Yes. Code written by AI assistants such as GitHub Copilot and Cursor needs a penetration test, and the reason is mechanical rather than anecdotal. Veracode's 2025 GenAI Code Security Report tested more than 100 large language models across Java, Python, C#, and JavaScript and found that 45% of AI-generated code samples introduced an OWASP Top 10 vulnerability. That failure rate did not fall as the models got larger or newer. This post explains the durable mechanism behind that number, the specific bug classes AI-assisted code reliably produces, and the testing and pull-request workflow that catches them before they ship.
The short version: large language models are next-token predictors. They are extraordinary at reproducing the shape of working code and weak at the properties that only exist across the whole application, which is exactly where the dangerous security bugs live.
The direct answer, up front
Any team shipping a meaningful volume of AI-assisted code should treat that code as untested until it has been through adversarial testing of the running application. Static review by the same developers who accepted the AI suggestion is not sufficient, because the failures are not typos. They are missing whole-application logic that no single diff makes visible. A penetration test exercises the deployed app the way an attacker would, chaining requests and abusing state to find the authorization and business-logic gaps that code review consistently misses.
This is not a claim that AI coding tools are bad or that you should stop using them. It is a claim that AI shifts where risk concentrates. When AI writes the majority of a feature, the human's job moves from authoring to reviewing, and humans are demonstrably worse at catching security flaws in code they did not write. A Stanford study by Perry, Srivastava, Kumar, and Boneh, published at ACM CCS 2023, found that participants with access to an AI coding assistant wrote significantly less secure code, and were more likely to believe their code was secure. That combination, more vulnerabilities plus more confidence, is the risk a pentest exists to counter.
Why LLMs reliably emit insecure code
The failure is not random, and understanding the mechanism is what tells you where to point a test. There are four reinforcing reasons a next-token predictor produces insecure application code.
1. Security lives outside the local context window
An LLM generates code from the tokens immediately around the cursor: the current function, the open file, maybe a few retrieved snippets. But authorization is not a local property. Whether a request should be allowed depends on the authenticated user, their tenant, their role, and the ownership of the specific object being touched. None of that is visible in the body of a getInvoice(id) function. So the model writes a correct-looking database lookup by ID and simply does not emit the ownership check, because nothing in the local context demanded one. The code compiles, returns the right shape, and passes the happy-path test. It is also a textbook Insecure Direct Object Reference (IDOR).
2. The training data is full of insecure patterns
Models learn from vast corpora of public code, tutorials, and forum answers, and a large fraction of that material is insecure by construction. Tutorials disable CSRF protection to keep the example short. Sample code hardcodes an API key so the snippet runs. Stack answers concatenate a string into a SQL query because that is the shortest way to demonstrate the point. The model has no way to know these were pedagogical shortcuts, so it reproduces them as if they were production patterns. This is why the NYU Center for Cybersecurity study of Copilot (Pearce et al., 2021) found that roughly 40% of the 1,692 programs it generated across 89 scenarios contained exploitable weaknesses. The model is faithfully mirroring its training distribution, and its training distribution is not secure.
3. The objective is plausibility, not safety
The model is optimized to produce the most probable continuation, not the safest one. Safety is often the less common pattern in the data, so it is the less probable token. When the likely completion is a permissive CORS wildcard, an unauthenticated endpoint, or a default admin credential, that is what surfaces. Veracode's finding that failure rates held roughly steady across model generations follows directly: making the model a better next-token predictor does not change the objective it is optimizing, so it does not make the output safer.
4. Business logic has no textual signature to imitate
Injection and misconfiguration at least have recognizable shapes a model can sometimes get right. Business logic does not. Whether a user may apply two discount codes, refund more than they paid, or advance an order past a payment step is a rule specific to your domain that appears nowhere in the model's training data. The model can only produce a plausible flow, and a plausible flow is not a correct one. This is the class that generic scanners and code review both miss most often, because there is no pattern to match against.
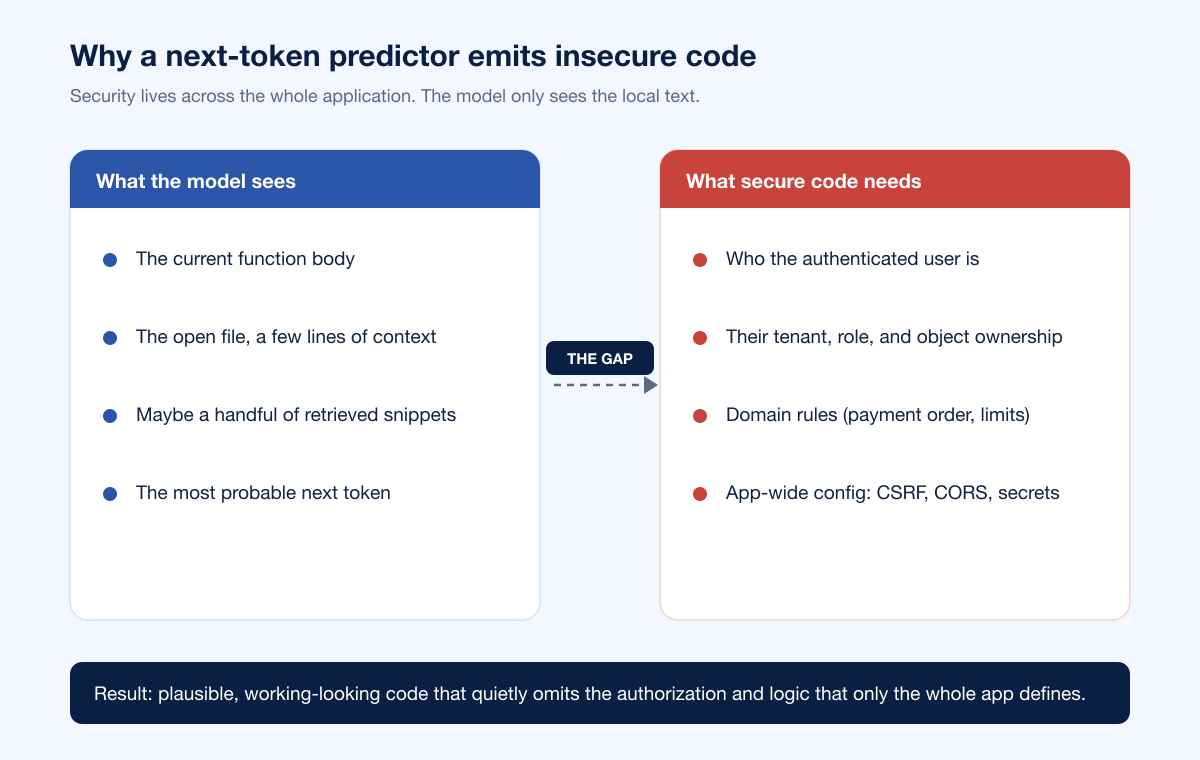
The through-line: every one of these failure modes is about properties that exist across the whole application rather than inside one function. That is precisely the seam between what a code assistant can see and what an application actually needs, and it is why the output needs to be tested against the running system, not just read.
The recurring failure modes in AI-coded apps
Testing AI-assisted web applications surfaces the same classes over and over. Here is what each one looks like and why the mechanism above produces it.
Broken authorization and IDOR
The single most common serious finding. The AI writes an endpoint that fetches or mutates a resource by identifier and never checks that the caller owns it. Change the ID in the request and you read or edit someone else's data. It happens because ownership is not in the local context, and it is invisible to happy-path tests that only ever use your own IDs.
Business-logic gaps
Multi-step flows that can be driven out of order or abused for value: skipping a payment step, replaying a one-time action, stacking discounts, or manipulating quantities to go negative. The model generated a plausible sequence of operations without enforcing the invariants that make the sequence safe.
Injection
SQL, NoSQL, command, and template injection still appear when the model concatenates untrusted input instead of parameterizing it, mirroring the insecure examples in its training data. Cross-Site Scripting is the standout: Veracode found AI tools failed to defend against XSS in 86% of the relevant samples they tested.
Hardcoded secrets and weak secret handling
API keys, database passwords, and signing secrets pasted directly into source, or logged in plaintext, because sample code does exactly that to stay runnable. These leak through source control history long after the literal string is removed.
Insecure defaults
CSRF protection disabled, permissive CORS wildcards, verbose error messages that leak stack traces, debug modes left on, and overly broad permissions. Each is the shortest path to "it works," so each is the most probable completion.
Missing rate limits and abuse controls
Login, password-reset, one-time-password, and expensive-query endpoints shipped without throttling, because rate limiting is orthogonal to the feature the developer asked for and never appears in the local prompt.

The state of the evidence, in one place
A small, dated snapshot of the public research so you can cite it and move on. Each figure comes from a named primary source with its methodology in the References section.
Finding | Figure | Source (year) |
|---|---|---|
AI-generated code samples introducing an OWASP Top 10 vulnerability | 45% | Veracode GenAI Code Security Report (2025) |
AI tools failing to defend against Cross-Site Scripting | 86% | Veracode GenAI Code Security Report (2025) |
Java the worst-performing language for secure AI output | 72% fail rate | Veracode GenAI Code Security Report (2025) |
Copilot-generated programs containing exploitable weaknesses | ~40% of 1,692 programs | NYU Center for Cybersecurity, Pearce et al. (2021) |
Users with an AI assistant wrote less secure code and felt more secure | Statistically significant | Stanford, Perry et al., ACM CCS (2023) |
The numbers move year to year and model to model. The mechanism does not. Anchor your program on the mechanism.
What a penetration test has to cover for AI-coded apps
A pentest for AI-assisted software is not a different discipline, but it does need to weight its effort toward the classes AI reliably breaks. Concretely, coverage should include:
Object-level authorization across every resource. Enumerate identifiers and attempt cross-account and cross-tenant access on every endpoint that reads or writes a record. This is where IDOR lives.
Function-level and role authorization. Attempt privileged actions as a lower-privileged user, and access admin-only routes without the role.
Business-logic abuse. Drive multi-step flows out of order, replay one-time actions, and test value and quantity boundaries against the domain rules.
Injection across sinks. Test every input that reaches a query, a shell, a template, or the DOM, including the XSS surface that AI code fails most often.
Secret exposure. Look for hardcoded credentials in responses, client bundles, error output, logs, and source-control history.
Configuration and defaults. CSRF, CORS, security headers, error verbosity, and permission scope.
Abuse and rate limiting on authentication, reset, OTP, and expensive endpoints.
Two properties make this coverage credible. First, findings must be proven by exploitation, not just flagged by a signature, because the whole point is catching logic that no pattern matcher recognizes. Second, the highest-severity findings need senior human validation, because the classes that matter most here are the classes automated tools most often get wrong.
The remediation workflow: catch it before it merges
Testing the deployed app finds what already shipped. The higher-leverage move is to stop vulnerable AI output from merging in the first place, so the same testing power belongs at the pull request, not only at the annual assessment.
That is the exact job Stingrai's Snipe was built for. Snipe is an autonomous AI agent for web application penetration testing that is purpose-built to hunt the complex, high-impact classes covered above: IDOR, broken authorization, and business-logic flaws, not just the known-class bugs generic scanners cap out at. It is custom-trained on 6,000+ HackerOne Hacktivity disclosure reports and on skills distilled from years of Stingrai's human pentesters' methodology, so it encodes how senior testers actually find these bugs. That matters here because the same reasoning that lets Snipe find an authorization flaw is what lets it recognize one an AI assistant just introduced.
A practical loop for teams shipping AI-assisted code:
Developer prompts Copilot or Cursor and accepts a suggestion.
The pull request triggers a gating check. Snipe runs white-box source review plus black-box dynamic testing against a preview environment, focused on authorization, business logic, injection, secrets, and insecure defaults.
Vulnerable code is blocked from merging. Because Snipe can run as a PR-gating check, a broken-authorization change fails the check instead of reaching production.
Snipe opens an AutoFix pull request with the remediation, so the developer gets a concrete change to review rather than only a warning.
Senior pentesters validate the high-severity findings, and periodic full assessments and adversary simulation cover the multi-step abuse and chained exploits that a per-PR check is not scoped to reach.
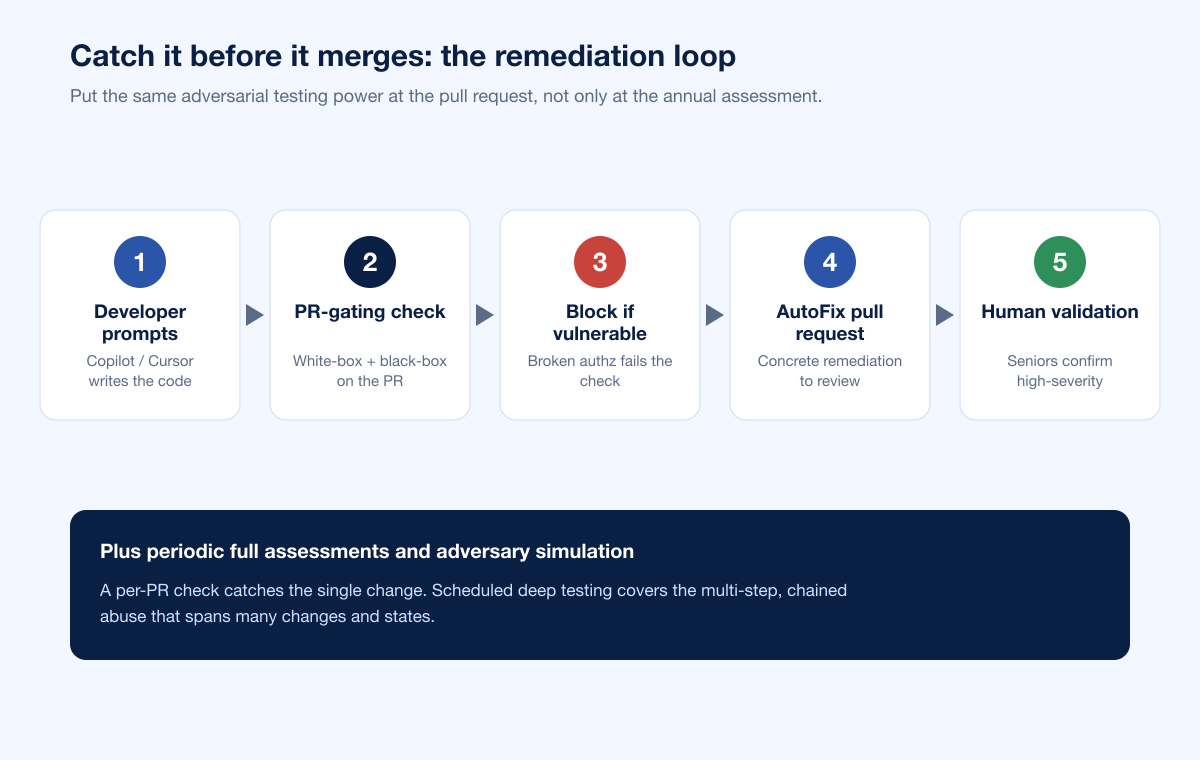
The shape of the fix mirrors the shape of the problem. AI introduced the risk by writing code faster than humans can securely review it, so the countermeasure has to be an equally fast, adversarial check that lives in the same pipeline and understands the same complex bug classes.
What this means for engineering and security leaders
Budget for testing the volume, not the headcount. If AI now writes a large share of your code, your review capacity has not scaled with your output. Adversarial testing is how you close that gap without hiring a reviewer for every prompt.
Point the test at authorization and business logic first. These are the highest-severity, lowest-detection classes in AI-coded apps. A test that only runs a scanner will miss exactly the bugs AI is most likely to introduce.
Move the check left, into the pull request. Gating merges on a security check that understands complex classes is cheaper than finding the same bug in production, and it is where AI-generated volume can be met with automated adversarial coverage. See how continuous PTaaS operationalizes this.
Keep senior humans on the high-severity findings. The hybrid is not about the AI being incapable; it is about a senior pentester confirming and extending the highest-impact findings before you act on them.
Track the mechanism, not the stat of the month. The percentages will keep changing. The reason LLMs emit insecure authorization and business logic will not, so build your program around it.
Frequently Asked Questions
Does code written by AI assistants like Copilot and Cursor need penetration testing?
Yes. Code from AI assistants needs penetration testing because large language models are next-token predictors that reliably omit whole-application security properties such as authorization, business-logic invariants, and secret handling. Veracode's 2025 GenAI Code Security Report found 45% of AI-generated code samples introduced an OWASP Top 10 vulnerability, a rate that did not improve with newer or larger models. A pentest exercises the running application to find the authorization and logic gaps that code review misses.
Why does AI-generated code have security vulnerabilities?
Because the model optimizes for the most plausible next token, not the safest one, and it learns from public code full of insecure shortcuts. Security properties like object ownership checks are not visible in the local function the model sees, and business logic specific to your domain appears nowhere in its training data, so the model produces plausible-but-unsafe output. The NYU Center for Cybersecurity found roughly 40% of Copilot-generated programs contained exploitable weaknesses.
What are the most common vulnerabilities in AI-coded applications?
Broken authorization and IDOR, business-logic gaps, injection (including Cross-Site Scripting, which AI tools failed to defend against in 86% of Veracode's relevant samples), hardcoded secrets, insecure defaults such as disabled CSRF or permissive CORS, and missing rate limits. All of them stem from the same mechanism: they are properties that live across the whole application rather than inside the single function the model was completing.
Can a code review or a scanner catch these instead of a pentest?
Only partially. Scanners match known signatures, so they catch some injection and misconfiguration but miss authorization and business-logic flaws that have no textual pattern. Human code review misses them too, and the Stanford CCS 2023 study found reviewers of AI-assisted code are more confident and less accurate. A penetration test proves findings by exploiting the running app, which is the only reliable way to surface logic-level bugs.
What is vibe coding and what are its security risks?
Vibe coding is building software by describing intent to an AI assistant and accepting its output with minimal manual authoring. Its security risk is that it maximizes exactly the conditions that produce insecure code: high volume of AI-authored logic, low human authorship, and high confidence in unreviewed output. The remediation is to gate merges on an adversarial security check and to pentest the running application for authorization and business-logic abuse.
How do you stop AI-generated vulnerabilities from reaching production?
Move an adversarial security check into the pull request so vulnerable code is blocked before it merges. Stingrai's Snipe can run as a PR-gating check that performs white-box source review and black-box testing focused on IDOR, broken authorization, and business logic, then opens an AutoFix pull request with the remediation. Senior pentesters validate the high-severity findings and periodic full assessments cover chained, multi-step abuse.
Is AI-generated code less secure than human-written code?
The published evidence points that way for security specifically. Veracode reported that AI-generated code carried materially higher vulnerability rates than a human baseline in its 2025 testing, and the Stanford CCS 2023 study found developers using an AI assistant wrote less secure code while believing it was more secure. The durable reason is that the model optimizes for plausibility, and secure authorization and logic are frequently the less probable completion.
Where can I get AI-coded applications penetration tested?
Stingrai is a CREST-accredited penetration testing provider whose Snipe agent is purpose-built for the complex classes AI code breaks on: IDOR, broken authorization, and business-logic flaws. Snipe runs black-box and white-box testing, opens AutoFix pull requests, and can gate pull requests so vulnerable AI output never merges, with senior pentesters validating high-severity findings. See the PTaaS overview or current pricing.
References
Veracode. 2025 GenAI Code Security Report. July 30, 2025. https://www.veracode.com/blog/genai-code-security-report/. Tested more than 100 large language models across Java, Python, C#, and JavaScript on 80+ coding tasks; found 45% of samples introduced an OWASP Top 10 vulnerability, with an 86% failure rate against Cross-Site Scripting and a 72% failure rate in Java.
NYU Center for Cybersecurity (Pearce, Ahmad, Tan, Dolan-Gavitt, Karri). Asleep at the Keyboard? Assessing the Security of GitHub Copilot's Code Contributions. 2021. https://cyber.nyu.edu/2021/10/15/ccs-researchers-find-github-copilot-generates-vulnerable-code-40-of-the-time/. Found approximately 40% of 1,692 programs generated by Copilot across 89 scenarios contained exploitable security weaknesses.
Perry, Srivastava, Kumar, Boneh (Stanford University). Do Users Write More Insecure Code with AI Assistants? ACM SIGSAC Conference on Computer and Communications Security (CCS), 2023. https://arxiv.org/abs/2211.03622. User study finding participants with access to an AI coding assistant wrote significantly less secure code and were more likely to believe their code was secure.