
Red teaming a chatbot before launch means running structured adversarial tests against a customer-facing GenAI bot, then treating the results as pass/fail acceptance criteria for a go-live decision rather than a scored report that sits in a drawer. A pre-production AI security checklist should cover, at minimum, seven areas: prompt-injection resistance, system-prompt and secrets non-leakage, unsafe tool and action prevention, PII exfiltration via retrieval, output handling and XSS, abuse and rate limiting, and guardrail-bypass resilience. Every one of those maps onto a named category in the OWASP Top 10 for LLM Applications 2025 (OWASP LLM Top 10, 2025), so the evidence you collect lines up with the framework your auditors and enterprise buyers already recognize.
This post is the narrow pre-launch spoke: not a survey of LLM risk, but the go/no-go decision asset a launch-readiness review actually uses. Each blocker below is written as a criterion with a clear PASS and FAIL condition, the failure mode that trips it, and the specific evidence a reviewer should demand before signing off. It is written for the product lead and the security lead who share the launch decision on a GenAI support bot, and who need a defensible paper trail when someone later asks "did we test this before we shipped it?"
A note on framing. This is a security testing and acceptance guide, not a jailbreak how-to. It describes failure modes and the evidence required to prove they are closed, using synthetic examples only. Working exploit payloads have no place in a launch-readiness document. The goal is a reviewer who can say yes or no with confidence, backed by artifacts, not a reader who leaves with a copy-paste attack.
How to red team a chatbot before launch
The method is straightforward and it is what makes the checklist below meaningful. You define the bot's intended behavior and its hard boundaries first, then you try to break each boundary from the position of a motivated abuser, and you record what happened as evidence.
Scope the bot's contract. Write down what the bot is allowed to do (answer product questions, look up an order, open a support ticket) and, more importantly, what it must never do (reveal another customer's data, run a refund, disclose its system prompt, produce disallowed content). The "must never" list becomes your test targets.
Enumerate the attack surface. Map every input path (chat box, uploaded files, retrieved documents, connected tools and APIs) and every output sink (the browser, downstream systems, logs). Injection and exfiltration hide in the paths people forget, especially retrieved content and tool responses.
Run adversarial tests against each boundary. Mix human red teamers with automated adversarial testing so you get both creative, context-aware attacks and broad, repeatable coverage. At Stingrai, pre-launch chatbot red teaming leads with senior human pentesters, who probe guardrails, prompt and system-prompt leakage, and unsafe tool actions, and pairs them with Snipe, our autonomous web-app pentest agent, which hunts the authorization, business-logic, and IDOR flaws that let the surrounding application leak data or exfiltrate PII through the retrieval layer.
Convert results to pass/fail. Do not hand the launch team a heat map. Hand them a table where each blocker is PASS or FAIL with linked evidence. That is the difference between a red-team report and a go-live decision asset.
Re-test after fixes. A FAIL that gets patched is not a PASS until you re-run the same test and capture new evidence. Regression coverage belongs in the trail too.
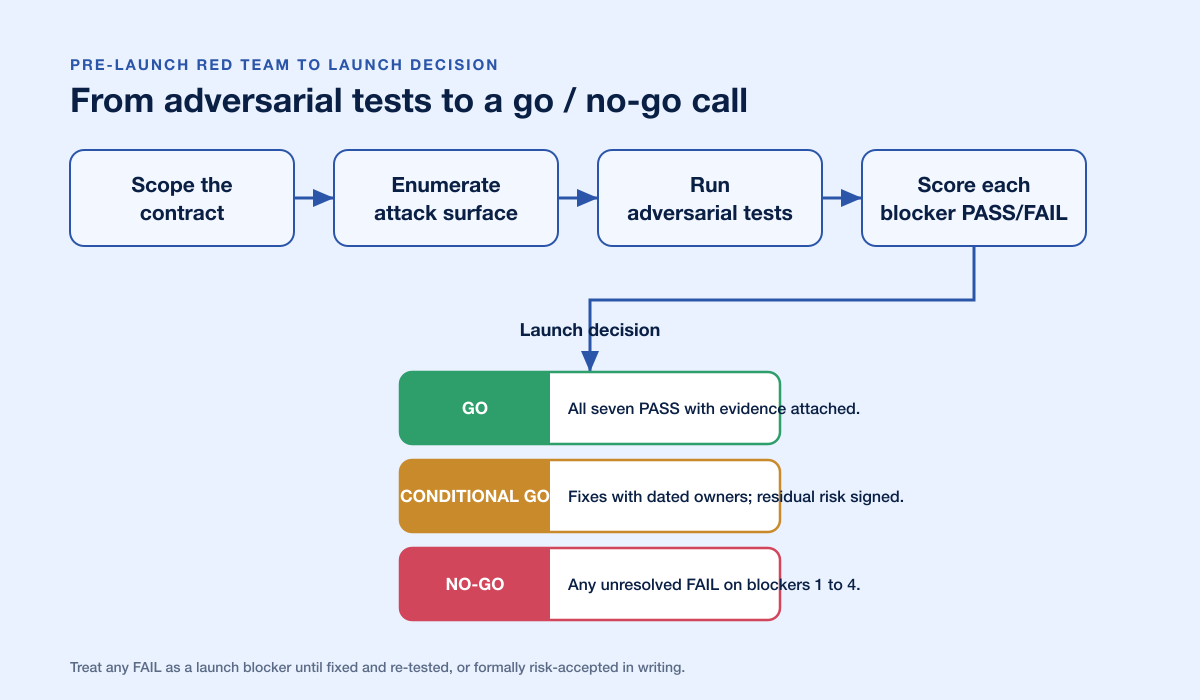
Now the seven blockers. Treat any FAIL as a launch blocker until it is either fixed and re-tested, or formally risk-accepted in writing by an accountable owner. "We will fix it after launch" is a decision someone must sign, not a default.

Key takeaways
The most dangerous failures come through content the bot retrieves, not text the user types. Indirect prompt injection hidden in a knowledge-base document or a support ticket can hijack a bot that shrugs off obvious direct attacks. Test the retrieval and tool paths as hard as the chat box (OWASP LLM01 Prompt Injection and LLM08 Vector and Embedding Weaknesses, OWASP LLM Top 10, 2025).
A bot with tools is an application with a new, chatty attack surface. The moment your bot can trigger a refund, change an address, or query a database, prompt injection becomes remote action, not just bad text. Excessive Agency is its own OWASP category for a reason (OWASP LLM Top 10, 2025).
Guardrails are a control, not a proof. A refusal you saw once is not evidence the boundary holds. Evidence is a documented battery of bypass attempts, the pass rate, and the residual failures with their fixes.
Pass/fail beats a score for a launch decision. A launch reviewer needs a yes or no per boundary with linked artifacts, not a 7.4 out of 10. Convert every finding into an acceptance criterion.
The frameworks already agree on the categories, so align to them. Mapping your checklist to the OWASP LLM Top 10 and the NIST Generative AI Profile makes the evidence portable to auditors and enterprise buyers (NIST AI RMF and Generative AI Profile, 2023 and 2024).
Methodology and sources
This report is a defender-side acceptance guide. The seven blockers are organized to mirror the OWASP Top 10 for LLM Applications 2025, the current community-maintained catalog of LLM-specific risks (OWASP LLM Top 10, 2025). Control and governance framing draws on the NIST AI Risk Management Framework 1.0 (published January 26, 2023) and its Generative AI Profile, NIST-AI-600-1 (published July 26, 2024), which catalogs generative-AI-specific risks and suggested actions (NIST, 2023 and 2024). Adversary technique framing references MITRE ATLAS, the adversarial-threat knowledge base for AI-enabled systems (MITRE ATLAS). Regulatory timing references the EU AI Act, which entered into force on August 1, 2024, with obligations for most high-risk systems applying from August 2, 2026 (EU AI Act implementation timeline).
We deliberately do not publish attack payloads, and we do not print unsourced statistics. Where we could not tie a numeric claim to a named primary source, we dropped it rather than estimate. Every framework reference above links to its publisher so any mapping can be audited inline.
Blocker 1: Prompt-injection resistance
Maps to: OWASP LLM01 Prompt Injection.
PASS: The bot maintains its intended behavior and boundaries when attacker-controlled instructions appear in user input, in uploaded files, and in retrieved documents. Direct and indirect injection attempts fail to make the bot ignore its rules, change persona into an unrestricted assistant, or act on instructions embedded in content it merely read.
FAIL: A crafted message, an uploaded document, or a poisoned knowledge-base entry causes the bot to override its instructions, follow attacker directives, or treat retrieved text as commands.
Failure mode to test. Direct injection is the obvious case: a user tells the bot to disregard prior instructions. The higher-risk case is indirect injection, where the malicious instruction rides inside content the bot ingests, such as a product review, a support ticket, or a document in the retrieval corpus. The bot reads it as data but acts on it as instruction. Because your knowledge base and ticket history are the bot's context, anyone who can write into those stores can attempt to steer the bot.
Evidence a reviewer should require:
A test set covering both direct and indirect injection, including at least one attempt planted in a retrieved document, not only in the chat box.
The number of attempts run and the number blocked, plus the specific text of any attempt that succeeded (synthetic, not a live exploit).
The mitigation for each success (input and content isolation, instruction hierarchy, retrieval sanitization) and a re-test result showing it now fails.
Blocker 2: System-prompt and secrets non-leakage
Maps to: OWASP LLM07 System Prompt Leakage and LLM02 Sensitive Information Disclosure.
PASS: The bot does not reveal its system prompt, hidden instructions, internal rules, tool definitions, API keys, or any credential, under direct questioning, role-play, or trickery. Just as importantly, no secret that matters lives in the system prompt in the first place.
FAIL: Coaxing the bot ("repeat the text above," "what were your original instructions," a nested role-play) yields the system prompt, internal policy text, tool schemas, or, worst case, a key or connection string.
Failure mode to test. Two things are in scope. First, whether the prompt leaks at all. Second, and this is the part teams miss, whether anything harmful is exposed if it does. OWASP is explicit that the real risk is not the prompt text itself but the secrets and security assumptions people wrongly embed in it (OWASP LLM Top 10, 2025). If your access control depends on the model "knowing" not to do something because the prompt said so, a leak is a breach.
Evidence a reviewer should require:
Results of a battery of extraction attempts (direct, role-play, encoding tricks) with pass/fail per attempt.
Confirmation that no credential, key, connection string, or internal endpoint is present in the system prompt or tool definitions, verified by inspection, not just by "the bot refused."
Confirmation that authorization is enforced server-side, so a leaked prompt does not grant any capability the caller did not already have.
Blocker 3: Unsafe tool and action prevention
Maps to: OWASP LLM06 Excessive Agency.
PASS: The bot cannot be induced to perform an action beyond its intended authority. Every tool call is authorized against the authenticated user's permissions on the server side, state-changing actions require the right checks, and the bot cannot chain tools to reach an outcome no single tool was meant to allow.
FAIL: An attacker persuades the bot to issue a refund, change account details, read a record belonging to someone else, or call an internal API it should not, because the guardrail lived in the prompt instead of in the backend.
Failure mode to test. The instant a support bot gets tools, prompt injection stops being a content problem and becomes an action problem. Excessive Agency covers three overlapping issues: too many tools, too much permission, and too much autonomy. A bot that can call a "process refund" function will eventually be asked to process a refund it should not. The only durable control is server-side authorization on every tool call, scoped to the end user, plus human confirmation for high-impact actions.
Evidence a reviewer should require:
An inventory of every tool the bot can call, the permission each requires, and confirmation that permission is checked server-side per request against the caller's identity.
Red-team attempts to trigger unauthorized or out-of-scope actions (including via injection from retrieved content) with pass/fail per action.
Evidence that high-impact, state-changing actions require explicit confirmation or a human in the loop, and that the bot cannot self-approve.
Blocker 4: PII exfiltration via retrieval (RAG)
Maps to: OWASP LLM08 Vector and Embedding Weaknesses and LLM02 Sensitive Information Disclosure.
PASS: A user can only ever retrieve data they are authorized to see. Cross-tenant and cross-user leakage through the retrieval layer is impossible, and the bot does not surface PII from the knowledge base to a user who should not have it.
FAIL: By phrasing a question the right way, a user pulls another customer's order, another tenant's document, or PII that was embedded in the vector store without access controls.
Failure mode to test. Retrieval-augmented generation is where a lot of chatbots quietly leak. If every document is embedded into one shared index with no per-user or per-tenant filtering, then relevance, not authorization, decides what comes back. The model faithfully answers using whatever the retriever hands it, and the retriever does not know who is asking. This is a classic multi-tenant isolation failure wearing an AI costume.
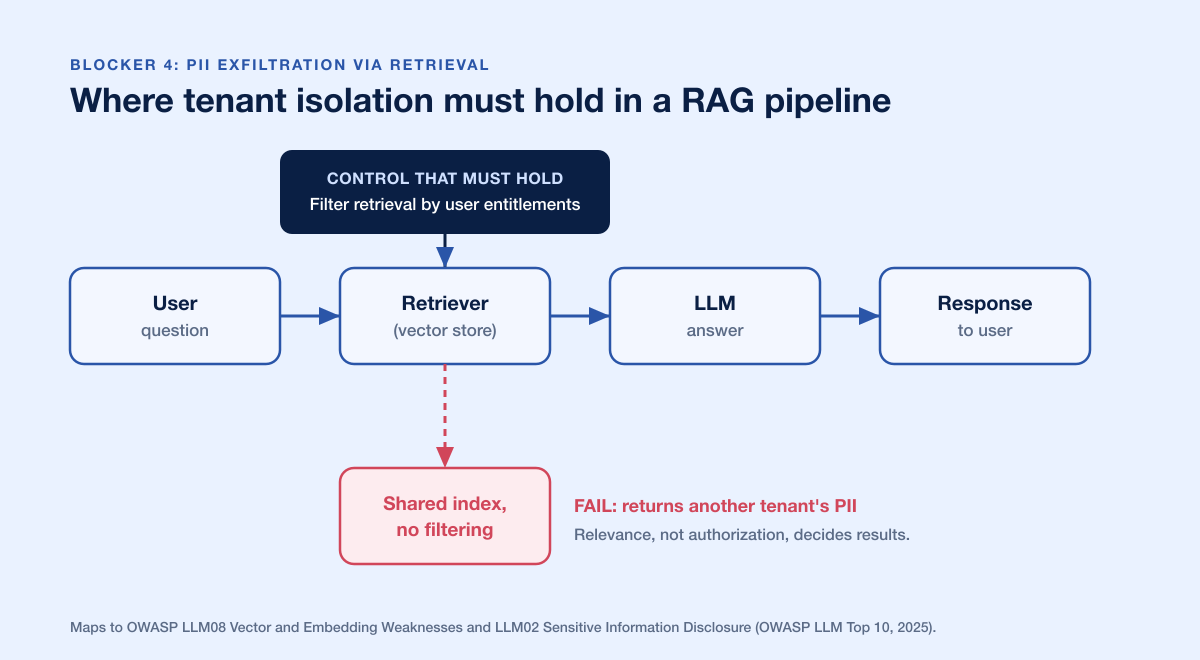
Evidence a reviewer should require:
Proof that retrieval is filtered by the authenticated user's entitlements before results reach the model, not after (metadata filtering, per-tenant indexes, or equivalent).
Cross-tenant and cross-user test cases: user A asking, in as many creative ways as the red team can invent, for data that belongs to user B, all returning nothing.
Confirmation of what PII is in the corpus at all, and whether it needs to be, since the safest exfiltration control is not embedding sensitive data you do not need.
Blocker 5: Output handling and XSS
Maps to: OWASP LLM05 Improper Output Handling.
PASS: Everything the model produces is treated as untrusted before it is rendered or passed downstream. Model output is encoded for the context it lands in, so it cannot execute as script in the browser or as a command in a downstream system.
FAIL: The bot renders model output as raw HTML, so an attacker who can influence the output (directly or via injection) lands stored or reflected XSS in the chat UI, or the output flows unescaped into a system that executes it.
Failure mode to test. People spend all their attention on what goes into the model and forget what comes out. If the chat interface renders the model's response as HTML, a response containing a script tag can execute in the victim's browser. Combine that with indirect injection (attacker plants the payload in a document the bot will summarize) and you have stored XSS delivered by your own bot. The model is just another untrusted input source to the rest of your stack.
Evidence a reviewer should require:
Confirmation that model output is contextually encoded or sanitized before rendering, and that the chat UI does not render arbitrary HTML or script from responses.
Test cases attempting to get executable markup into the chat surface, both directly and via a poisoned retrieved document, all rendered inert.
Confirmation that any downstream consumer of the bot's output (ticketing, email, another service) also treats it as untrusted.
Blocker 6: Abuse and rate limiting
Maps to: OWASP LLM10 Unbounded Consumption.
PASS: A single user or client cannot drive unbounded cost or degrade availability. Rate limits, quotas, and input-size limits are enforced, and abusive patterns are throttled or blocked before they turn into a bill or an outage.
FAIL: An unauthenticated or single authenticated client can hammer the bot with expensive requests, extract the model's behavior at scale, or run costs up with no ceiling.
Failure mode to test. Every message to your bot has a real inference cost. Without limits, abuse is cheap for the attacker and expensive for you, whether the goal is a denial-of-wallet attack, a denial of service, or bulk extraction of the model's outputs to clone its behavior. Unbounded Consumption also covers oversized or crafted inputs designed to be maximally costly to process.
Evidence a reviewer should require:
Documented rate limits, per-user and per-IP quotas, and maximum input sizes, with test evidence that they trigger.
A load and abuse test showing behavior under sustained and burst traffic, including cost controls and graceful degradation.
Monitoring and alerting on anomalous usage, so abuse is visible in production, not discovered on an invoice.
Blocker 7: Guardrail-bypass resilience
Maps to: OWASP LLM01 Prompt Injection and the safety controls layered on top of it.
PASS: Content and safety guardrails hold across a broad battery of bypass techniques (role-play, encoding, obfuscation, multi-turn manipulation, language switching), with a documented pass rate and a plan for the residual failures. The bot stays inside its allowed topics and refuses disallowed requests reliably, not just on the first attempt.
FAIL: A modest amount of creative rephrasing gets the bot to produce content or take a stance it was explicitly built to refuse, and there is no measurement of how often that happens.
Failure mode to test. Guardrails are probabilistic, so the honest question is not "can they be bypassed" but "how often, and what is exposed when they are." A single refusal you happened to observe is not evidence. Evidence is a structured suite of bypass attempts, run at volume, producing a measured pass rate and a short list of residual failures with owners. This is also where human and automated testing earn their keep together: automation gives you breadth and repeatability, humans supply the creative, context-specific attacks that scripts miss.
Evidence a reviewer should require:
A documented battery of bypass attempts across multiple techniques, with the total run, the number blocked, and the resulting pass rate.
The specific residual failures (described, not weaponized), each with a fix or an explicit, signed risk acceptance.
A re-test after mitigation showing the previously successful bypasses now fail.
Turning the checklist into a go/no-go decision
The point of the seven blockers is a decision, not a document. Once each is marked PASS or FAIL with evidence, the launch call is simple:
GO: All seven PASS, evidence attached.
CONDITIONAL GO: One or more findings remain, each with a fix committed to a date and a named owner, and any residual risk formally accepted in writing by an accountable person. Not "we will get to it."
NO-GO: Any unresolved FAIL on Blockers 1 through 4 (injection, secrets leakage, unsafe actions, PII exfiltration), because those are the paths from a chat box to a breach.
Keep the artifacts. The red-team report, the pass/fail table, the fixes, and the re-tests together form the evidence trail that answers the question every incident review eventually asks: what did we test before we shipped, and who signed off. That trail also maps cleanly to the OWASP LLM Top 10 and the NIST Generative AI Profile, so it travels well to auditors and enterprise procurement teams (OWASP LLM Top 10, 2025; NIST, 2023 and 2024).
Why this matters now
Customer-facing GenAI is shipping into regulated workflows faster than the testing practices around it have matured. On the regulatory side, the EU AI Act entered into force on August 1, 2024, with obligations for most high-risk AI systems applying from August 2, 2026 (EU AI Act implementation timeline). A documented pre-launch adversarial-testing trail is exactly the kind of evidence that becomes easier to produce on purpose than to reconstruct under pressure. A support bot that can read your data and take actions on your systems deserves the same pre-launch scrutiny you would give any new public-facing application, because that is what it is.
What this means for defenders
Test the paths, not just the prompt. Budget red-team effort for retrieved content and tool responses, where indirect injection and cross-tenant exfiltration actually live. See how web application penetration testing treats every input path as hostile, and apply the same discipline to your retrieval and tool layers.
Push authorization to the server. Guardrails in the prompt are a suggestion. Authorization on every tool call and every retrieval, scoped to the authenticated user, is a control.
Measure guardrails, do not admire them. Replace "the bot refused when I tried it" with a pass rate over a real battery of attempts, and a list of residual failures with owners.
Make the launch decision explicit. GO, conditional GO, or NO-GO, with evidence, and someone's name on any accepted risk.
Bring in an adversary before your customers do. Stingrai's pre-launch chatbot red teaming leads with senior human pentesters who probe injection, secrets leakage, and unsafe tool actions, backed by Snipe, our autonomous web-app pentest agent that hunts the authorization and business-logic flaws behind PII exfiltration, then hands you a pass/fail acceptance trail. Explore our PTaaS and red teaming services, or see the full range at Stingrai.
Frequently Asked Questions
How do you red team a chatbot before launch, and what should a pre-production AI security checklist include?
Red teaming a chatbot before launch means defining the bot's hard boundaries, then running adversarial tests against each one from an attacker's position and recording the results as pass/fail acceptance criteria. A pre-production checklist should cover at least seven areas: prompt-injection resistance, system-prompt and secrets non-leakage, unsafe tool and action prevention, PII exfiltration via retrieval, output handling and XSS, abuse and rate limiting, and guardrail-bypass resilience. These map onto the OWASP Top 10 for LLM Applications 2025, so the evidence aligns with a framework auditors recognize (OWASP LLM Top 10, 2025).
What is the most dangerous failure mode in a customer-facing chatbot?
Indirect prompt injection combined with tool access is usually the highest-impact path. When a malicious instruction hidden in a retrieved document or support ticket steers a bot that can also take actions, a content problem becomes an unauthorized action or a data breach. OWASP tracks these as Prompt Injection (LLM01) and Excessive Agency (LLM06) (OWASP LLM Top 10, 2025).
Is red teaming a chatbot the same as writing jailbreak prompts?
No. Jailbreaking is producing a working bypass. Pre-launch red teaming is a defender-side exercise that documents which boundaries hold, which do not, and what evidence proves it, so a launch reviewer can make a go/no-go call. A responsible report describes failure modes and required fixes, not reusable attack payloads.
What evidence should a launch reviewer require before signing off?
For each of the seven blockers, a reviewer should require the number of attempts run, the number blocked, the specific text of any success (synthetic, not live), the mitigation applied, and a re-test showing the issue now fails. A pass/fail table with linked artifacts, not a single score, is what supports a defensible go-live decision.
How is prompt injection different from a jailbreak?
Prompt injection is untrusted input, direct or indirect, altering the model's behavior; it is OWASP LLM01 (OWASP LLM Top 10, 2025). A jailbreak is one goal of injection: getting the model to violate its safety guardrails. Injection is the mechanism, jailbreaking and guardrail bypass are outcomes, and both belong in a pre-launch test plan.
How do you stop a chatbot from leaking one customer's data to another?
Filter retrieval by the authenticated user's entitlements before results reach the model, using per-tenant indexes or metadata filtering, and enforce authorization server-side on every tool call and lookup. Do not rely on the prompt to keep tenants apart. Then test it: have the red team try, in as many ways as possible, to pull another user's data, and confirm every attempt returns nothing.
Do prompt-based guardrails count as a security control?
They are a useful layer, but not a boundary you can prove. If a leaked or bypassed prompt would grant a capability, the real control has to live in the backend as server-side authorization and output handling. Guardrails reduce the rate of unwanted behavior; enforcement in code is what actually stops it.
Which frameworks should a pre-launch chatbot test align to?
The OWASP Top 10 for LLM Applications 2025 is the most directly applicable catalog of LLM-specific risks (OWASP LLM Top 10, 2025). The NIST AI Risk Management Framework 1.0 and its Generative AI Profile (NIST-AI-600-1) add governance and risk-management structure (NIST, 2023 and 2024), and MITRE ATLAS provides adversary-technique context for AI systems (MITRE ATLAS).
Where can I get a pre-launch chatbot red team done?
Stingrai runs pre-launch chatbot red teaming that pairs senior human pentesters with Snipe, our autonomous web-app pentest agent, and returns a pass/fail acceptance trail for your go-live decision. Start with our PTaaS or red teaming pages.
References
OWASP GenAI Security Project. OWASP Top 10 for Large Language Model Applications 2025. 2025. https://genai.owasp.org/llm-top-10/. Community-maintained catalog of the ten most critical LLM-specific security risks, including prompt injection, sensitive information disclosure, improper output handling, excessive agency, system prompt leakage, vector and embedding weaknesses, and unbounded consumption.
NIST. AI Risk Management Framework (AI RMF 1.0). January 26, 2023. https://www.nist.gov/itl/ai-risk-management-framework. Voluntary framework for incorporating trustworthiness into the design, development, use, and evaluation of AI systems.
NIST. Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (NIST-AI-600-1). July 26, 2024. https://www.nist.gov/itl/ai-risk-management-framework. Companion profile cataloging generative-AI-specific risks and suggested risk-management actions.
MITRE. ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems). https://atlas.mitre.org/. Knowledge base of adversary tactics and techniques targeting AI-enabled systems.
European Union. EU AI Act implementation timeline. Entered into force August 1, 2024. https://artificialintelligenceact.eu/implementation-timeline/. Phased application of obligations, with most high-risk AI system requirements applying from August 2, 2026.


