach embeddings outside the requesting principal's authorized scope.
Stand up at least two test tenants, each with a distinct synthetic marker document that the other tenant must never see.
As tenant A, tamper with any client-visible scoping value: namespace, collection name, index,
tenant_id, or metadata filter. Try adjacent, guessed, and enumerated values.Query for tenant B's marker. If it returns, you have a cross-tenant read (CWE-639). This is the single highest-value finding in most RAG assessments.
Check that filtering is applied server-side. A filter added by client code, or a
tenant_idtaken from a request body rather than the authenticated session, is not isolation.Test the management plane too: listing collections, describing indexes, and exporting or snapshotting data across tenant boundaries.
Control point 3: the retrieval boundary
The goal is to prove that retrieval honors the querying user's document-level permissions, not just tenant boundaries.
Model a within-tenant permission split: a document that user X may read and user Y may not.
As user Y, ask questions engineered to retrieve X's restricted document. If restricted content appears in Y's answer, retrieval is permission-blind. Permission-aware retrieval means the filter reflects the user's entitlements at query time, which is exactly what OWASP LLM08 recommends with permission-aware vector and embedding stores.
Probe whether retrieved metadata leaks more than the chunk text: source paths, internal URLs, author names, or classification labels that should not surface.
Control point 4: output handling
The goal is to prove that whatever the model returns is treated as untrusted, because retrieved content can carry indirect prompt-injection payloads.
Seed a synthetic document in your own test corpus containing benign instruction-like text and confirm the application does not act on it as a command. This tests the pipeline's resistance to indirect prompt injection via retrieved context, aligned to LLM01:2025 Prompt Injection.
Verify the model's output is validated, sanitized, and encoded before it reaches a browser, a shell, a downstream API, or another tool. Unsanitized output is LLM05:2025 Improper Output Handling and turns a retrieval issue into XSS, SSRF, or command execution.
Confirm sensitive content that should never be verbalized is filtered on the way out, mapping to LLM02:2025 Sensitive Information Disclosure.
Any check that cannot be completed against a named, in-scope endpoint should be reported as untested, not assumed safe. Isolation you did not verify is isolation you do not have.
Where this maps to Stingrai's work
Broken authorization, IDOR, and business-logic flaws are the hardest classes to find with signature scanners, because they require reasoning about the application's own rules rather than matching a known pattern. That is the core of RAG access-control testing: a tenant_id you can tamper with, an ingestion endpoint that forgot to check the caller, a retrieval filter that trusts the client. It is also exactly what Stingrai's autonomous agent, Snipe, was built to hunt.
Snipe is Stingrai's autonomous agent for web application penetration testing. It performs both black-box dynamic testing and white-box source review, and it is purpose-built to reach complex, high-impact classes such as IDOR, broken authorization, and business-logic flaws rather than stopping at known-class bugs. It is trained on thousands of real HackerOne disclosure reports and on skills distilled from Stingrai's human pentesters, so it encodes how senior testers actually chase these bugs. When it finds one, it can generate an AutoFix pull request and run as a PR-gating check to keep the vulnerable code from merging. For teams shipping RAG assistants, that maps directly onto the vector-store access-control surface described above. You can see how it fits into continuous coverage on the PTaaS page, or review the full services lineup for red-team and application testing engagements.
Defensive checklist for RAG teams
Pair the tests above with these controls:
Authorize every vector-store operation against the authenticated principal, not a client-supplied identifier. Ingestion, query, list, export, and delete all need a server-side decision.
Enforce tenant isolation server-side with permission-aware retrieval and strict logical partitioning, per OWASP LLM08. Never trust a
tenant_idfrom the request body.Validate and attribute ingested content. Accept documents only from trusted, verified sources; record uploader identity, source, and timestamp; keep immutable retrieval and ingestion logs.
Classify knowledge-base content so that sensitive material carries access labels the retriever can enforce.
Treat model output as untrusted. Validate, sanitize, and encode before it reaches any downstream sink.
Monitor for anomalous ingestion and retrieval, such as sudden bursts of new documents or queries that repeatedly surface a single low-reputation source.
Test continuously, not once. Every schema change, new connector, or tenant onboarding is a fresh chance to reopen an isolation gap.
Frequently Asked Questions
What is RAG poisoning and how few documents does it take?
RAG poisoning is the insertion of attacker-controlled content into the knowledge base a retrieval-augmented assistant searches, so the model retrieves the malicious text and repeats the attacker's chosen answer. It takes very little. PoisonedRAG achieved a 90 percent attack success rate with five poisoned texts per target question against a database of millions of texts (Zou et al., 2024), and CorruptRAG showed a single poisoned text per query can be enough (Zhang et al., 2025).
How do I security test a RAG pipeline?
Test the four control points in order: ingestion authorization (can an unauthorized principal write to the store), vector store tenant isolation (can a query cross namespace or tenant boundaries), the retrieval boundary (does retrieval honor per-user document permissions), and output handling (is model output treated as untrusted). Use synthetic marker documents and confirm each control server-side. Lead with access control, since those findings are the easiest to prove and fix.
Why is the vector store the real attack surface, not the model?
The model is stateless between calls; the vector store holds durable, attacker-controllable state and exposes read, write, and delete operations that often lack real authorization. OWASP LLM08:2025 Vector and Embedding Weaknesses identifies unauthorized access, cross-context leaks, embedding inversion, and data poisoning at exactly this layer (OWASP GenAI Security Project, 2025).
What is a tenant or namespace escape in a vector database?
It is a cross-tenant read that happens when the value used to isolate customers or teams (a namespace, collection, index, or tenant_id filter) is client-controlled or trusted without a server-side authorization check. Tampering with it lets one tenant retrieve another tenant's embeddings, an authorization-bypass-through-user-controlled-key pattern (CWE-639), the vector-store equivalent of IDOR.
Is RAG poisoning the same as prompt injection?
No. Prompt injection manipulates the model through instructions in the prompt or in retrieved context (LLM01:2025). RAG poisoning manipulates the knowledge base itself so that the retriever pulls attacker content (related to LLM04:2025 Data and Model Poisoning and LLM08:2025). They combine: a poisoned document can carry an indirect prompt-injection payload, which is why output handling is a distinct control point.
What does OWASP say about vector and embedding security?
OWASP LLM08:2025 Vector and Embedding Weaknesses recommends permission-aware vector and embedding stores with fine-grained access control and strict logical partitioning, data validation with acceptance only from trusted sources, data classification, and detailed immutable retrieval logs (OWASP GenAI Security Project, 2025).
How do I know if my ingestion endpoint is under-authorized?
Attempt to ingest a uniquely tagged synthetic document from an unauthenticated and then a low-privilege session, and check whether it lands and later appears in a retrieval. Also test overwrite and delete, not just create. A write path protected only by a shared static token, network assumption, or client-side check is a missing-authorization weakness (CWE-862).
Can this kind of RAG testing be automated?
Access-control and authorization testing over a RAG pipeline benefits from an agent that reasons about the application's own rules, because these are logic flaws rather than signature matches. Stingrai's Snipe agent is built to hunt IDOR, broken authorization, and business-logic classes across black-box and white-box testing, and it can open AutoFix pull requests and gate merges. See the web application penetration testing service or the pricing page for how engagements are structured.
References
Zou, W., Geng, R., Wang, B., Jia, J. PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. 2024. https://arxiv.org/abs/2402.07867. Demonstrates a 90 percent attack success rate injecting five poisoned texts per target question into a knowledge database of millions of texts.
Zhang, B., Chen, Y., Liu, Z., Nie, L., Li, T., Liu, Z., Fang, M. Practical Poisoning Attacks against Retrieval-Augmented Generation. 2025. https://arxiv.org/abs/2504.03957. Shows a single poisoned text per query can steer RAG output with higher success than prior multi-document baselines.
OWASP GenAI Security Project. OWASP Top 10 for LLM Applications 2025: LLM08:2025 Vector and Embedding Weaknesses. 2025. https://genai.owasp.org/llmrisk/llm082025-vector-and-embedding-weaknesses/. Defines unauthorized access, cross-context leaks, embedding inversion, and poisoning risks, plus permission-aware store and logging mitigations.
OWASP GenAI Security Project. OWASP Top 10 for LLM Applications 2025. 2025. https://genai.owasp.org/llm-top-10/. Source for LLM01 Prompt Injection, LLM02 Sensitive Information Disclosure, LLM04 Data and Model Poisoning, and LLM05 Improper Output Handling.
MITRE. CWE-639: Authorization Bypass Through User-Controlled Key. https://cwe.mitre.org/data/definitions/639.html. Weakness class mapped to tenant and namespace tampering in vector stores.
MITRE. CWE-862: Missing Authorization. https://cwe.mitre.org/data/definitions/862.html. Weakness class mapped to unauthorized ingestion and query endpoints.
MITRE. CWE-284: Improper Access Control. https://cwe.mitre.org/data/definitions/284.html. Umbrella access-control weakness for vector-store operations.